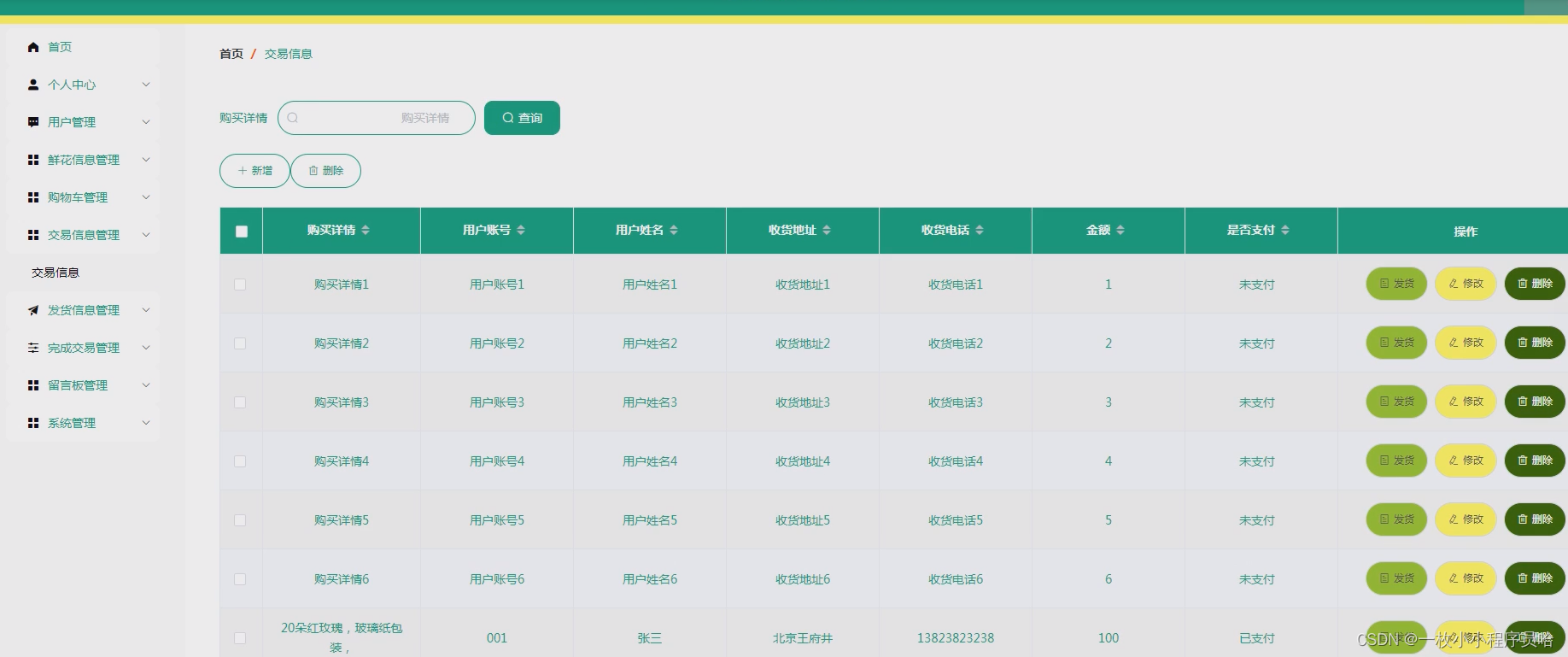
文章目录
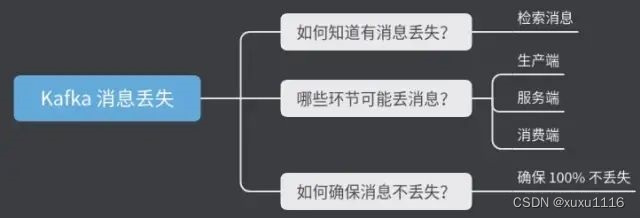
- 1、如何知道有消息丢失?
- 2、哪些环节可能丢消息?
- 3、如何确保消息不丢失?
引入 MQ 消息中间件最直接的目的:系统解耦以及流量控制(削峰填谷)
- 系统解耦: 上下游系统之间的通信相互依赖,利用 MQ 消息队列可以隔离上下游环境变化带来的不稳定因素。
- 流量控制: 超高并发场景中,引入 MQ 可以实现流量 “削峰填谷” 的作用以及服务异步处理,不至于打崩服务。
引入 MQ 同样带来其他问题:数据一致性。
在分布式系统中,如果两个节点之间存在数据同步,就会带来数据一致性的问题。消息生产端发送消息到 MQ 再到消息消费端需要保证消息不丢失。

所以在使用 MQ 消息队列时,需要考虑这 3 个问题:
- 如何知道有消息丢失?
- 哪些环节可能丢消息?
- 如何确保消息不丢失?
1、如何知道有消息丢失?
如何感知消息是否丢失了?可总结如下:
- 他人反馈: 运营、PM 反馈消息丢失。
- 监控报警: 监控指定指标,即时报警人工调整。Kafka 集群异常、Broker 宕机、Broker 磁盘挂载问题、消费者异常导致消息积压等都会给用户直接感觉是消息丢失了。
案例:舆情分析中数据采集同步
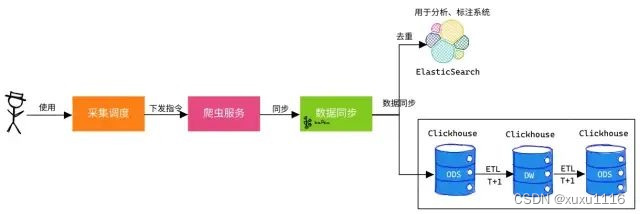
- PM 可自己下发采集调度指令,去采集特定数据。
- PM 可通过 ES 近实时查询对应数据,若没相应数据可再次下发指令。
当感知消息丢失了,那就需要一种机制来检查消息是否丢失。
检索消息
运维工具有:
1.查看 Kafka 消费位置:
# 查看某个topic的message数量
$ ./kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic test_topic# 查看consumer Group列表,面试宝典:https://www.yoodb.com
$ ./kafka-consumer-groups.sh --list --bootstrap-server 192.168.88.108:9092# 查看 offset 消费情况
$ ./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group console-consumer-1152 --describe
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
console-consumer-1152 test_topic 0 - 4 - consumer-console-consumer-1152-1-2703ea2b-b62d-4cfd-8950-34e8c321b942 /127.0.0.1 consumer-console-consumer-1152-1
2.利用工具:Kafka Tools
3.其他可见化界面工具
2、哪些环节可能丢消息?
一条消息从生产到消费完成经历 3 个环节:消息生产者、消息中间件、消息消费者。

哪个环节都有可能出现消息丢失问题。
1)生产端
首先要认识到 Kafka 生产端发送消息流程:
调用 send() 方法时,不会立刻把消息发送出去,而是缓存起来,选择恰当时机把缓存里的消息划分成一批数据,通过 Sender 线程按批次发送给服务端 Broker。
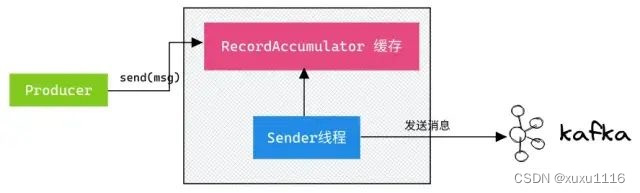
此环节丢失消息的场景有: 即导致 Producer 消息没有发送成功
1.网络波动: 生产者与服务端之间的链路不可达,发送超时。现象是:各端状态正常,但消费端就是没有消费消息,就像丢失消息一样。
2.解决措施: 重试 props.put(“retries”, “10”);
3.不恰当配置: 发送消息无 ack 确认; 发送消息失败无回调,无日志。
producer.send(new ProducerRecord<>(topic, messageKey, messageStr), new CallBack(){...});
4.解决措施: *设置 acks=1 或者 acks=all。发送消息设置回调。
回顾下重要的参数: acks
- acks=0:不需要等待服务器的确认. 这是 retries设置无效. 响应里来自服务端的 offset 总是 -1,producer只管发不管发送成功与否。延迟低,容易丢失数据。
- acks=1:表示 leader 写入成功(但是并没有刷新到磁盘)后即向 producer 响应。延迟中等,一旦 leader 副本挂了,就会丢失数据。
- acks=all:等待数据完成副本的复制, 等同于 -1. 假如需要保证消息不丢失, 需要使用该设置. 同时需要设置 unclean.leader.election.enable 为 true, 保证当 ISR 列表为空时, 选择其他存活的副本作为新的 leader.
2)服务端
先来了解下 Kafka Broker 写入数据的过程:
1.Broker接收到一批数据,会先写入内存 PageCache(OS Cache)中。
2.操作系统会隔段时间把 OS Cache 中数据进行刷盘,这个过程会是 「异步批量刷盘」 。
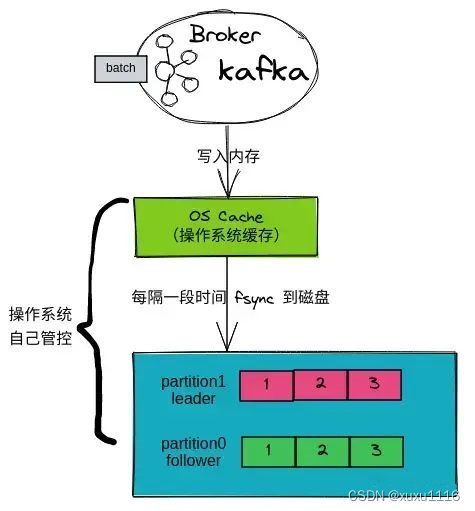
这里就有个隐患,如果数据写入 PageCache 后 Kafka Broker宕机会怎样?机子宕机/掉电?
Kafka Broker 宕机: 消息不会丢失。因为数据已经写入 PageCache,只等待操作系统刷盘即可。
机子宕机/掉电: 消息会丢失。因为数据仍在内存里,内存RAM掉电后就会丢失数据。
- 解决方案 :使用带蓄电池后备电源的缓存 cache,防止系统断电异常。
1.对比学习 MySQL 的 “双1” 策略,基本不使用这个策略,因为 “双1” 会导致频繁的 I/O 操作,也是最慢的一种。
2.对比学习 Redis 的 AOF 策略,默认且推荐的策略:Everysec(AOF_FSYNC_EVERYSEC) 每一秒钟保存一次(默认): 。每个写命令执行完,
只是先把日志写到 AOF 文件的内存缓冲区, 每隔一秒把缓冲区中的内容写入磁盘。
拓展:Kafka 日志刷盘机制
# 推荐采用默认值,即不配置该配置,交由操作系统自行决定何时落盘,以提升性能。
# 针对 broker 配置:
log.flush.interval.messages=10000 # 日志落盘消息条数间隔,即每接收到一定条数消息,即进行log落盘。
log.flush.interval.ms=1000 # 日志落盘时间间隔,单位ms,即每隔一定时间,即进行log落盘。# 针对 topic 配置:面试宝典:https://www.yoodb.com
flush.messages.flush.ms=1000 # topic下每1s刷盘
flush.messages=1 # topic下每个消息都落盘# 查看 Linux 后台线程执行配置
$ sysctl -a | grep dirty
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10 # 表示当脏页占总内存的的百分比超过这个值时,后台线程开始刷新脏页。
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000 # 表示脏数据多久会被刷新到磁盘上(30秒)。
vm.dirty_ratio = 20
vm.dirty_writeback_centisecs = 500 # 表示多久唤醒一次刷新脏页的后台线程(5秒)。
vm.dirtytime_expire_seconds = 43200
Broker 的可靠性需要依赖其多副本机制: 一般副本数 3 个(配置参数:replication.factor=3)
- Leader Partition 副本:提供对外读写机制。
- Follower Partition 副本:同步 Leader 数据。
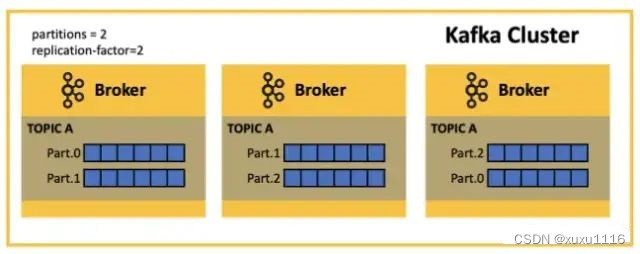
副本之间的数据同步也可能出现问题:数据丢失问题和数据不一致问题。
解决方案:ISR 和 Epoch 机制
-
ISR(In-Sync Replicas) : 当 Le``ader 宕机,可以从 ISR 中选择一个 Follower 作为 Leader。
-
Epoch 机制: 解决 Leader 副本高水位更新和 Follower 副本高水位更新在时间上是存在错配问题。
Tips: Kafka 0.11.x 版本才引入 leader epoch 机制解决高水位机制弊端。
对应需要的配置参数如下:
1.acks=-1 或者 acks=all: 必须所有副本均同步到消息,才能表明消息发送成功。
2.replication.factor >= 3: 副本数至少有 3 个。
3.min.insync.replicas > 1: 代表消息至少写入 2个副本才算发送成功。前提需要 acks=-1。
举个栗子:Leader 宕机了,至少要保证 ISR 中有一个 Follower,这样这个Follwer被选举为Leader 且不会丢失数据。
公式:replication.factor = min.insync.replicas + 1
4.unclean.leader.election.enable=false: 防止不在 ISR 中的 Follower 被选举为 Leader。
Kafka 0.11.0.0版本开始默认 unclean.leader.election.enable=false
3)消费端
消费端消息丢失场景有:
1.消息堆积: 几个分区的消息都没消费,就跟丢消息一样。
2.解决措施: 一般问题都出在消费端,尽量提高客户端的消费速度,消费逻辑另起线程进行处理。
3.自动提交: 消费端拉下一批数据,正在处理中自动提交了 offset,这时候消费端宕机了; 重启后,拉到新一批数据,而上一批数据却没处理完。
4.解决措施: 取消自动提交 auto.commit = false,改为手动 ack。
5.心跳超时,引发 Rebalance: 客户端心跳超时,触发 Rebalance被踢出消费组。如果只有这一个客户端,那消息就不会被消费了。
同时避免两次 poll 的间隔时间超过阈值:
6.max.poll.records:降低该参数值,建议远远小于 <单个线程每秒消费的条数> * <消费线程的个数> * <max.poll.interval.ms> 的积。
max.poll.interval.ms: 该值要大于 <max.poll.records> / (<单个线程每秒消费的条数> * <消费线程的个数>) 的值。
解决措施: 客户端版本升级至 0.10.2 以上版本。
案例:凡凡曾遇到数据同步时,消息中的文本需经过 NLP 的 NER 分析,再同步到 ES。
这个过程的主要流程是:
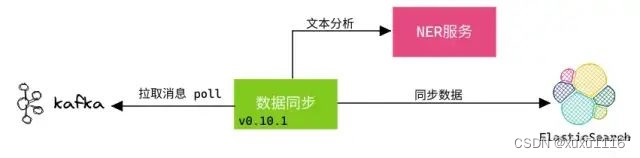
1.数据同步程序从 Kafka 中拉取消息。
2.数据同步程序将消息内的文本发送的 NER 进行分析,得到特征数组。
3.数据同步程序将消息同步给 ES。
现象:线上数据同步程序运行一段时间后,消息就不消费了。
- 排查日志: 发现有 Rebalance 日志,怀疑是客户端消费太慢被踢出了消费组。
- 本地测试: 发现运行一段时间也会出现 Rebalance,且 NLP的NER 服务访问 HTTP 500 报错。
- 得出结论: 因NER服务异常,导致数据同步程序消费超时。且当时客户端版本为 v0.10.1,Consumer 没有独立线程维持心跳,而是把心跳维持与 poll 接口耦合在一起,从而也会造成心跳超时。
当时解决措施是:
1.session.timeout.ms: 设置为 25s,当时没有升级客户端版本,怕带来其他问题。
2.熔断机制: 增加 Hystrix,超过 3 次服务调用异常就熔断,保护客户端正常消费数据。
3、如何确保消息不丢失?
掌握这些技能:
1.熟悉消息从发送到消费的每个阶段
2.监控报警 Kafka 集群
3.熟悉方案 “MQ 可靠消息投递”
怎么确保消息 100% 不丢失?
到这,总结下:
①生产端:
- 设置重试:props.put(“retries”, “10”);
- 设置 acks=all
- 设置回调:producer.send(msg, new CallBack(){…});
②Broker:
- 内存:使用带蓄电池后备电源的缓存 cache。
- Kafka 版本 0.11.x 以上:支持 Epoch 机制。
- replication.factor >= 3: 副本数至少有 3 个。
- min.insync.replicas > 1: 代表消息至少写入 2个副本才算发送成功。前提需要 acks=-1。
- unclean.leader.election.enable=false: 防止不在 ISR 中的 Follower 被选举为 Leader。
③消费端
- 客户端版本升级至 0.10.2 以上版本。
- 取消自动提交 auto.commit = false,改为手动 ack。
- 尽量提高客户端的消费速度,消费逻辑另起线程进行处理