🚀write in front🚀
📜所属专栏: C++学习
🛰️博客主页:睿睿的博客主页
🛰️代码仓库:🎉VS2022_C语言仓库
🎡您的点赞、关注、收藏、评论,是对我最大的激励和支持!!!
关注我,关注我,关注我,你们将会看到更多的优质内容!!

文章目录
- 前言
- 一.概念:
- 二.二叉树的实现
- 1.0版本(循环版本):
- 1. 二叉搜索树的查找
- 2. 二叉搜索树的插入
- 3. 二叉搜索树的删除
- 2.0版本(递归版本)
- 三.搜索二叉树的应用:
- 总结
前言
一.概念:
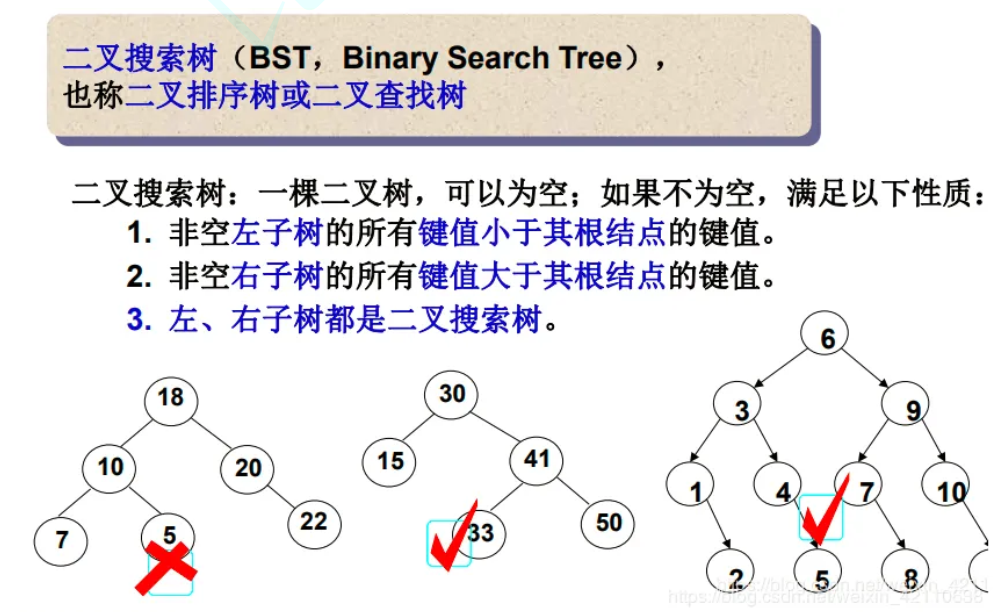
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
- 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
- 若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
- 它的左右子树也分别为二叉搜索树
二.二叉树的实现
1.0版本(循环版本):
1. 二叉搜索树的查找
a、从根开始比较,查找,由二叉搜索树的性质可知,比根大则往右边走查找,比根小则往左边走查找。
b、最多查找高度次,走到到空,还没找到,这个值不存在。
2. 二叉搜索树的插入
插入的具体过程如下:
a. 树为空,则直接新增节点,赋值给root指针
b. 树不空,按二叉搜索树性质查找插入位置,插入新节点(这里的插入都是指的插在树叶的后面)
3. 二叉搜索树的删除
首先查找元素是否在二叉搜索树中,如果不存在,则返回, 否则要删除的结点可能分下面四种情况:
a. 要删除的结点无孩子结点
b. 要删除的结点只有左孩子结点
c. 要删除的结点只有右孩子结点
d. 要删除的结点有左、右孩子结点
看起来有待删除节点有4中情况,实际情况a可以与情况b或者c合并起来,因此真正的删除过程如下:
- 先找到要删除的结点和其父节点
- 找到之后分两种情况:
a.删除结点有一个孩子或没有孩子:
-
左为空:
a1.父节点和删除结点如果重合,直接让root指向删除结点的右边
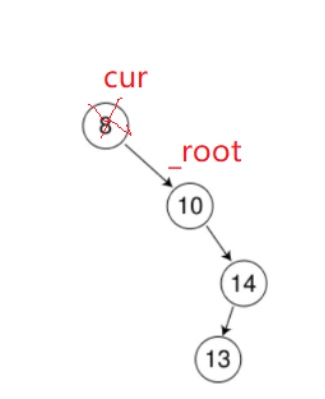
a2父节点指向删除结点的右边
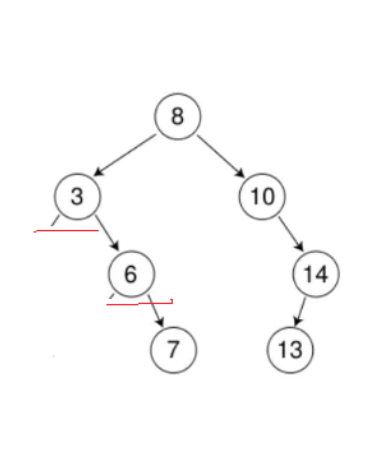
-
右为空(与上面同理)
a3 父节点和删除结点如果重合,直接让root指向删除结点的左边
a4父节点指向删除结点的左边
b.删除结点有两个孩子:
替换法删除:通过左子树的最大结点或右树的最小结点来删除的结点替换,替换完就转化为a类的场景(左子树为空或右子树为空),删掉替换后的结点即可,并且此时的那个结点一定有固定的一边是空的,由你选择的是左子树的最大结点还是右子树的最小结点而定。
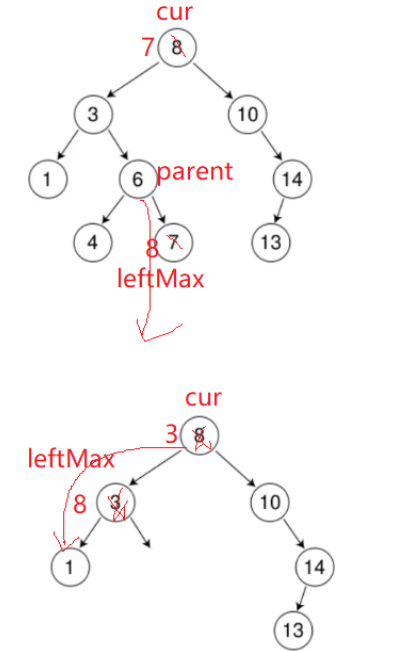
总代码:
template<class T>struct BSTreeNode{BSTreeNode<T>* _left = nullptr;BSTreeNode<T>* _right = nullptr;T _key;BSTreeNode(const T& key) :_key(key){}};template<class T>class BStree{typedef BSTreeNode<T> Node;private:Node* _root = nullptr;void _InOder(Node* root){if (root == nullptr){return;}_InOder(root->_left);cout << root->_key << " ";_InOder(root->_right);}void _Destroy(Node* root){if (root == nullptr){return;}_Destroy(root->_left);_Destroy(root->_right);delete root;}Node* copy(Node* root){if (root == nullptr){return nullptr;}Node* copyroot = nullptr;copyroot = new Node(root->_key);copyroot->_left=copy(root->_left);copyroot->_right=copy(root->_right);return copyroot;}public:BStree(){}~BStree(){_Destroy(_root);}BStree(const BStree<T>& t){_root = copy(t._root);//在类里面可以看到私有的}BStree<T>& operator=(const BStree<T> t){swap(_root, t._root);return *this;}bool Insert(const T& key){if (_root == nullptr){_root = new Node(key);return true;}Node* cur = _root;Node* parent = _root;while (cur){if (key > cur->_key){parent = cur;cur = cur->_right;}else if (key < cur->_key){parent = cur;cur = cur->_left;}else{return false;}}cur = new Node(key);if (parent->_key > key){parent->_left = cur;}else if (parent->_key < key){parent->_right = cur;}return true;}bool Find(const T& key){Node* cur = _root;while (cur){if (key > cur->_key){cur = cur->_right;}else if (key < cur->_key){cur = cur->_left;}else{return true;}}return false;}void InOder(){_InOder(_root);cout << endl;}bool Erase(const T& key){Node* cur = _root;Node* parent = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}//先寻找key的位置else{//找到之后有两种情况://第一种就是托孤:不管有一个孩子还是没有孩子都可以处理if (cur->_left == nullptr){//这里的坑就是删除头结点位置,此时cur和parent在同一个位置if (_root == cur){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}}else if (cur->_right == nullptr){//同样是上面那个坑if (_root == cur){_root = cur->_left;}else{if (parent->_left == cur){parent->_left = cur->_left;}else{parent->_right = cur->_left;}}}//第二种就是找到左树最大结点或右树最小结点,有两个孩子的时候else{//左树的最大结点:Node* _parent = cur;Node* LeftMax = cur->_left;while (LeftMax->_right){_parent = LeftMax;LeftMax = LeftMax->_right;}swap(LeftMax->_key, cur->_key);if (_parent->_right == LeftMax){_parent->_right = LeftMax->_left;}else{_parent->_left = LeftMax->_left;}cur = LeftMax;}delete cur;return true;}}return false;}};
}
2.0版本(递归版本)
其实递归比循环好实现很多,只是存在栈溢出的问题罢了,并且递归有些地方是非常巧妙的,我们先来看看完整代码:
template<class T>struct BSTreeNode{BSTreeNode<T>* _left = nullptr;BSTreeNode<T>* _right = nullptr;T _key;BSTreeNode(const T& key) :_key(key){}};template<class T>class BStree{typedef BSTreeNode<T> Node;private:Node* _root = nullptr;void _InOder(Node* root){if (root == nullptr){return;}_InOder(root->_left);cout << root->_key << " ";_InOder(root->_right);}bool _InsertR(const T& key,Node*& root){if (root == nullptr){root = new Node (key);return true;}if (root->_key > key){return _InsertR(key, root->_left);}else if (root->_key < key){return _InsertR(key, root->_right);}else{return false;}}bool _FindR(const T& key, Node* root){if (root == nullptr){return false;}if (root->_key > key){return _FindR(key, root->_left);}else if (root->_key < key){return _FindR(key, root->_right);}else{return true;}}bool _EraseR(const T& key, Node*& root){if (root == nullptr){return false;}if (root->_key > key){return _EraseR(key, root->_left);}else if (root->_key < key){return _EraseR(key, root->_right);}else{Node* del = root;if (root->_right == nullptr){root = root->_left;}else if (root->_left == nullptr){root = root->_right;}else{Node* LeftMax = root->_left;while (LeftMax->_right){LeftMax = LeftMax->_right;}swap(LeftMax->_key, root->_key);_EraseR(key, root->_left);del = LeftMax;}delete del;return true;}}void _Destroy(Node* root){if (root == nullptr){return;}_Destroy(root->_left);_Destroy(root->_right);delete root;}Node* copy(Node* root){if (root == nullptr){return nullptr;}Node* copyroot = nullptr;copyroot = new Node(root->_key);copyroot->_left=copy(root->_left);copyroot->_right=copy(root->_right);return copyroot;}public:BStree(){}~BStree(){_Destroy(_root);}BStree(const BStree<T>& t){_root = copy(t._root);//在类里面可以看到私有的}BStree<T>& operator=(const BStree<T> t){swap(_root, t._root);return *this;}bool InsertR(const T& key){return _InsertR(key,_root);}bool FindR(const T& key){return _FindR(key,_root);}void InOder(){_InOder(_root);cout << endl;}bool EraseR(const T& key){return _EraseR(key, _root);}};
}
我们来看一下递归在引用方面巧妙的使用:
这是循环的Insert:

这是递归的_Insert:

我们会明显发现递归在传参的时候传的是引用,为什么呢?接着往下看,循环的时候,为了使链接能够完成,我们会通过不断更新父节点来记录父节点,而递归的时候就不用。其实原因很显然,通过引用,在递归时的root就是他的父节点(上一个结点的root->right或root->left)的别名,此时已经具有链接关系,在这里直接赋值就可以了。
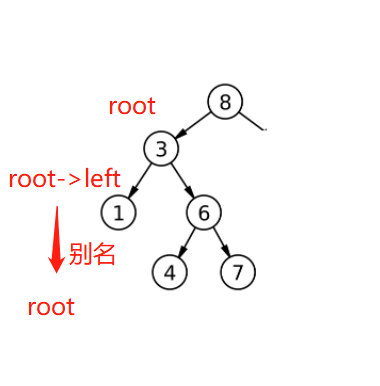
在这里就省去了很多麻烦的事情,这就是递归的巧妙之处,而我们的循环不能使用引用,因为引用不能改变指向,在循环里面用引用只会使指向混乱,而在递归里面,会建立很多栈帧,每一个栈帧使用一次引用,在不出错的情况下还减少了保存父节点的麻烦。
同样的erase也是,在递归的时候使用引用,不仅减少了parent保存的麻烦,还省去了父节点和删除结点重合情况的特殊处理。
递归版本:

循环版本:

三.搜索二叉树的应用:
- K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。
比如:给一个单词word,判断该单词是否拼写正确,具体方式如下:
- 以词库中所有单词集合中的每个单词作为key,构建一棵二叉搜索树
- 在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。
- KV模型:每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。该种方式在现实生活中非常常见:
比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英文单词与其对应的中文<word, chinese>就构成一种键值对;
再比如统计单词次数,统计成功后,给定单词就可快速找到其出现的次数,单词与其出
现次数就是<word, count>就构成一种键值对
还有就是我们平时刷身份证,平台通过我们身份证号码找到我们相关消息,只不过这个是更复杂的场景。下面我们来看一下具体的应用:
我们只需要把平常的多加一个value值即可,在插入的时候多插入一个值即可实现:
namespace key_value
{template<class T,class V>struct BSTreeNode{BSTreeNode<T,V>* _left = nullptr;BSTreeNode<T,V>* _right = nullptr;T _key;V _value;BSTreeNode(const T& key,const V& value) :_key(key),_value(value){}};template<class T,class V>class BStree{typedef BSTreeNode<T,V> Node;private:Node* _root = nullptr;void _InOder(Node* root){if (root == nullptr){return;}_InOder(root->_left);cout << root->_key << " "<<root->_value<<endl;_InOder(root->_right);}void Destroy(Node*& root){if (root == nullptr){return;}Destroy(root->_left);Destroy(root->_right);delete root;root = nullptr;}public:BStree(){}~BStree(){Destroy(_root);}bool Insert(const T& key,const V& value){if (_root == nullptr){_root = new Node(key,value);return true;}Node* cur = _root;Node* parent = _root;while (cur){if (key > cur->_key){parent = cur;cur = cur->_right;}else if (key < cur->_key){parent = cur;cur = cur->_left;}else{return false;}}cur = new Node(key,value);if (parent->_key > key){parent->_left = cur;}else if (parent->_key < key){parent->_right = cur;}return true;}Node* Find(const T& key){Node* cur = _root;while (cur){if (key > cur->_key){cur = cur->_right;}else if (key < cur->_key){cur = cur->_left;}else{return cur;}}return nullptr;}void InOder(){_InOder(_root);cout << endl;}bool Erase(const T& key){Node* cur = _root;Node* parent = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}//先寻找key的位置else{//找到之后有两种情况://第一种就是托孤:不管有一个孩子还是没有孩子都可以处理if (cur->_left == nullptr){//这里的坑就是删除头结点位置,此时cur和parent在同一个位置if (_root == cur){_root = cur->_right;}else{if (parent->_left == cur){parent->_left = cur->_right;}else{parent->_right = cur->_right;}}}else if (cur->_right == nullptr){//同样是上面那个坑if (_root == cur){_root = cur->_left;}else{if (parent->_left == cur){parent->_left = cur->_left;}else{parent->_right = cur->_left;}}}//第二种就是找到左树最大结点或右树最小结点,有两个孩子的时候else{//左树的最大结点:Node* _parent = cur;Node* LeftMax = cur->_left;while (LeftMax->_right){_parent = LeftMax;LeftMax = LeftMax->_right;}swap(LeftMax->_key, cur->_key);if (_parent->_right == LeftMax){_parent->_right = LeftMax->_left;}else{_parent->_left = LeftMax->_left;}cur = LeftMax;}delete cur;return true;}}return false;}};
}字典的例子:
void TestBSTree3()
{//BSTree<string, Date> carTree;key_value::BStree<string, string> dict;dict.Insert("insert", "插入");dict.Insert("sort", "排序");dict.Insert("right", "右边");dict.Insert("date", "日期");string str;while (cin >> str){key_value::BSTreeNode<string, string>* ret = dict.Find(str);if (ret){cout << ret->_value << endl;}else{cout << "无此单词" << endl;}}
}
统计个数的例子:
void TestBSTree4()
{// 11:44继续// 统计水果出现的次数string arr[] = { "西瓜", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };key_value::BStree<string, int> st;for (auto & str : arr){auto ret = st.Find(str);if (ret){ret->_value++;}else{st.Insert(str,1);}}st.InOder();
}
总结
其实搜索二叉树就是将前面的数据结构和我们所学的C++进行了结合!其实我们不难看出,对于循环和递归,循环的使用就会伴随着很多特殊情况的出现,我们都要一一解决,并且不好读懂,但是他的性能很高,而递归则是很简短并且容易看懂,但是代价就是会出现栈溢出的现象。今后要根据实际情况具体选择。
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!
专栏订阅:
每日一题
C语言学习
算法
智力题
初阶数据结构
Linux学习
C++学习
更新不易,辛苦各位小伙伴们动动小手,👍三连走一走💕💕 ~ ~ ~ 你们真的对我很重要!最后,本文仍有许多不足之处,欢迎各位认真读完文章的小伙伴们随时私信交流、批评指正!








![[尚硅谷React笔记]——第2章 React面向组件编程](https://img-blog.csdnimg.cn/872662c853d44b0d9a2568b1fbecbbb7.png)