译者注:
Embedding 直接翻译为嵌入似乎不太恰当,于是问了一下 ChatGPT,它的回复如下:
在自然语言处理和机器学习领域,"embeddings" 是指将单词、短语或文本转换成连续向量空间的过程。这个向量空间通常被称为嵌入空间(embedding space),而生成的向量则称为嵌入向量(embedding vector)或向量嵌入(vector embedding)。
嵌入向量可以捕获单词、短语或文本的语义信息,使得它们可以在数学上进行比较和计算。这种比较和计算在自然语言处理和机器学习中经常被用于各种任务,例如文本分类、语义搜索、词语相似性计算等。
在中文语境下,"embeddings" 通常被翻译为 "词向量" 或者 "向量表示"。这些翻译强调了嵌入向量的特点,即将词汇转换成向量,并表示为嵌入空间中的点。
在本文档中,Embedding 表示名词时大部多没有翻译直接用了英文,embedding vector 翻译为了“嵌入向量”,表示动词时翻译为了“向量表示”,翻译的比较仓促,如果有不恰当的地方,欢迎评论指正。
本篇文档翻译时间为 20230403,请注意时效性。
其他已翻译文档链接:
- IvyLee:OpenAI ChatGPT API 指南之 Chat Completion Beta 版
- IvyLee:OpenAI ChatGPT API 指南之语音转文字 Beta 版
- IvyLee:OpenAI ChatGPT API 文档之生产最佳实践
- IvyLee:OpenAI ChatGPT API 文档之 Embedding
- IvyLee:OpenAI ChatGPT API 文档之 Fine-tuning(微调)
什么是 Embedding?
OpenAI 中的文本 Embedding 衡量文本字符串之间的相关性。Embedding 通常用于以下场景:
- 搜索(结果按查询字符串的相关性进行排序)
- 聚类(将文本字符串按相似性分组)
- 推荐(推荐具有相关文本字符串的项目)
- 异常检测(识别相关性较小的异常值)
- 多样性测量(分析相似度分布)
- 分类(文本字符串按其最相似的标签进行分类)
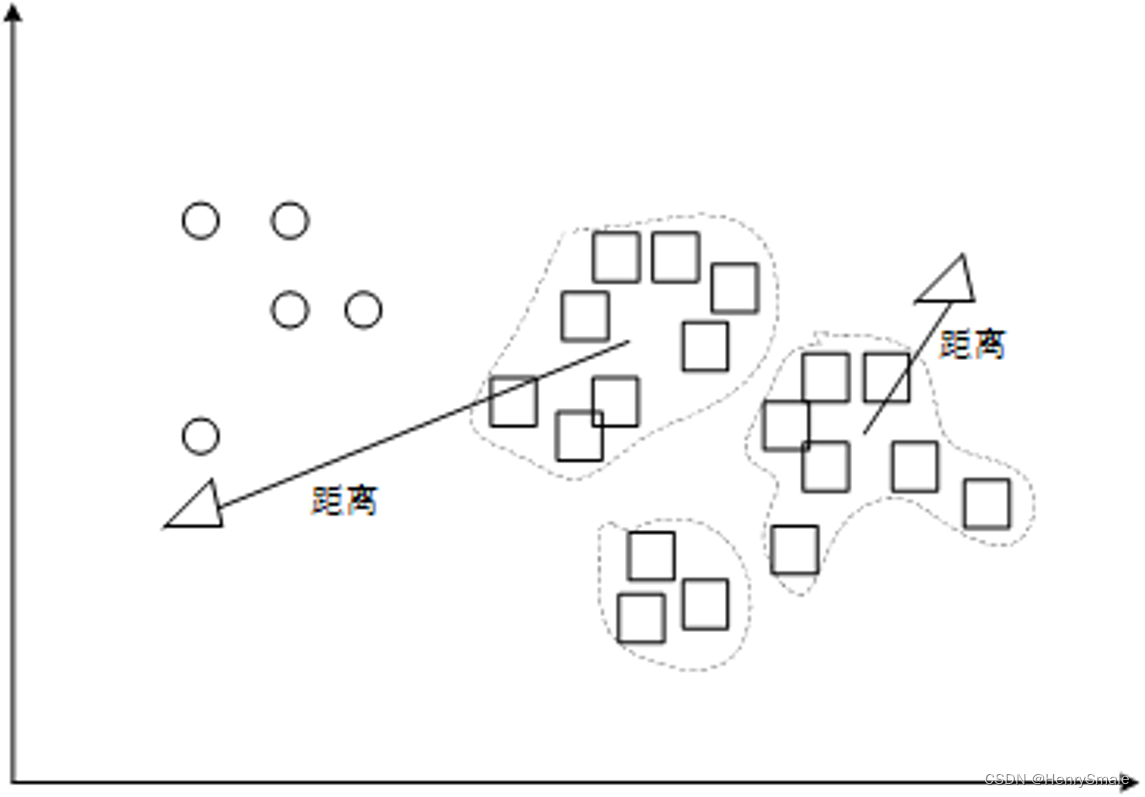
Embedding 是一个浮点数向量(列表)。两个向量之间的距离用于测量它们之间的相关性。较小距离表示高相关性,较大距离表示低相关性。
请访问我们的定价页面了解 Embedding 的定价。请求的计费基于发送的输入中的 token 数。
要了解 Embedding 的实际应用,请查看我们的代码示例(浏览示例)
- 分类
- 主题聚类
- 搜索
- 推荐
如何获取 Embedding
要获取 Embedding,将文本字符串和选定的 Embedding 模型 ID(例如 text-embedding-ada-002)发送到 Embedding API 端点。获得的响应中将包含一个 Embedding,你可以提取、保存和使用。
请求示例:
response = openai.Embedding.create(input="Your text string goes here",model="text-embedding-ada-002"
)
embeddings = response['data'][0]['embedding']响应示例:
{"data": [{"embedding": [-0.006929283495992422,-0.005336422007530928,...-4.547132266452536e-05,-0.024047505110502243],"index": 0,"object": "embedding"}],"model": "text-embedding-ada-002","object": "list","usage": {"prompt_tokens": 5,"total_tokens": 5}
}在 OpenAI Cookbook 中可以找到更多 Python 代码示例。
使用 OpenAI Embedding 时,请注意其限制和风险。
Embedding 模型
OpenAI 提供了一个第二代 Embedding 模型(在模型 ID 中标记为 -002)和 16 个第一代模型(在模型 ID 中标记为 -001)。
几乎所有用例我们都推荐使用 text-embedding-ada-002。这一模型更好、更便宜、更简单易用。相关信息可以阅读博客文章中的公告。
| 模型版本 | 分词器 | 最大输入 token 数 | 知识截断日期 |
|---|---|---|---|
| V2 | cl100k_base | 8191 | Sep 2021 |
| V1 | GPT-2/GPT-3 | 2046 | Aug 2020 |
按输入 token 计费,费率为每 1000 个 token 0.0004 美元,约为每美元 3000 页(假设每页约 800 个 token):
| 模型 | 每美元大约页数 | 在 BEIR 搜索评估中的示例性能 |
|---|---|---|
| text-embedding-ada-002 | 3000 | 53.9 |
| davinci-001 | 6 | 52.8 |
| curie-001 | 60 | 50.9 |
| babbage-001 | 240 | 50.4 |
| ada-001 | 300 | 49.0 |
第二代模型
| 模型名称 | 分词器 | 最大输入 token 数 | 输出维度 |
|---|---|---|---|
| text-embedding-ada-002 | cl100k_base | 8191 | 1536 |
第一代模型(不推荐使用)
所有第一代模型(以 -001 结尾的模型)均使用 GPT-3 分词器,最大输入为 2046 个 token。
第一代 Embedding 由五种不同的模型系列生成,针对三种不同的任务进行调整:文本搜索、文本相似度和代码搜索。其中搜索模型都有两个:一个用于短查询,一个用于长文档。每个系列包括不同质量和速度的四个模型:
| 模型 | 输出维度 |
|---|---|
| Ada | 1024 |
| Babbage | 2048 |
| Curie | 4096 |
| Davinci | 12288 |
Davinci 是能力最强的,但比起其他模型来,更慢更昂贵。Ada 能力最弱,但明显更快更便宜。
相似性模型
相似性模型最擅长捕捉文本之间的语义相似性。
| 使用场景 | 可用模型 |
|---|---|
| Clustering, regression, anomaly detection, visualization | text-similarity-ada-001 text-similarity-babbage-001 text-similarity-curie-001 text-similarity-davinci-001 |
文本搜索模型
文本搜索模型有助于衡量哪些长文档与短搜索查询最相关。使用两种模型:一种用于将搜索查询向量表示,另一种用于将要排序的文档向量表示。与查询 Embedding 最接近的文档 Embedding 应该是最相关的。
| 使用场景 | 可用模型 |
|---|---|
| Search, context relevance, information retrieval | text-search-ada-doc-001 text-search-ada-query-001 text-search-babbage-doc-001 text-search-babbage-query-001 text-search-curie-doc-001 text-search-curie-query-001 text-search-davinci-doc-001 text-search-davinci-query-001 |
代码搜索模型
与搜索模型一样,有两种类型:一种用于向量表示自然语言搜索查询,另一种用于向量表示代码片段以进行检索。
| 使用场景 | 可用模型 |
|---|---|
| Code search and relevance | code-search-ada-code-001 code-search-ada-text-001 code-search-babbage-code-001 code-search-babbage-text-001 |
对于-001文本 Embedding(不是-002,也不是代码 Embedding),建议将输入中的换行符(\n)替换为一个空格,因为我们发现存在换行符时,结果会更差。
使用场景
这里展示了一些典型的使用场景,我们将在以下示例中使用亚马逊美食评论数据集。
获取 Embedding
该数据集包含截至 2012 年 10 月,亚马逊用户留下的共计 568454 条食品评论。我们将使用最近的 1000 条评论作为示例。这些评论是用英文撰写的,倾向有积极有消极。每个评论都有一个产品 ID、用户 ID、评分(SCORE)、评论标题(SUMMARY)和评论正文(TEXT)。例如:
| PRODUCT ID | USER ID | SCORE | SUMMARY | TEXT |
|---|---|---|---|---|
| B001E4KFG0 | A3SGXH7AUHU8GW | 5 | Good Quality Dog Food | I have bought several of the Vitality canned... |
| B00813GRG4 | A1D87F6ZCVE5NK | 1 | Not as Advertised | Product arrived labeled as Jumbo Salted Peanut... |
我们把评论摘要和评论文本合并为一个组合文本。模型将对这一组合文本进行编码,输出一个向量 Embedding。
Obtain_dataset.ipynb
def get_embedding(text, model="text-embedding-ada-002"):text = text.replace("\\n", " ")return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']df['ada_embedding'] = df.combined.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
df.to_csv('output/embedded_1k_reviews.csv', index=False)要从已保存的文件中加载数据,可以运行以下命令:
import pandas as pddf = pd.read_csv('output/embedded_1k_reviews.csv')
df['ada_embedding'] = df.ada_embedding.apply(eval).apply(np.array)二维数据可视化
Visualizing_embeddings_in_2D.ipynb
Embedding 的大小随着底层模型的复杂性而变化。为了可视化这些高维数据,我们使用 t-SNE 算法将数据转换为二维数据。
根据评价者所给出的星级评分来给评论着色:
- 1星:红色
- 2星:橙色
- 3星:金色
- 4星:青绿色
- 5星:深绿色

可视化似乎产生了大约 3 个集群,其中一个集群的大部分都是负面评论。
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import matplotlibdf = pd.read_csv('output/embedded_1k_reviews.csv')
matrix = df.ada_embedding.apply(eval).to_list()# Create a t-SNE model and transform the data
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)colors = ["red", "darkorange", "gold", "turquiose", "darkgreen"]
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
color_indices = df.Score.values - 1colormap = matplotlib.colors.ListedColormap(colors)
plt.scatter(x, y, c=color_indices, cmap=colormap, alpha=0.3)
plt.title("Amazon ratings visualized in language using t-SNE")将 Embedding 用作 ML 算法的文本特征编码器
Regression_using_embeddings.ipynb
Embedding 可以被用作机器学习模型中的通用自由文本特征编码器。如果一些相关输入是自由文本,将 Embedding 加入模型会提高机器学习模型的性能。Embedding 也可以被用作机器学习模型中的分类特征编码器。如果分类变量的名称有意义且数量众多,比如“工作职称”,这将会增加最大的价值。相似性 Embedding 通常比搜索 Embedding 在这个任务上表现更好。
我们观察到向量表示通常都非常丰富和信息密集。使用 SVD 或 PCA 将输入的维度降低 10%,通常会导致特定任务的下游性能变差。
这段代码将数据分为训练集和测试集,将用于以下两个案例,即回归和分类。
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(list(df.ada_embedding.values),df.Score,test_size = 0.2,random_state=42
)使用 Embedding 特征进行回归
Embedding 提供了一种优雅的方法来预测数值。在这个例子中,我们基于评论文本预测评论者的星级评分。由于 Embedding 内包含的语义信息很高,即使只有很少的评论,预测结果也很不错。
我们假设分数是在 1 到 5 之间的连续变量,允许算法预测浮点数值。机器学习算法通过最小化预测值与真实分数之间的距离,实现了平均绝对误差为 0.39,这意味着还不到半个星级。
from sklearn.ensemble import RandomForestRegressorrfr = RandomForestRegressor(n_estimators=100)
rfr.fit(X_train, y_train)
preds = rfr.predict(X_test)使用 Embedding 特征进行分类
使用 Embedding 进行分类.ipynb
这次,不是让算法预测 1 到 5 之间的任意值,而是尝试将评价的精确星级分类为 5 个 bucket,从 1 星到 5 星。
经过训练后,模型可以学习到更好地预测 1 星和 5 星的评论,因为这两者情感表达更加极端,对于情感比较微妙的评论(2-4 星),可能学习效果较差。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_scoreclf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)零样本分类
使用 Embedding 进行零样本分类.ipynb
我们可以使用 Embedding 进行零样本分类,无需任何标记的训练数据。对于每个类别,我们将类别名称或类别的简短描述进行向量表示。要以零样本的方式对一些新文本进行分类,只需要将新文本的 Embedding 与所有类别 Embedding 进行比较,预测具有最高相似度的类别。
from openai.embeddings_utils import cosine_similarity, get_embeddingdf= df[df.Score!=3]
df['sentiment'] = df.Score.replace({1:'negative', 2:'negative', 4:'positive', 5:'positive'})labels = ['negative', 'positive']
label_embeddings = [get_embedding(label, model=model) for label in labels]def label_score(review_embedding, label_embeddings):return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])prediction = 'positive' if label_score('Sample Review', label_embeddings) > 0 else 'negative'获取用户和产品的 Embedding 用于冷启动推荐
User_and_product_embeddings.ipynb
可以通过对某一用户的所有评论进行平均来获得该用户的 Embedding,通过对有关某产品的所有评论进行平均来获得该产品的 Embedding。为了展示这种方法的实用性,我们使用了包含 50k 个评论的子集以覆盖更多用户和产品的评论。
我们在单独的测试集上评估这些 Embedding 的有用性,将用户和产品 Embedding 的相似性绘制为评分的函数。有趣的是,基于这种方法,在用户收到产品之前,我们就可以预测他们是否会喜欢该产品,获得比随机预测更好的结果。

user_embeddings = df.groupby('UserId').ada_embedding.apply(np.mean)
prod_embeddings = df.groupby('ProductId').ada_embedding.apply(np.mean)聚类
聚类.ipynb
聚类是理解大量文本数据的一种方法。Embedding 对于此任务很有用,因为它们提供每个文本的语义有意义的向量表示。因此,在无监督的方式下,聚类将揭示数据集中的隐藏分组。
在此示例中,我们发现四个不同的聚类:一个关注狗粮,一个关注负面评论,两个关注正面评论。

import numpy as np
from sklearn.cluster import KMeansmatrix = np.vstack(df.ada_embedding.values)
n_clusters = 4kmeans = KMeans(n_clusters = n_clusters, init='k-means++', random_state=42)
kmeans.fit(matrix)
df['Cluster'] = kmeans.labels_使用 Embedding 进行文本搜索
使用 Embedding 进行语义文本搜索.ipynb
为了检索出最相关的文档,我们使用查询嵌入向量和文档嵌入向量之间的余弦相似度,返回得分最高的文档。
from openai.embeddings_utils import get_embedding, cosine_similaritydef search_reviews(df, product_description, n=3, pprint=True):embedding = get_embedding(product_description, model='text-embedding-ada-002')df['similarities'] = df.ada_embedding.apply(lambda x: cosine_similarity(x, embedding))res = df.sort_values('similarities', ascending=False).head(n)return resres = search_reviews(df, 'delicious beans', n=3)使用 Embedding 代码搜索
Code_search.ipynb
代码搜索类似于基于 Embedding 的文本搜索。我们提供了一种从给定代码库的所有 Python 文件中提取 Python 函数的方法。然后每个函数都通过 text-embedding-ada-002 模型进行索引。
为了执行代码搜索,我们使用相同的模型以自然语言将查询进行向量表示。然后,计算查询结果 Embedding 和每个函数 Embedding 之间的余弦相似度。余弦相似度最高的结果最相关。
from openai.embeddings_utils import get_embedding, cosine_similaritydf['code_embedding'] = df['code'].apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))def search_functions(df, code_query, n=3, pprint=True, n_lines=7):embedding = get_embedding(code_query, model='text-embedding-ada-002')df['similarities'] = df.code_embedding.apply(lambda x: cosine_similarity(x, embedding))res = df.sort_values('similarities', ascending=False).head(n)return res
res = search_functions(df, 'Completions API tests', n=3)使用 Embedding 进行推荐
Recommendation_using_embeddings.ipynb
因为嵌入向量之间的距离越短,表示它们之间的相似性越大,所以 Embedding 可以用于推荐系统。
下面我们展示一个基本的推荐系统。它接受一个字符串列表和一个 source 字符串,计算它们的嵌入向量,然后返回一个排序列表,从最相似到最不相似。上面链接的 Notebook 文件中,应用了这个函数的一个版本来处理 AG 新闻数据集(采样到 2000 个新闻文章描述),返回与任何给定 source 文章最相似的前 5 篇文章。
def recommendations_from_strings(strings: List[str],index_of_source_string: int,model="text-embedding-ada-002",
) -> List[int]:"""Return nearest neighbors of a given string."""# get embeddings for all stringsembeddings = [embedding_from_string(string, model=model) for string in strings]# get the embedding of the source stringquery_embedding = embeddings[index_of_source_string]# get distances between the source embedding and other embeddings (function from embeddings_utils.py)distances = distances_from_embeddings(query_embedding, embeddings, distance_metric="cosine")# get indices of nearest neighbors (function from embeddings_utils.py)indices_of_nearest_neighbors = indices_of_nearest_neighbors_from_distances(distances)return indices_of_nearest_neighbors限制和风险
我们的 Embedding 模型在某些情况下可能不可靠或存在社会风险,并且在没有缓解措施的情况下可能会造成伤害。
社会偏见
限制:模型可能存在某些社会偏见,比如对某些群体的刻板印象或负面情绪。
我们通过运行 SEAT(May et al,2019)和 Winogender(Rudinger et al,2018)基准测试发现了模型存在偏见的证据。这些基准测试共包含 7 个,衡量模型在应用于性别化名称、国家和地区名称和一些刻板印象时是否包含隐含的偏见。
例如,我们发现我们的模型更强烈地将(a)欧洲裔美国人的名字与非洲裔美国人的名字相比,更容易与积极情感联系在一起,以及(b)将负面刻板印象与黑人女性联系在一起。
这些基准测试在多个方面存在限制:(a)它们可能不适用于你特定的使用场景,(b)它们只测试了可能的社会偏见的极小部分。
这些测试只是初步的,我们建议你运行针对自己特定用例的测试。这些结果应被视为该现象存在的证据,而不是针对你的用例的确定性描述。更多详细信息和指导,请参阅我们的使用政策。
如果你有任何问题,请通过聊天联系我们的支持团队。
缺乏对近期事件的认知
限制:模型缺乏对 2020 年 8 月之后发生事件的了解。
我们模型的训练数据,只包含 2020 年 8 月之前的现实世界事件信息。如果你依赖于表示近期事件的模型,那么我们的模型可能会表现欠佳。
常见问题
如何在 Embedding 之前知道一个字符串有多少个 token?
在 Python 中,你可以使用 OpenAI 的分词器 tiktoken 将字符串拆分为 token。
示例代码:
import tiktokendef num_tokens_from_string(string: str, encoding_name: str) -> int:"""Returns the number of tokens in a text string."""encoding = tiktoken.get_encoding(encoding_name)num_tokens = len(encoding.encode(string))return num_tokensnum_tokens_from_string("tiktoken is great!", "cl100k_base")对于像 text-embedding-ada-002 这样的第二代 Embedding 模型,请使用 cl100k_base 编码。
更多细节和示例代码在 OpenAI Cookbook 指南如何使用 tiktoken 计算 token 数中。
如何快速检索 K 个最近的嵌入向量?
为了快速搜索许多向量,我们建议使用向量数据库。你可以在 GitHub 上的 OpenAI Cookbook 中找到使用向量数据库和 OpenAI API 的示例。
向量数据库选项包括:
- Pinecone,完全托管的向量数据库
- Weaviate,开源向量搜索引擎
- Redis,向量数据库
- Qdrant,向量搜索引擎
- Milvus,用于可扩展相似性搜索的向量数据库
- Chroma,开源的嵌入向量存储
我应该使用哪种距离函数?
我们建议使用余弦相似度。距离函数的选择通常不太重要。
OpenAI Embedding 已标准化为长度 1,这意味着:
- 余弦相似度可以使用点积更快地计算
- 余弦相似度和欧几里得距离将产生相同的排名
我能在网上分享我的 Embedding 吗?
客户有模型输入和输出的所有权,对于 Embedding 也一样。你有责任确保你输入到 API 的内容不违反任何适用的法律或我们的《使用条款》。


![buuctf-[网鼎杯 2020 朱雀组]phpweb](https://img-blog.csdnimg.cn/51f9829751524b0fb1768ce7aaee5765.png)