面试问到Mysql模块划分与架构体系怎么办
文章目录
- 1. 应用层
- 连接管理器(Connection Manager)
- 安全性和权限模块(Security and Privilege Module)
- 2. MySQL服务器层
- 2.1. 服务支持和工具集
- 2.2. SQL Interface
- 2.3. 解析器
- 举个解析器 例子理解一下
- 2.4. 优化器
- 举个优化器 例子理解一下
- 2.5. 缓存
- 3. 存储引擎层
- 3.1. 可插拔的特性
- 3.2. 常见的MySQL存储引擎包括:
- 参考文档
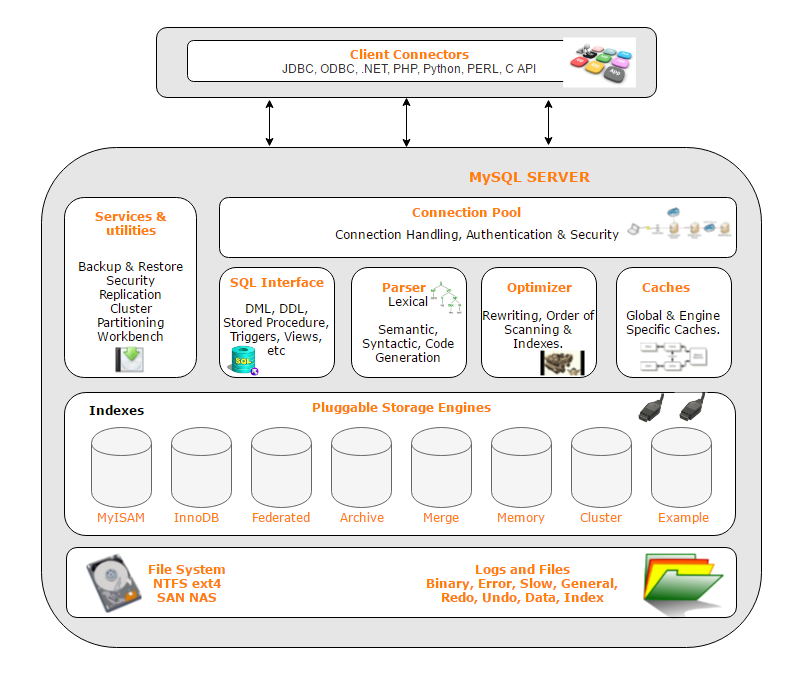
图片来源 https://www.rathishkumar.in/2016/04/understanding-mysql-architecture.html
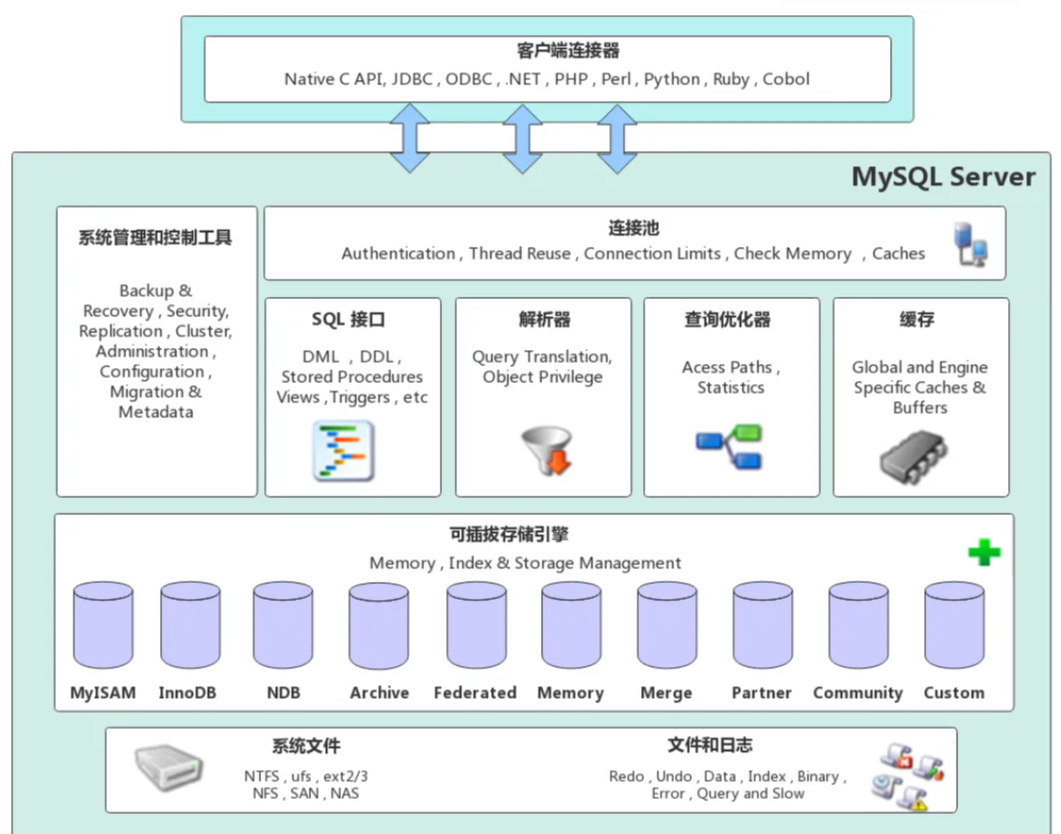
1. 应用层
这是MySQL架构中的最上层,有的文章里叫做网络接入层,可以在许多客户端 - 服务器架构中看到这个层。这一层包括一些大多数客户端 - 服务器应用程序的常见服务,核心就干三件事 连接处理、身份验证、安全。
连接管理器(Connection Manager)
当客户端连接到服务器时,客户端会为其连接获得自己的线程。所有来自该客户端的查询都在指定的线程内执行。线程由服务器缓存,因此不需要为每个新连接创建和销毁。
安全性和权限模块(Security and Privilege Module)
在客户端成功连接到MySQL服务器后,服务器将检查该客户端是否有权限对MySQL服务器发出某些查询。
2. MySQL服务器层
这一层负责MySQL关系数据库管理系统的所有逻辑功能。MySQL服务器的大脑位于这一层。MySQL的逻辑层分为几个子组件,包括:服务接口和工具集、SQL接口、SQL解析器、优化器、缓存和缓冲区。
2.1. 服务支持和工具集
MySQL提供了相当广泛的服务支持和工具集 。这是MySQL受欢迎的主要原因之一。这一层为MySQL系统的管理和维护提供了服务和实用程序,支持备份和恢复、安全、复制、集群、分区、工作台等辅助和高可用扩展支持功能。
2.2. SQL Interface
结构化查询语言(SQL)是一种查询语言,用于查询MySQL服务器。它是MySQL客户端用户和服务器之间互动的工具。一些SQL组件包括数据操作语言(DML)、数据定义语言(DDL)、存储过程、视图、触发器。
2.3. 解析器
解析器(Parser)是MySQL服务层的一个重要组件,负责将用户提交的SQL语句进行解析和语法分析,以便后续的优化和执行。
解析器的主要功能
-
词法分析:解析器首先会对SQL语句进行词法分析,将输入的字符串按照空格、括号、逗号等分隔符进行切割,形成一个个标记(Token)。
-
语法分析:解析器根据MySQL定义的语法规则,对词法分析得到的标记进行语法分析,建立一棵语法树(Parse Tree)或语法分析树(Abstract Syntax Tree,AST)。语法分析的过程中,解析器会检查SQL语句的结构是否符合语法规则,如果发现错误,会抛出相应的错误信息。
-
语义分析:解析器会对语法分析得到的语法树进行语义分析,以确定SQL语句的意义和执行计划。例如,解析器会检查表名、列名是否存在,检查数据类型是否匹配,以及解析查询语句的选项(如DISTINCT、GROUP BY、HAVING等)。
-
优化:解析器将解析得到的语法树交给优化器(Optimizer)进行进一步的优化。优化器会考虑不同的执行计划,选择最优的执行计划,并生成相应的执行计划树(Execution Plan Tree)。
解析器的工作是将用户输入的SQL语句转化为可执行的内部表示形式,为后续的执行器(Executor)执行提供必要的信息和指令。通过解析器,MySQL能够理解和处理用户提交的SQL语句,并将其转化为对底层存储引擎的实际操作。
举个解析器 例子理解一下
假设有以下SQL语句:SELECT * FROM customers WHERE age > 30;
-
词法分析:将输入的SQL语句按照空格和关键字进行切割,得到以下标记序列:SELECT, *, FROM, customers, WHERE, age, >, 30, ;
-
语法分析:根据MySQL的语法规则,将标记序列构建成语法树。语法树的结构

-
语义分析:解析器进行语义分析,检查语法树中的表名、列名是否存在,数据类型是否匹配等。例如,解析器会检查是否存在名为"customers"的表,以及"age"列是否存在。
-
优化:解析器将语法树交给优化器进行优化,选择最优的执行计划。在这个例子中,优化器可能会考虑是否使用索引来加速查询,并生成相应的执行计划树。
解析器完成以上过程后,将生成的内部表示形式传递给执行器,执行器根据执行计划执行具体的操作,返回查询结果给用户。
2.4. 优化器
优化器的主要任务是根据查询语句的语义和数据库的统计信息,选择最优的执行计划来执行查询操作。优化器的目标是通过选择最优的执行计划,从而提高查询的执行效率和性能。优化器的工作是在查询执行之前进行的,它的输出是一个优化的执行计划,用于指导数据库引擎的具体执行操作。
优化器的工作流程
-
查询重写:优化器会对查询语句进行重写,将其转化为逻辑查询树或者其他内部表示形式。在这个过程中,优化器会进行语法分析、语义分析和查询优化规则的应用,以生成一个优化的查询计划。
-
代价估算:优化器会对每个可能的查询计划进行代价估算,评估每个计划执行所需的时间、CPU和内存开销等。这个过程主要是根据数据库的统计信息和查询操作的特性来进行估算,以便选择代价最低的执行计划。
-
执行计划生成:优化器会根据代价估算的结果,选择一个最优的执行计划。执行计划是一个具体的操作序列,描述了查询操作在数据库引擎中的执行顺序和方式。优化器会考虑索引、连接操作、排序和聚合等操作的执行顺序和方法,以最小化查询的执行代价。
-
执行计划优化:生成执行计划后,优化器还会对执行计划进行进一步的优化。这包括对操作的顺序进行优化、选择最适合的算法和数据结构、选择合适的并行度等。
举个优化器 例子理解一下
假设有一个电商平台,需要进行用户的购物车查询和商品信息查询。有以下两个表:
表A:用户购物车表(id, user_id, product_id, quantity)
表B:商品信息表(product_id, product_name, price)
现在有一个查询语句:
SELECT A.user_id, B.product_name, B.price, A.quantity
FROM A
JOIN B ON A.product_id = B.product_id
WHERE A.user_id = 12345
ORDER BY B.price DESC
在这个例子中,MySQL优化器可以进行以下优化:
查询重写:优化器可以将查询语句重写为内部表示形式,例如将关键字“JOIN”和“ON”转化为适合优化的形式。
优化规则应用:优化器可以根据查询语句的结构和语义,应用一系列的查询优化规则。例如,优化器可以将WHERE子句中的“A.user_id = 12345”转化为一个过滤条件,以提前过滤掉不满足条件的行。
统计信息收集:优化器可以根据表A和表B的统计信息,如索引的选择性、行数等,来估计执行各个操作的成本。例如,优化器可以根据索引的选择性和行数估计连接操作的成本,以决定使用哪个表作为驱动表和被驱动表。
执行计划生成:根据代价估算的结果,优化器可以生成一个执行计划。在这个例子中,优化器可能选择使用索引来进行表的连接操作,以减少磁盘IO的开销,并且根据WHERE子句的过滤条件,选择合适的索引进行过滤操作。
执行计划优化:生成执行计划后,优化器还可以对执行计划进行进一步的优化。例如,优化器可以对操作的顺序进行优化,选择最适合的算法和数据结构,以及选择合适的并行度。
通过以上优化步骤,MySQL优化器可以选择最优的执行计划,以提高查询的性能和效率。在这个例子中,优化器可能选择使用用户ID为索引进行过滤操作,并通过商品ID进行表的连接操作,以获取指定用户的购物车商品信息,并按照价格降序排列。这样可以减少磁盘IO的开销,并快速获取所需的结果集。
2.5. 缓存
MySQL缓存指的是MySQL服务器的内存缓存,也称为查询缓存(Query Cache)。MySQL缓存是指MySQL服务器将执行过的查询结果存储在内存中,并在下一次有相同的查询请求时,直接从内存中返回结果,而不需要再次执行查询语句。这样可以大大提高查询的性能和效率。
MySQL缓存可以分为两种:
- 查询缓存(Query Cache)
当一个查询被执行时,MySQL服务器会将查询结果存储在内存中。如果下次有相同的查询请求,MySQL会直接从缓存中返回结果,而不去执行查询语句。查询缓存对于相同查询请求的重复查询非常有效,但对于更新频繁的表和数据变化较大的表,会导致缓存命中率低,影响性能。
MySQL 8.0版本已经移除了查询缓存功能,主要原因是因为查询缓存对于高并发的查询和更新操作会导致性能瓶颈,而且查询缓存对于更新频繁的表和数据变化较大的表,会导致缓存命中率低,影响性能。
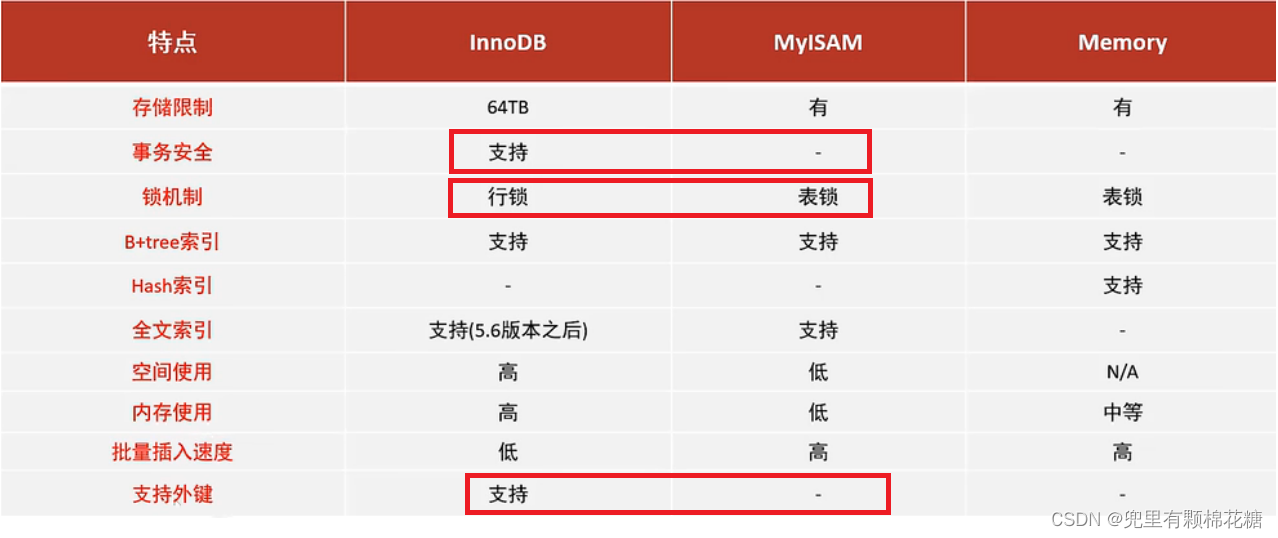
3. 存储引擎层
可插拔存储引擎功能使MySQL成为开发者首选。这是MySQL能够在大玩家中取得优势的特性。MySQL允许我们根据不同的情况和要求选择各种存储引擎。我们将在即将到来的文章中讨论每个存储引擎的特性,这里只列出了支持的存储引擎的列表。
MyISAM、InnoDB、Federated、Mrg_MyISAM、Blackhole、CSV、Memory、Archive、Performance_schema。
3.1. 可插拔的特性
这意味着用户可以根据自己的需求选择合适的存储引擎,甚至可以在不停止MySQL服务器的情况下切换存储引擎。
之所以可以插拔的方式,是因为MySQL提供了一个叫做存储引擎API的接口,允许第三方开发者开发自己的存储引擎,并将其集成到MySQL中。通过这个接口,用户可以定制存储引擎,以满足各种不同的数据存储需求。
用户可以通过以下步骤在MySQL中切换存储引擎:
-
查看当前使用的存储引擎:可以使用以下命令查看MySQL当前的默认存储引擎和已安装的存储引擎:
SHOW ENGINES; -
选择并安装新的存储引擎:根据需求选择合适的存储引擎,然后按照引擎提供的安装说明进行安装。
-
修改MySQL配置文件:将MySQL配置文件(通常是my.cnf)中的default_storage_engine参数设置为新的存储引擎。
-
重启MySQL服务器:重启MySQL服务器使新的存储引擎生效。
-
创建和使用新的存储引擎表:使用CREATE TABLE语句创建新的存储引擎表,并在查询时指定使用新的存储引擎。
3.2. 常见的MySQL存储引擎包括:
-
InnoDB引擎:InnoDB是MySQL默认的存储引擎,它支持事务、行级锁和外键约束等特性。InnoDB引擎适用于大多数应用场景,尤其是需要事务支持和高并发读写的场景。
-
MyISAM引擎:MyISAM是MySQL的另一种常用存储引擎,它不支持事务和行级锁,但具有快速的读取性能和较小的存储空间占用。MyISAM引擎适用于读密集的应用场景,如数据仓库和日志分析。
-
Memory引擎:Memory引擎将表数据存储在内存中,具有快速的读写性能和低延迟。但是,由于数据存储在内存中,重启MySQL服务器或服务器崩溃时会导致数据丢失。Memory引擎适用于需要快速读写的临时表和缓存表。
-
NDB Cluster引擎:NDB Cluster引擎是MySQL的分布式存储引擎,它可以将数据分布在多个节点上,并提供高可用性和容错性。NDB Cluster引擎适用于需要高可用性和大规模数据存储的场景,如电信、金融和互联网应用。
除了以上常见的存储引擎,还有其他一些存储引擎如Archive、CSV、Blackhole等,它们具有各自的特点和适用场景
参考文档
https://www.geeksforgeeks.org/architecture-of-mysql/
![[Go 夜读 第 148 期] Excelize 构建 WebAssembly 版本跨语言支持实践](https://img-blog.csdnimg.cn/40faac6ec3d74aca911cc9df6cc8b32c.jpeg#pic_cente)