经常有网友问到一个问题,我电脑开机后提示按f1怎么解决?不管理是台式电脑,还是笔记本,都有可能会遇到开机需要按F1,才能进入系统的问题,引起这个问题的原因比较多,今天小编在这里给大家列举了比较常见的几种电脑开机提示按f1的解决方法。
电脑开机提示按f1原因分析及解决方法:
电脑开机提示按f1原因一:主板上纽扣电池没电了
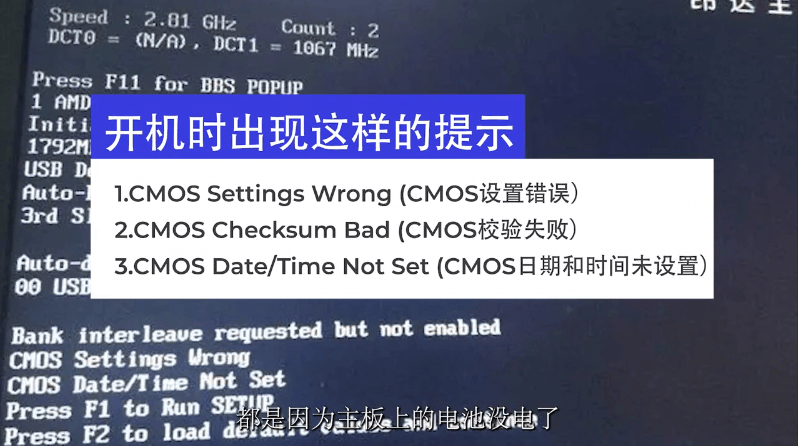
开机时出现这样的提示:
1)CMOS Settings Wrong (CMOS设置错误)
2)CMOS Checksum Bad (CMOS校验失败)
3)CMOS Date/Time Not Set (CMOS日期和时间未设置)
电脑的日期和时间不对,无论您怎么修改日期时间,电脑重启之后,时间又被自动修改。
电脑开机提示按f1原因一解决方法:
1、打开电脑机箱,更换同型号CMOS电池 (纽扣电池),如下图所示;

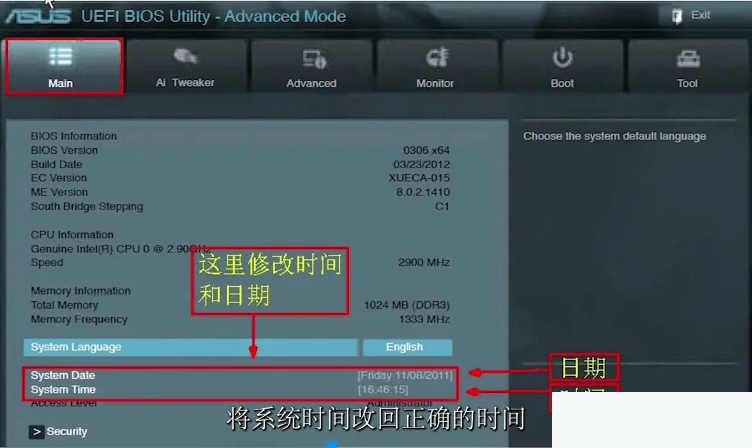
2、进入BIOS,将系统时间改回正确的时间,再按F10,保存并退出就可以了;
电脑开机提示按f1原因二:CPU散热器供电线连接错误
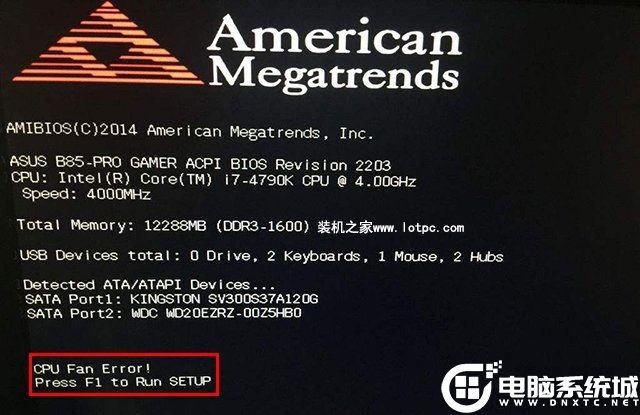
开机时出现这样的提示:
1)CPU Fan Error (CPU风扇出错)
电脑开机提示按f1原因二解决方法:将CPU散热器供电线连接到主板上CPU-FAN插座上,你可能连接的是机箱风扇的插座上,例如SYS_FAN、CHA_FAN。此外,不排除CPU风扇可能停转了,或者你没有插上供电线或接口接触不良导致这个问题。
电脑开机提示按f1原因三:USB设备出现问题
开机时出现这样的提示:USB设备出现问题,开机提示:“USB mass storage device found and configured ”(需要对发现的USB设备进行配置),提示按F1继续。
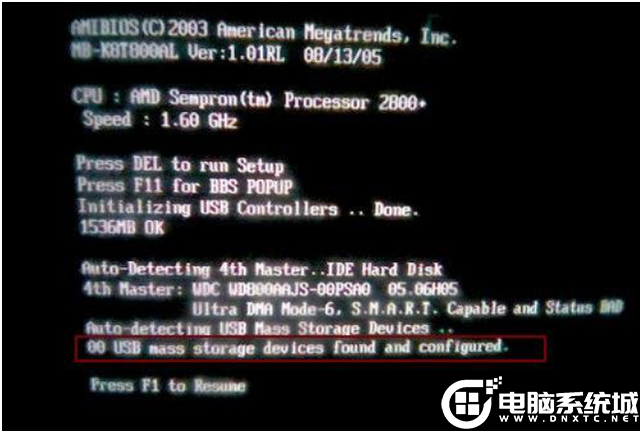
电脑开机提示按f1原因三解决方法:这说明在开机前就已经插上U盘了,出现这种情况时最好将U盘拔掉后在开启电脑便可以解决。
电脑开机提示按f1原因四:开启了内存的XMP
电脑开机后提示the system has posted in safe mode的错误,the system has posted in safe mode=系统在安全模式,该提示主要原因是开启了内存的XMP。
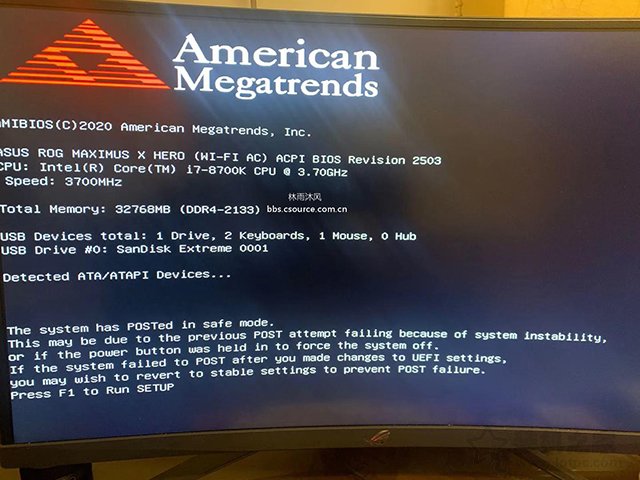
电脑开机提示按f1原因四解决方法:最后逐一排查,发现只要在关闭了内存的XMP,同时将内存的频率调回正常后,就可以正常开机,不再有the system has posted in safe mode的报错了,我估计这是华硕主板BIOS有点小问题,后期可能华硕更新BIOS中会解决这个问题,消费者更新最新主板BIOS应该可以解决掉这个问题。
电脑开机提示按f1原因五:BIOS设置不当
一般情况下,电脑正常第一启动项是硬盘,如果主板BIOS中设置了U盘或者光驱启动,有可能会造成开机要按F1键,或者双硬盘的情况下,没有设置主硬盘为第一启动项。解决方法:进入BIOS,设置主硬盘为第一启动项即可。
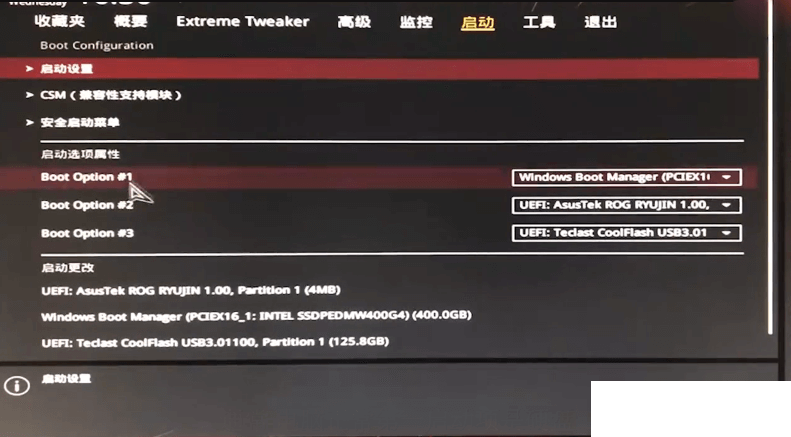
如果按以上方法操作后还是会提示按f1,我们可以直接在bios关闭f1提示(当然正常情况下一般会出现才会提示按f1)
电脑开机提示按f1原因六:硬盘故障
有些时候硬盘出现问题的话,开机也会提示按f1键。例如提示为“3rd Master HardDisk:S.M.A.R.T. Status BAD Backup and Replace”,它的意思是说系统检测到电脑的第三硬盘损坏,建议你及时备份重要数据。
这电脑开机提示按f1终极解决方法:bios中关闭f1提示
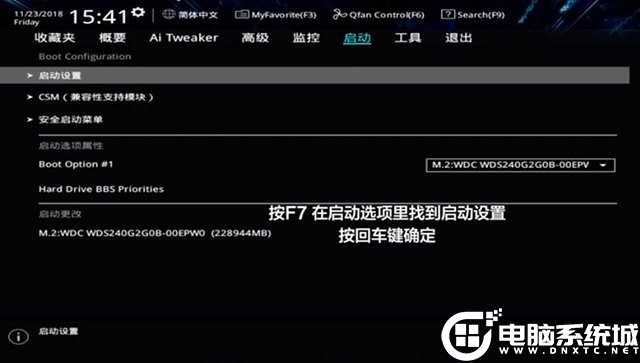
1、电脑开机之后,反复按下“DEL”键,进入主板BIOS设置中,按下F7键进入“Advnced Mode”(高级模式),如下图所示;
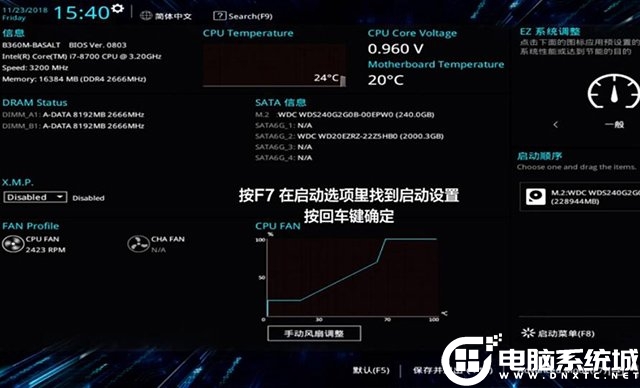
2、我们找到启动选项卡(BOOT),进入启动设置选项中,如下图所示;
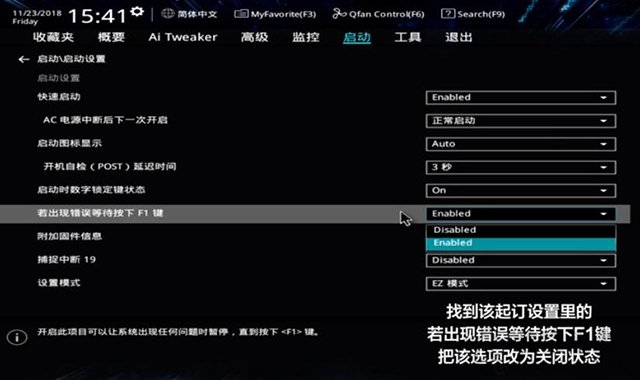
3、找到“若出现错误等待按下F1键”并选择下拉,我们将默认的"enabled"改成“Disabled”,其意思关闭开机f1提示,如下图所示;
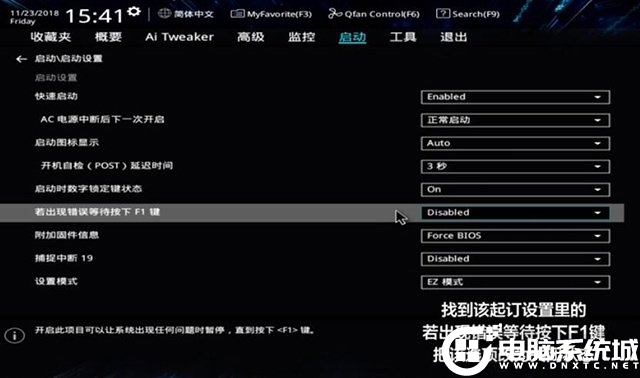
5、修改后我我们按下F10键保存并退出BIOS即可。
以上就是电脑开机提示按f1原因分析及解决方法,
如果这篇文章能帮助您,希望您关注电脑教程网。如果您遇到电脑安装系统相关问题:u盘进入pe找不到硬盘、u盘安装系统蓝屏、u盘安装系统后无法进入系统、硬盘分区、安装系统引导修复相关问题,都可以采用“小兵pe”解决,同时小兵pe还支持安装原版win7一键注入usb3.x、nvme等驱动,也支持安装原版win10或win11系统一键注入rst、vmd、raid驱动。










![[Meet DeepSeek] 如何顺畅使用DeepSeek?告别【服务器繁忙,请稍后再试。】](https://i-blog.csdnimg.cn/direct/ea26318ffca14685ae5ce1ed0a748fce.jpeg#pic_center)