哈希表的基本概念
哈希表是一种数据结构,用于存储键值对。它的核心思想是将键通过哈希函数转化为索引,然后将值存储在该索引位置的数据结构中。
哈希函数的作用
哈希函数是哈希表的关键部分。它将输入(键)映射到哈希表的索引位置。一个好的哈希函数应该具有以下特点:
-
快速计算:哈希函数应该能够快速计算出索引,以保持高效性能。
-
均匀分布:哈希函数应该尽可能均匀地将键分布在哈希表中,以减少哈希冲突的发生。
-
低冲突率:好的哈希函数应该最小化冲突的发生,即不同的键映射到同一个索引的情况。
哈希冲突的处理方法
哈希冲突是不同的键映射到相同索引的情况。解决哈希冲突的常见方法包括:
-
开放寻址法:如果发生冲突,就顺序查找下一个可用的位置,直到找到空槽或达到最大探测次数。
-
链地址法:每个哈希表索引位置都存储一个链表或其他数据结构,以存储多个键值对,具有相同哈希值的键值对将链接在一起。
任务
使用哈希表来解决查找和存储问题。哈希表是许多现实世界应用的基础,包括数据库索引、缓存系统和编程语言中的字典。
示例代码 - 使用C++创建简单的哈希表:
#include <iostream>
#include <vector>
#include <list>class HashTable {
public:HashTable(int size) : size(size), table(size) {}// 哈希函数:将键映射到索引int hash(const std::string& key) {int hashValue = 0;for (char ch : key) {hashValue += ch;}return hashValue % size;}// 插入键值对void insert(const std::string& key, int value) {int index = hash(key);table[index].push_back(std::make_pair(key, value));}// 查找键对应的值int get(const std::string& key) {int index = hash(key);for (const auto& pair : table[index]) {if (pair.first == key) {return pair.second;}}return -1; // 未找到}private:int size;std::vector<std::list<std::pair<std::string, int>>> table;
};int main() {HashTable ht(100); // 创建一个大小为100的哈希表// 插入键值对ht.insert("Alice", 25);ht.insert("Bob", 30);ht.insert("Charlie", 22);// 查找键对应的值std::cout << "Alice的年龄是:" << ht.get("Alice") << " 岁" << std::endl;return 0;
}
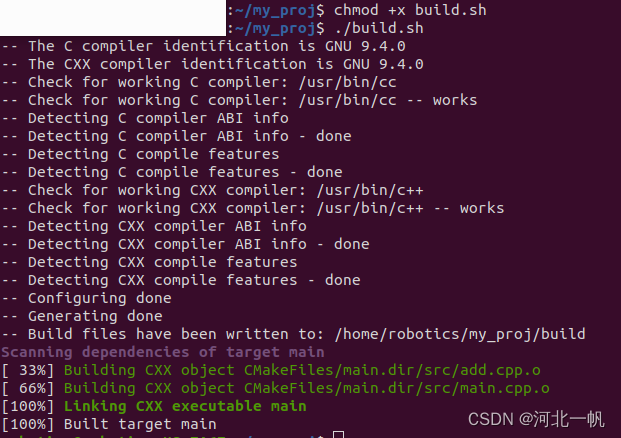
运行结果: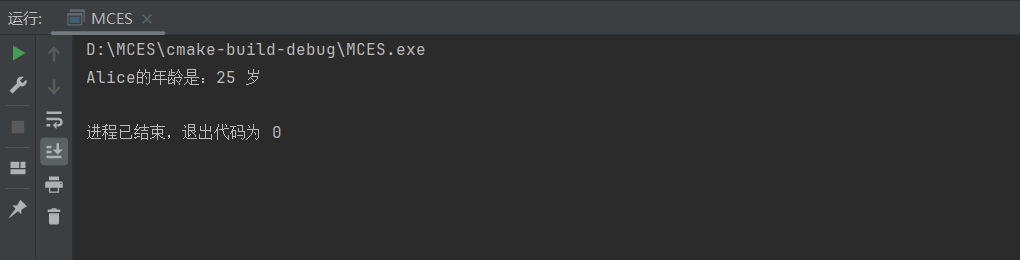
练习题:
-
解释哈希表的基本概念中的键、值、哈希函数和索引。
-
为什么哈希函数的均匀分布很重要?
-
描述哈希冲突以及解决哈希冲突的两种常见方法。
-
你可以设计一个简单的哈希表,用于存储学生的姓名和成绩。使用C++创建这个哈希表,并实现插入和查找功能。
解释哈希表的基本概念中的键、值、哈希函数和索引。
-
键(Key):键是哈希表中用于查找和访问数据的唯一标识符。它类似于字典中的词条,用于获取相应的值。在学生姓名和成绩的哈希表中,姓名可以是键。
-
值(Value):值是与键相关联的数据。在学生姓名和成绩的哈希表中,成绩可以是值。
-
哈希函数(Hash Function):哈希函数是一种将键映射到哈希表索引的算法。它接受键作为输入,并生成一个整数索引,用于在哈希表中存储或查找值。
-
索引(Index):索引是哈希表中的位置或槽,用于存储键值对。哈希函数计算的结果确定了键值对在哈希表中的存储位置。
为什么哈希函数的均匀分布很重要?
哈希函数的均匀分布非常重要,因为它直接影响了哈希表的性能。如果哈希函数不均匀,导致大量的键映射到相同的索引位置,会导致哈希冲突增加,使得哈希表性能下降。均匀分布意味着不同的键能够均匀地分散到不同的索引位置,减少冲突的概率,从而保持了哈希表的高效性能。
描述哈希冲突以及解决哈希冲突的两种常见方法。
-
哈希冲突(Hash Collision):哈希冲突是指两个不同的键通过哈希函数映射到相同的索引位置。这可能会导致数据丢失或覆盖,降低哈希表的性能。
-
解决哈希冲突的两种常见方法:
-
开放寻址法(Open Addressing):在发生冲突时,继续寻找下一个可用的索引位置,直到找到一个空槽或达到最大探测次数。常见的开放寻址方法包括线性探测和二次探测。
-
链地址法(Chaining):每个索引位置上都维护一个链表或其他数据结构,用于存储多个键值对。当发生冲突时,新的键值对被添加到链表中。这是解决冲突最常见的方法之一。
-
你可以设计一个简单的哈希表,用于存储学生的姓名和成绩。使用C++创建这个哈希表,并实现插入和查找功能。
当设计哈希表时,需要考虑哈希函数的设计,解决冲突的方法,以及合适的数据结构来存储每个索引位置上的键值对。下面是一个简单示例:
#include <iostream>
#include <vector>
#include <list>class HashTable {
public:HashTable(int size) : size(size), table(size) {}// 哈希函数int hash(const std::string& key) {int hashValue = 0;for (char ch : key) {hashValue += ch;}return hashValue % size;}// 插入键值对void insert(const std::string& key, int value) {int index = hash(key);table[index].push_back(std::make_pair(key, value));}// 查找键对应的值int get(const std::string& key) {int index = hash(key);for (const auto& pair : table[index]) {if (pair.first == key) {return pair.second;}}return -1; // 未找到}private:int size;std::vector<std::list<std::pair<std::string, int>>> table;
};int main() {HashTable ht(100); // 创建一个大小为100的哈希表// 插入键值对ht.insert("Alice", 85);ht.insert("Bob", 92);ht.insert("Charlie", 78);// 查找键对应的值std::cout << "Alice的成绩是:" << ht.get("Alice") << std::endl;return 0;
}
运行结果: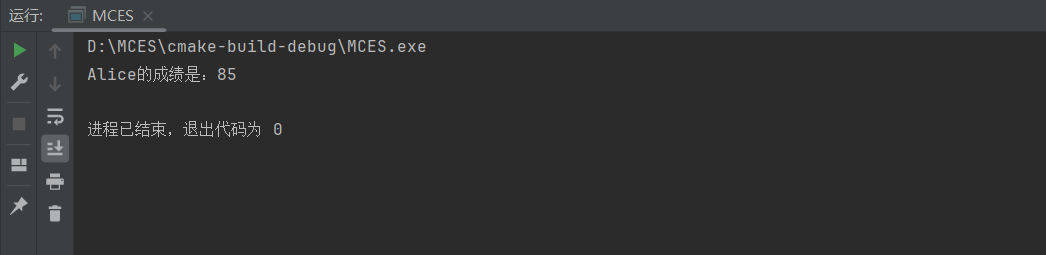
注意:上述示例代码演示了如何创建一个简单的哈希表,用于存储学生的姓名和成绩。实际应用中,哈希表的设计可能更复杂,哈希函数的选择也要根据具体情况进行优化。
![[NSSRound#1 Basic]sql_by_sql - 二次注入+布尔盲注||sqlmap](https://img-blog.csdnimg.cn/1a354c46fcba480b93818bcbebb011de.png)
![[架构之路-231]:计算机硬件与体系结构 - 性能评估汇总,性能优化加速比](https://img-blog.csdnimg.cn/6a11b63010434a90a9b6021ae338edf1.png)