文章目录
- 17、说说new和malloc的区别,各自底层实现原理。
- 18、 说说const和define的区别。
- 19、 说说C++中函数指针和指针函数的区别?
- 20、 说说const int *a, int const *a, const int a, int *const a, const int *const a分别是什么,有什么特点。
- 21、说说使用指针需要注意什么?
- 22、说说内联函数和函数的区别,内联函数的作用?
- 23、 简述C++有几种传值方式,之间的区别是什么?
- 24、简述const(星号)和(星号)const的区别?
- 25、简述堆和栈的区别?
- 26、简述C++的内存管理?
- 27、常见的内存错误及其对策:
- 28、内存泄露及解决办法:
- 29、 malloc和局部变量分配在堆还是栈?
- 30、程序有哪些section,分别的作用?程序启动的过程?怎么判断数据分配在栈上还是堆上?
- 31、 初始化为0的全局变量在bss还是data?
- 32、简述C++中内存对齐的使用场景?
17、说说new和malloc的区别,各自底层实现原理。
- new是操作符,而malloc是函数。
- new在调用的时候先分配内存,在调用构造函数,释放的时候调用析构函数;而malloc没有构造函数和析构函数。
- malloc需要给定申请内存的大小,返回的指针需要强转;new会调用构造函数,不用指定内存的大
小,返回指针不用强转。 - new可以被重载;malloc不行
- new分配内存更直接和安全。
- new发生错误抛出异常,malloc返回null。
malloc底层实现:当开辟的空间小于 128K 时,调用 brk()函数;当开辟的空间大于 128K 时,调用mmap()。malloc采用的是内存池的管理方式,以减少内存碎片。先申请大块内存作为堆区,然后将堆区分为多个内存块。当用户申请内存时,直接从堆区分配一块合适的空闲快。采用隐式链表将所有空闲块,每一个空闲块记录了一个未分配的、连续的内存地址。
new底层实现:关键字new在调用构造函数的时候实际上进行了如下的几个步骤:
- 创建一个新的对象
- 将构造函数的作用域赋值给这个新的对象(因此this指向了这个新的对象)
- 执行构造函数中的代码(为这个新对象添加属性)
- 返回新对象

18、 说说const和define的区别。
const用于定义常量;而define用于定义宏,而宏也可以用于定义常量。都用于常量定义时,它们的区别
有:
- const生效于编译的阶段;define生效于预处理阶段。
- const定义的常量,在C语言中是存储在内存中、需要额外的内存空间的;define定义的常量,运行时是直接的操作数,并不会存放在内存中。
- const定义的常量是带类型的;define定义的常量不带类型。因此define定义的常量不利于类型检查。
19、 说说C++中函数指针和指针函数的区别?
- 定义不同
指针函数本质是一个函数,其返回值为指针。
函数指针本质是一个指针,其指向一个函数。 - 写法不同
指针函数:int *fun(int x,int y);
函数指针:int (*fun)(int x,int y);
20、 说说const int *a, int const *a, const int a, int *const a, const int *const a分别是什么,有什么特点。
1. const int a; //指的是a是一个常量,不允许修改。
2. const int *a; //a指针所指向的内存里的值不变,即(*a)不变
3. int const *a; //同const int *a;
4. int *const a; //a指针所指向的内存地址不变,即a不变
5. const int *const a; //都不变,即(*a)不变,a也不变
21、说说使用指针需要注意什么?
- 定义指针时,先初始化为NULL。
- 用malloc或new申请内存之后,应该立即检查指针值是否为NULL。防止使用指针值为NULL的内存。
- 不要忘记为数组和动态内存赋初值。防止将未被初始化的内存作为右值使用。
- 避免数字或指针的下标越界,特别要当心发生“多1”或者“少1”操作
- 动态内存的申请与释放必须配对,防止内存泄漏
- 用free或delete释放了内存之后,立即将指针设置为NULL,防止“野指针”。
22、说说内联函数和函数的区别,内联函数的作用?
- 内联函数比普通函数多了关键字inline。
- 内联函数避免了函数调用的开销;普通函数有调用的开销。
- 普通函数在被调用的时候,需要寻址(函数入口地址);内联函数不需要寻址。
- 内联函数有一定的限制,内联函数体要求代码简单,不能包含复杂的结构控制语句;普通函数没有这个要求。
内联函数的作用:内联函数在调用时,是将调用表达式用内联函数体来替换。避免函数调用的开销。
23、 简述C++有几种传值方式,之间的区别是什么?
传参方式有这三种:值传递、引用传递、指针传递
- 值传递:形参即使在函数体内值发生变化,也不会影响实参的值;
- 引用传递:形参在函数体内值发生变化,会影响实参的值;
- 指针传递:在指针指向没有发生改变的前提下,形参在函数体内值发生变化,会影响实参的值;
值传递用于对象时,整个对象会拷贝一个副本,这样效率低;而引用传递用于对象时,不发生拷贝行为,只是绑定对象,更高效;指针传递同理,但不如引用传递安全。
24、简述const(星号)和(星号)const的区别?
//const* 是指针常量,*const 是常量指针
int const *a; //a指针所指向的内存里的值不变,即(*a)不变,指针可变
int *const a; //a指针所指向的内存地址不变,即a不变,其所指内存值可变。
25、简述堆和栈的区别?
区别:
- 堆栈空间分配不同。栈由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等;堆一般由程序员分配释放。
- 堆栈缓存方式不同。栈使用的是一级缓存, 它们通常都是被调用时处于存储空间中,调用完毕立即释放;** **
- 堆栈数据结构不同。堆类似数组结构;栈类似栈结构,先进后出。
26、简述C++的内存管理?
- 内存分配方式:
在C++中,内存分成5个区,他们分别是堆、栈、自由存储区、全局/静态存储区和常量存储区。
- 栈,在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。
- 堆,就是那些由new分配的内存块,一般一个new就要对应一个delete。
- 自由存储区,就是那些由malloc等分配的内存块,和堆是十分相似的,不是用free来结束自己的生命。
- 全局/静态存储区,全局变量和静态变量被分配到同一块内存中
- 常量存储区,这是一块比较特殊的存储区,里面存放的是常量,不允许修改。
27、常见的内存错误及其对策:
错误:
(1)内存分配未成功,却使用了它。
(2)内存分配虽然成功,但是尚未初始化就引用它。
(3)内存分配成功并且已经初始化,但操作越过了内存的边界。
(4)忘记了释放内存,造成内存泄露。
(5)释放了内存却继续使用它。
对策:
(1)定义指针时,先初始化为NULL。
(2)用malloc或new申请内存之后,应该立即检查指针值是否为NULL。防止使用指针值为NULL
的内存。
(3)不要忘记为数组和动态内存赋初值。防止将未被初始化的内存作为右值使用。
(4)避免数字或指针的下标越界,特别要当心发生“多1”或者“少1”操作
(5)动态内存的申请与释放必须配对,防止内存泄漏
(6)用free或delete释放了内存之后,立即将指针设置为NULL,防止“野指针”。
(7)使用智能指针
28、内存泄露及解决办法:
- 什么是内存泄露?
简单地说就是申请了一块内存空间,使用完毕后没有释放掉。
(1)new和malloc申请资源使用后,没有用delete和free释放;
(2)子类继承父类时,父类析构函数不是虚函数。
(3)Windows句柄资源使用后没有释放。
怎么检测?
第一:良好的编码习惯,使用了内存分配的函数,一旦使用完毕,要记得使用其相应的函数释放掉。
第二:将分配的内存的指针以链表的形式自行管理,使用完毕之后从链表中删除,程序结束时可检查改链表。
第三:使用智能指针。
第四:一些常见的工具插件,如ccmalloc、Dmalloc、Leaky、Valgrind等等。
29、 malloc和局部变量分配在堆还是栈?
malloc是在堆上分配内存,需要程序员自己回收内存;
局部变量是在栈中分配内存,超过作用域就自动回收。
30、程序有哪些section,分别的作用?程序启动的过程?怎么判断数据分配在栈上还是堆上?
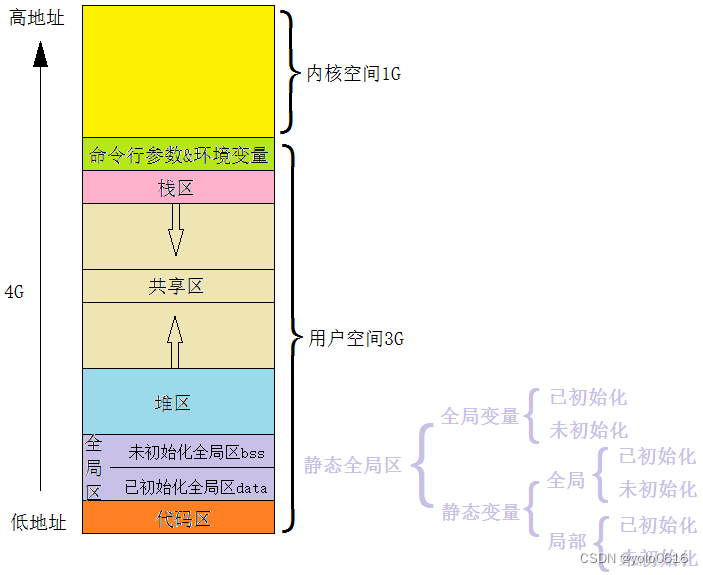
一个程序有哪些section:
如上图,从低地址到高地址,一个程序由代码段、数据段、 BSS 段组成。
- 数据段:存放程序中已初始化的全局变量和静态变量的一块内存区域。
- 代码段:存放程序执行代码的一块内存区域。只读,代码段的头部还会包含一些只读的常数变量。
- BSS 段:存放程序中未初始化的全局变量和静态变量的一块内存区域。
- 可执行程序在运行时又会多出两个区域:堆区和栈区。
堆区:动态申请内存用。堆从低地址向高地址增长。
栈区:存储局部变量、函数参数值。栈从高地址向低地址增长。是一块连续的空间。 - 最后还有一个文件映射区,位于堆和栈之间。
- 堆 heap :由new分配的内存块,其释放由程序员控制(一个new对应一个delete)
- 栈 stack :是那些编译器在需要时分配,在不需要时自动清除的存储区。存放局部变量、函数参数。
- 常量存储区 :存放常量,不允许修改。
程序启动的过程:
- 操作系统首先创建相应的进程并分配私有的进程空间,然后操作系统的加载器负责把可执行文件的数据段和代码段映射到进程的虚拟内存空间中。
- 加载器读入可执行程序的导入符号表,根据这些符号表可以查找出该可执行程序的所有依赖的动态链接库。
- 加载器针对该程序的每一个动态链接库调用LoadLibrary
(1)查找对应的动态库文件,加载器为该动态链接库确定一个合适的基地址。
(2)加载器读取该动态链接库的导入符号表和导出符号表,比较应用程序要求的导入符号是否匹配该库的导出符号。
(3)针对该库的导入符号表,查找对应的依赖的动态链接库,如有跳转,则跳到3
(4)调用该动态链接库的初始化函数。 - 初始化应用程序的全局变量,对于全局对象自动调用构造函数。
- 进入应用程序入口点函数开始执行。
怎么判断数据分配在栈上还是堆上:首先局部变量分配在栈上;而通过malloc和new申请的空间是在堆上。
31、 初始化为0的全局变量在bss还是data?
BSS段通常是指用来存放程序中未初始化的或者初始化为0的全局变量和静态变量的一块内存区域。特点是可读写的,在程序执行之前BSS段会自动清0。
32、简述C++中内存对齐的使用场景?
内存对齐应用于三种数据类型中:struct/class/union。
- struct/class/union内存对齐原则有四个:
- 数据成员对齐规则:结构(struct)或联合(union)的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小的整数倍开始。
- 结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部"最宽基本类型成员"的整数倍地址开始存储。(struct a里存有struct b,b里有char,int ,double等元素,那b应该从8的整数倍开始存储)。
- 收尾工作:结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的"最宽基本类型成员"的整数倍。不足的要补齐。(基本类型不包括struct/class/uinon)。
- sizeof(union),以结构里面size最大元素为union的size,因为在某一时刻,union只有一个成员真正存储于该地址。
- 什么是内存对齐?
- 那么什么是字节对齐?在C语言中,结构体是一种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构体、联合体等)的数据单元。在结构体中,编译器为结构体的每个成员按其自然边界(alignment)分配空间。各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构体的地址相同。
- 为了使CPU能够对变量进行快速的访问,变量的起始地址应该具有某些特性,即所谓的“对齐”,比如4字节的int型,其起始地址应该位于4字节的边界上,即起始地址能够被4整除,也即“对齐”跟数据在内存中的位置有关。如果一个变量的内存地址正好位于它长度的整数倍,他就被称做自然对齐。
- 为什么要字节对齐?
为了快速准确的访问,若没有字节对齐则会出现多次访问浪费时间。
举例说明(定义一个char 和 int型数据不按照字节对齐存储的情况需要多次访问)