作者:Lalit Satapathy, Ishleen Kaur, Muthukumar Paramasivam

Elastic® SQL 输入(metricbeat 模块和输入包)允许用户以灵活的方式对许多支持的数据库执行 SQL 查询,并将结果指标提取到 Elasticsearch®。 本博客深入探讨了通用 SQL 的功能,并为高级用户提供了各种用例,以将自定义指标引入 Elastic®,以实现数据库可观察性。 该博客还介绍了 8.10 中发布的从所有数据库中获取新功能。
为什么是“通用 SQL”?
Elastic 已经拥有针对特定数据库的 metricbeat 和集成包。 一个例子是 MySQL 的 metricbeat — 以及相应的集成包。 这些 beats 模块和集成是针对特定数据库定制的,并且使用预定义的查询从特定数据库中提取指标。 这些集成中使用的查询和相应的指标不可修改。
而通用 SQL 输入(metricbeat 或输入包)可用于使用用户的 SQL 查询从任何支持的数据库中抓取指标。 用户根据要提取的特定指标来提供查询。 这为指标摄取提供了一种更强大的机制,用户可以选择特定的驱动程序并提供相关的 SQL 查询,然后使用结构化映射过程(稍后解释表/变量格式)将结果映射到一个或多个 Elasticsearch 文档。
通用 SQL 输入可以与已提取特定数据库指标的现有集成包结合使用,以动态提取其他自定义指标,从而使此输入非常强大。 在本博客中,通用 SQL 输入 (Generic SQL input) 和通用 SQL (Generic SQL) 可以互换使用。

功能详情
本节介绍一些有助于指标提取的功能。 我们提供响应格式配置的简要说明。 然后我们深入研究 merge_results 功能,该功能用于将多个 SQL 查询的结果合并到单个文档中。
用户可能感兴趣的下一个关键功能是从所有自定义数据库收集指标,现在可以通过 fetch_from_all_databases 功能实现这一点。
现在让我们深入了解具体功能:
支持不同的驱动程序
通用 SQL 可以从不同的数据库获取指标。 当前版本能够从以下驱动程序获取指标:MySQL、PostgreSQL、Oracle 和 Microsoft SQL Server (MSSQL)。
响应格式
通用 SQL 中的响应格式用于操作表或变量格式的数据。 以下概述了创建和使用表和变量的格式和语法。
语法:response_format: table {{or}} variables
响应格式:表
此模式为每一行生成一个事件。 表格式对响应中的列数没有限制。 此格式可以有任意数量的列。
例子:
driver: "mssql"
sql_queries:- query: "SELECT counter_name, cntr_value FROM sys.dm_os_performance_counters WHERE counter_name= 'User Connections'"response_format: table此查询返回类似于以下内容的响应:
"sql":{"metrics":{"counter_name":"User Connections ","cntr_value":7},"driver":"mssql"
}上面生成的响应将 counter_name 添加为文档中的键。
响应格式:变量
变量格式支持键:值对。 此格式要求在查询中仅获取两列。
例子:
driver: "mssql"
sql_queries:- query: "SELECT counter_name, cntr_value FROM sys.dm_os_performance_counters WHERE counter_name= 'User Connections'"response_format: variables变量格式以上面查询中的第一个变量作为键:
"sql":{"metrics":{"user connections ":7},"driver":"mssql"
}在上面的响应中,你可以看到 counter_name 的值用于生成可变格式的密钥。
响应优化:merge_results
我们现在支持将多个查询响应合并到一个事件中。 通过启用 merge_results,用户可以显着优化摄取到 Elasticsearch 的指标的存储空间。 此模式可以有效压缩生成的文档,而不是生成多个文档,而是在适用的情况下生成单个合并文档。 从多个查询生成的类似类型的指标被组合到单个事件中。

语法:merge_results: true {{or}} false
在下面的示例中,你可以看到当 merge_results 被禁用时,数据如何加载到 Elasticsearch 中以进行以下查询。
例子:
在此示例中,我们使用两个不同的查询从性能 counter 获取指标。
merge_results: false
driver: "mssql"
sql_queries:- query: "SELECT cntr_value As 'user_connections' FROM sys.dm_os_performance_counters WHERE counter_name= 'User Connections'"response_format: table- query: "SELECT cntr_value As 'buffer_cache_hit_ratio' FROM sys.dm_os_performance_counters WHERE counter_name = 'Buffer cache hit ratio' AND object_name like '%Buffer Manager%'"response_format: table
正如你所看到的,上面示例的响应为每个查询生成一个文档。
第一个查询的结果文档:
"sql":{"metrics":{"user_connections":7},"driver":"mssql"
}
第二个查询生成的文档:
"sql":{"metrics":{"buffer_cache_hit_ratio":87},"driver":"mssql"
}
当我们在查询中启用 merge_results 标志时,上述两个指标将组合在一起,并将数据加载到单个文档中。
你可以在下面的示例中看到合并后的文档:
"sql":{"metrics":{"user connections ":7,“buffer_cache_hit_ratio”:87},"driver":"mssql"
}然而,只有当表查询被合并并且每个查询生成一行时,这样的合并才是可能的。 对合并变量查询没有限制。
引入新功能:fetch_from_all_databases
这是一项新功能,通过启用 fetch_from_all_databases 标志,自动从 Microsoft SQL Server 的系统和用户数据库中获取所有数据库指标。
请密切关注 8.10 发行版本,你可以在其中开始使用获取所有数据库功能。 在 8.10 版本之前,用户必须手动提供数据库名称才能从自定义/用户数据库中获取指标。
语法: fetch_from_all_databases: true {{or}} false
以下是禁用 fetch_from_all_databases 标记的示例查询:
fetch_from_all_databases: false
driver: "mssql"
sql_queries:- query: "SELECT @@servername AS server_name, @@servicename AS instance_name, name As 'database_name', database_id FROM sys.databases WHERE name='master';"
上述查询仅获取所提供的数据库名称的指标。 这里的输入数据库是 master,因此仅获取 master 的指标。
以下是启用了 fetch_from_all_databases 标志的示例查询:
fetch_from_all_databases: true
driver: "mssql"
sql_queries:- query: SELECT @@servername AS server_name, @@servicename AS instance_name, DB_NAME() AS 'database_name', DB_ID() AS database_id;response_format: table
上述查询从所有可用数据库中获取指标。 当用户想要从所有数据库获取数据时,这非常有用。
请注意:目前仅 Microsoft SQL Server 支持此功能,并将由 MS SQL 集成在内部使用,以支持默认提取所有用户数据库的指标。
使用通用 SQL:Metricbeat
通用 SQL metricbeat 模块提供了针对不同数据库驱动程序执行查询的灵活性。 metricbeat 输入可作为任何生产用途的 GA。 在这里,你可以找到有关为不同驱动程序配置通用 SQL的更多信息以及各种示例。
使用通用 SQL:输入包
输入包为高级用户提供了灵活的解决方案,用于在 Elastic 中定制他们的摄取体验。 通用 SQL 现在也可作为 SQL 输入包使用。 输入包目前可作为测试版供早期用户使用。 让我们来看看用户如何通过输入包使用通用 SQL。
通用 SQL 输入包的配置:
通用 SQL 输入包的配置选项如下:
- Driver:这是你要使用该包的 SQL 数据库。 本例中,我们以 mysql 为例。
- Hosts:用户在此处输入连接字符串以连接到数据库。 它会根据所使用的数据库/驱动程序而有所不同。 请参阅此处的示例。
- SQL Queries:用户在此处编写他们想要触发的 SQL 查询并指定 response_format。
- Data set:用户指定响应字段映射到的数据集名称。
- 合并结果:这是一项高级设置,用于将查询合并到单个事件中。


通过自定义 SQL 查询实现指标可扩展性
假设用户正在使用 MYSQL Integration,它提供了一组固定的指标。 他们的要求现在扩展到通过触发新的自定义 SQL 查询从 MYSQL 数据库检索更多指标。
这可以通过添加 SQL 输入包的实例、编写自定义查询并指定新的 data set 名称来实现,如下面的屏幕截图所示。
这样用户就可以通过执行相应的查询来获取任何指标。 查询的结果指标将被索引到新数据集 sql_second_dataset。
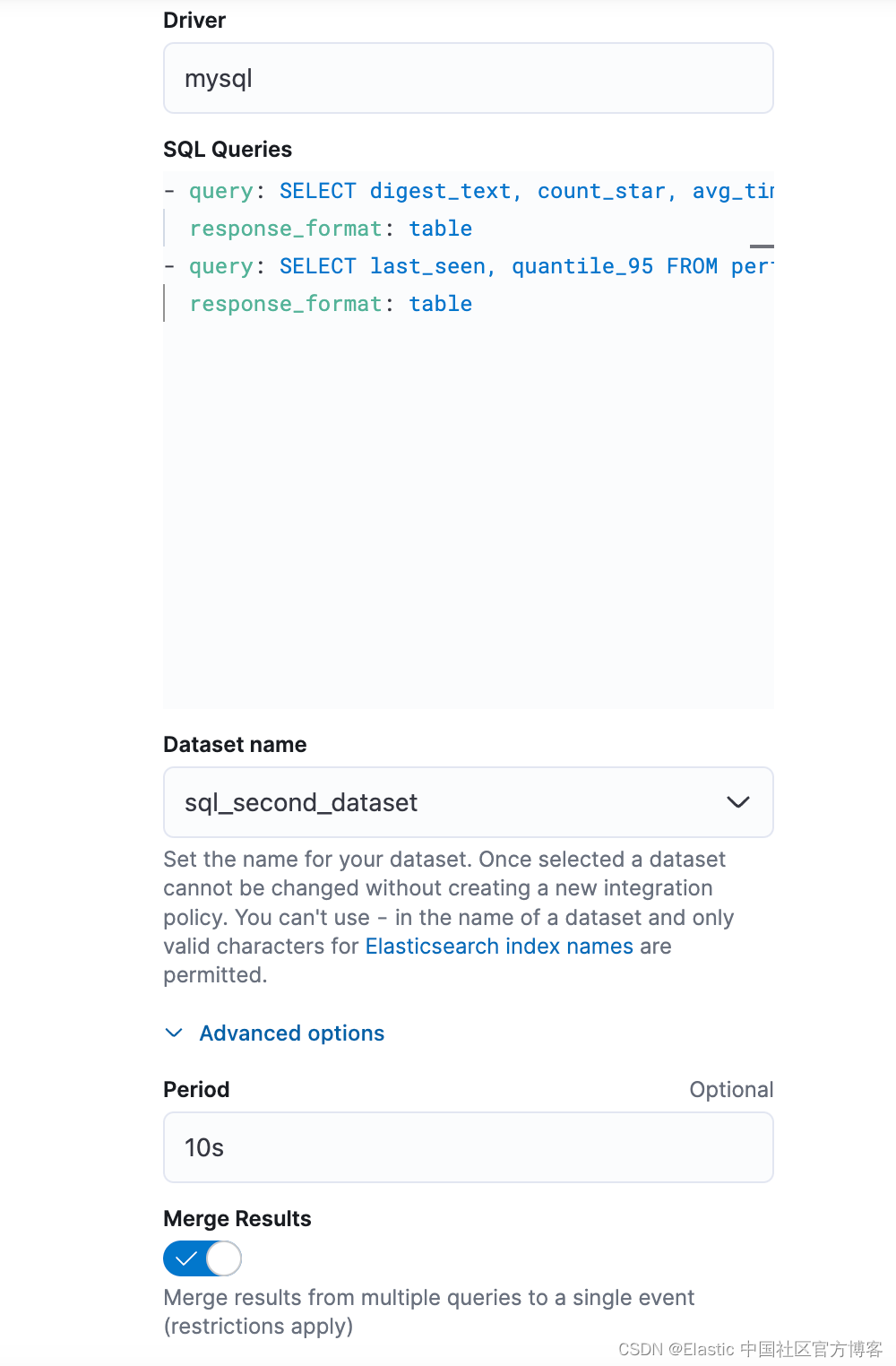
当存在多个查询时,用户可以通过启用 “Merge Result” 开关将它们组合到单个事件中。
定制用户体验
用户可以通过编写自己的摄取管道并提供自定义映射来自定义数据。 用户还可以构建自己的定制仪表板。
正如我们在上面所看到的,SQL 输入包提供了通过运行新查询来获取新指标的灵活性,这在默认的 MYSQL 集成中是不支持的(用户从一组预定的查询中获取指标)。
SQL 输入包还支持多种驱动程序:mssql、postgresql 和 oracle。 因此,可以使用单个输入包来满足所有这些数据库的需求。
注意:SQL 输入包尚不支持 fetch_from_all_databases 功能。
试试看!
现在你已经了解了通用 SQL 的各种用例和功能,开始使用 Elastic Cloud 并尝试为你的 SQL 数据库使用 SQL 输入包并获得定制的体验和指标。 如果你正在为我们现有的一些基于 SQL 的集成(例如 Microsoft SQL Server、Oracle 等)寻找更新的指标,请继续尝试 SQL 输入包。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。