服务器数据恢复环境:
一台服务器共配备32块硬盘,组建了4组RAIDZ,Windows操作系统+zfs文件系统。
服务器故障:
服务器在运行过程中突然崩溃,经过初步检测检测没有发现服务器存在物理故障,重启服务器后故障依旧,需要恢复服务器内的大量数据。
经过北亚企安数据恢复工程师的初步检测,发现故障服务器中4组raidz里有两组raidz中的热备盘启动。其中第一组raidz启用了一块热备盘,之后又有一块硬盘掉线;第二组raidz第一块磁盘离线后又有2块硬盘掉线,总共启用了三块热备盘。
这两组raidz中硬盘离线后均启用了热备盘替换坏盘,热备盘上线后这2组raidz中又出现其他硬盘离线的情况。为了得到正确数据,zpool在每次读取数据时都会进行校验。第二组raidz热备盘上线后又有硬盘离线,服务器彻底崩溃。
服务器数据恢复过程:
1、将故障服务器中所有磁盘编号后取出,以只读方式将所有磁盘做全盘镜像,镜像完成后将所有磁盘按照编号还原到原服务器中,后续的数据分析和数据恢复操作都基于镜像文件进行,避免对原始磁盘数据造成二次破坏。
2、ZFS管理的存储池与常规RAID不同。常规RAID在存储数据时会按照特定的规则组建存储池,并不考虑文件在子设备上的位置;而ZFS在存储数据时会为每次写入的数据分配适当大小的空间,通过计算获取指向子设备的数据指针。ZFS的这种特性让RAIDZ在缺盘时无法直接进行校验得到数据,必须将整个ZPOOL作为一个整体进行解析。
3、手工截取事务块数据,北亚企安数据恢复工程师编写程序获取最大事务号入口。
获取文件系统入口: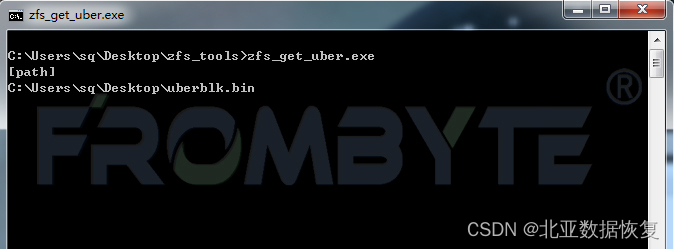
4、获取到文件系统入口后,北亚企安数据恢复工程师编写数据指针解析程序进行地址解析。
解析数据指针:
5、获取到文件系统入口点在各磁盘分布情况后,数据恢复工程师手工截取&分析文件系统内部结构。入口分布所在的磁盘组无缺失盘,可直接提取信息。根据ZFS文件系统的数据存储结构顺利找到映射的LUN名称,进而找到其节点。
6、由于在此ZFS版本与开源版本有较大差别,无法使用原先开发的解析程序进行解析,所以数据恢复工程师只能重新编写数据提取程序。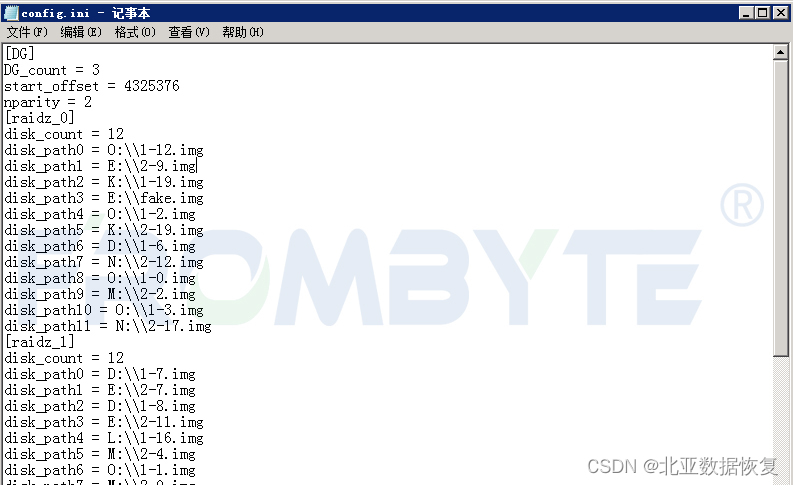
7、由于磁盘组内缺盘个数较多,每个IO流都需要通过校验得到,提取进度极为缓慢。与用户方沟通后得知此ZVOL卷映射到XenServer作为存储设备,用户需的文件在其中一个大小约为2T的vhd内。提取ZVOL卷头部信息,按照XenStore卷存储结构进行分析,发现2T vhd在整个卷的尾部,计算得到其起始位置,从起始位置开始提取数据。
8、Vhd提取完毕后,对其内部的压缩包、图片、视频等文件进行验证,均可正常打开。
9、用户发经过验证后,确定恢复出来的文件数量与系统自动记录的文件数量差不多,极小部分丢失的文件可能是由于这些文件是新生成的还未刷新到磁盘。用户验证文件的可用性,文件全部可正常打开,本次数据恢复工作完成。





![[红明谷CTF 2021]write_shell %09绕过过滤空格 ``执行](https://img-blog.csdnimg.cn/d4689eed5afe4de4a687cd0cd2eb865d.png)