回忆我们需要做的事情:
为了支持 shell 程序的执行,我们需要提供:
1.缺页中断(不理解为什么要这个东西,只是闪客说需要,后边再说)
2.硬盘驱动、文件系统 (shell程序一开始是存放在磁盘里的,所以需要这两个东西)
3.fork,execve, wait 这三个系统调用,也可以说是 进程调度 (否则无法 halt shell 程序并且启动另外的程序)
4.键盘驱动、VGA/console/uart 驱动、中断处理 (支持键盘输入和屏幕显示)
5.内存管理 (shell 启动其它进程时,不能共用内存,而是切换其它进程的页表)
6.为了写代码方便,我们需要从 MBR 进入到 main 函数,这也是从 汇编 切换到 C 语言
7.应用程序申请内存的接口
那么提个问题,为什么 setup.s 不能直接进入 C main ? 而要先进行 head.s ?
一口气读完了闪客文章第八回,第九回,第十回。发现这个东西其实不难,就是比较繁杂琐碎,要查的手册很多。感觉很多东西其实能抄就可以了。
我觉得我们其实可以,先把闪客所有文章都搞明白,在头脑里有个 Linux0.11 的大致脉络,接着再开始写自己的操作系统
head.s 理论上可以丢掉,因为此时 system 已经被加载进内存了,setup.s 可以直接跳转 main 函数的地址过来。但实际上,从工程实现的简化来说,是不应该丢掉的,原因如下:
- setup.s 本身并没有和 C main 链接在一起,所以是没办法使用 main 符号来做函数跳转的
- 在进入 main 函数之前,我们需要把栈给设置好,这个事情结合 C 语言会更容易做一点,而 setup.s 本身和 C 语言并没有链接
- 覆盖 BIOS 设置的中断是在 setup.s 中做的,此时 setup.s 已经把需要 BIOS 中断的事情都做完了。如果没有 setup.s,那么就不能把 head.s 加载到 0x0,否则一上来会直接覆盖掉 BIOS 中断,导致我们没法做那些需要 BIOS 中断才能做的事情(除非自己写代码)
继续看闪客文章 第八回
接下来是对 head.s 所做的事情的一个总结,以下内容来自闪客文章第八回 https://mp.weixin.qq.com/s?__biz=Mzk0MjE3NDE0Ng==&mid=2247499734&idx=1&sn=89045b51e41d2e74754f5475d25d7b54&chksm=c2c5857bf5b20c6d1698df2abd0e1eea601e83612ee6af58dc8eb79f93c751f73d7c62e565ce&scene=178&cur_album_id=2123743679373688834#rd
head.s 文件很短,我们一点点品。
_pg_dir:
_startup_32:mov eax,0x10mov ds,axmov es,axmov fs,axmov gs,axlss esp,_stack_start
注意到开头有个标号 _pg_dir。先留个心眼,这个表示页目录,之后在设置分页机制时,页目录会存放在这里,也会覆盖这里的代码。
再往下连续五个 mov 操作,分别给 ds、es、fs、gs 这几个段寄存器赋值为 0x10,根据段描述符结构解析,表示这几个段寄存器的值为指向全局描述符表中的第二个段描述符,也就是数据段描述符。
最后 lss 指令相当于让 ss:esp 这个栈顶指针指向了 _stack_start 这个标号的位置。还记得图里的那个原来的栈顶指针在哪里吧?往上翻一下,0x9FF00,现在要变咯。
这个 stack_start 标号定义在了很久之后才会讲到的 sched.c 里,我们这里拿出来分析一波。
long user_stack[4096 >> 2];struct
{long *a;short b;
}
stack_start = {&user_stack[4096 >> 2], 0x10};
这啥意思呢?
首先,stack_start 结构中的高位 8 字节是 0x10,将会赋值给 ss 栈段寄存器,低位 16 字节是 user_stack 这个数组的最后一个元素的地址值,将其赋值给 esp 寄存器。 (NOTE: 感觉这里闪客讲错了,高八字节是 user_stack[1024] 的地址,而低16位则是 0x10,赋值给 ss 栈段寄存器)
赋值给 ss 的 0x10 仍然按照保护模式下的段选择子去解读,其指向的是全局描述符表中的第二个段描述符(数据段描述符),段基址是 0。
赋值给 esp 寄存器的就是 user_stack 数组的最后一个元素的内存地址值,那最终的栈顶地址,也指向了这里(user_stack + 0),后面的压栈操作,就是往这个新的栈顶地址处压咯。
继续往下看
call setup_idt ;设置中断描述符表
call setup_gdt ;设置全局描述符表
mov eax,10h
mov ds,ax
mov es,ax
mov fs,ax
mov gs,ax
lss esp,_stack_start
先设置了 idt 和 gdt,然后又重新执行了一遍刚刚执行过的代码。
为什么要重新设置这些段寄存器呢?因为上面修改了 gdt,所以要重新设置一遍以刷新才能生效。那我们接下来就把目光放到设置 idt 和 gdt 上。
中断描述符表 idt 我们之前没设置过,所以这里设置具体的值,理所应当。
setup_idt:lea edx,ignore_intmov eax,00080000hmov ax,dxmov dx,8E00hlea edi,_idtmov ecx,256
rp_sidt:mov [edi],eaxmov [edi+4],edxadd edi,8dec ecxjne rp_sidtlidt fword ptr idt_descrretidt_descr:dw 256*8-1dd _idt_idt:DQ 256 dup(0)
不用细看,我给你说最终效果。
中断描述符表 idt 里面存储着一个个中断描述符,每一个中断号就对应着一个中断描述符,而中断描述符里面存储着主要是中断程序的地址,这样一个中断号过来后,CPU 就会自动寻找相应的中断程序,然后去执行它。
那这段程序的作用就是,设置了 256 个中断描述符,并且让每一个中断描述符中的中断程序例程都指向一个 ignore_int 的函数地址,这个是个默认的中断处理程序,之后会逐渐被各个具体的中断程序所覆盖。比如之后键盘模块会将自己的键盘中断处理程序,覆盖过去。
那现在,产生任何中断都会指向这个默认的函数 ignore_int,也就是说现在这个阶段你按键盘还不好使。
设置中断描述符表 setup_idt 说完了,那接下来 setup_gdt 就同理了。我们就直接看设置好后的新的全局描述符表长什么样吧?
_gdt:DQ 0000000000000000h ;/* NULL descriptor */DQ 00c09a0000000fffh ;/* 16Mb */DQ 00c0920000000fffh ;/* 16Mb */DQ 0000000000000000h ;/* TEMPORARY - don't use */DQ 252 dup(0)
其实和我们原先设置好的 gdt 一模一样。
也是有代码段描述符和数据段描述符,然后第四项系统段描述符并没有用到,不用管。最后还留了 252 项的空间,这些空间后面会用来放置任务状态段描述符 TSS 和局部描述符 LDT,这个后面再说。
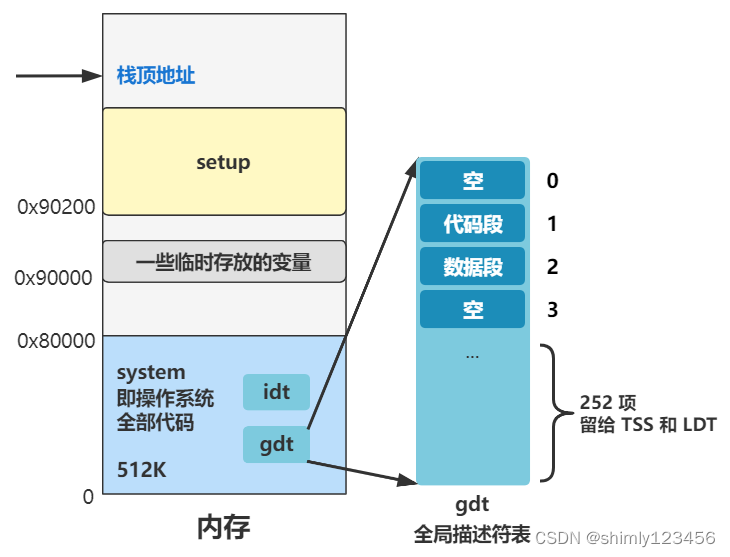
为什么原来已经设置过一遍了,这里又要重新设置一遍,你可千万别想有什么复杂的原因,就是因为原来设置的 gdt 是在 setup 程序中,之后这个地方要被缓冲区覆盖掉,所以这里重新设置在 head 程序中,这块内存区域之后就不会被其他程序用到并且覆盖了,就这么个事。
说的口干舌燥,还是来张图吧。
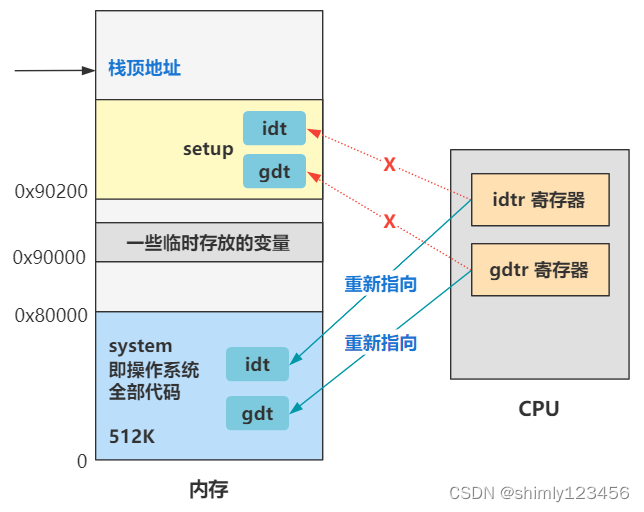
如果你本文的内容完全不能理解,那就记住最后这张图就好了,本文代码就是完成了这个图中所示的一个指向转换而已,并且给所有中断设置了一个默认的中断处理程序 ignore_int,然后全局描述符表仍然只有代码段描述符和数据段描述符。
好了,本文就是两个描述符表位置的变化以及重新设置,再后面一行代码就是又一个令人兴奋的功能了!
jmp after_page_tables
...
after_page_tables:push 0push 0push 0push L6push _mainjmp setup_paging
L6:jmp L6
那就是开启分页机制,并且跳转到 main 函数!
这可太令人兴奋了!开启分页后,配合着之前讲的分段,就构成了内存管理的最最底层的机制。而跳转到 main 函数,标志着我们正式进入 c 语言写的操作系统核心代码!
欲知后事如何,且听下回分解。
继续看闪客文章 第九回
书接上回,上回书咱们说到,head.s 代码在重新设置了 gdt 与 idt 后。
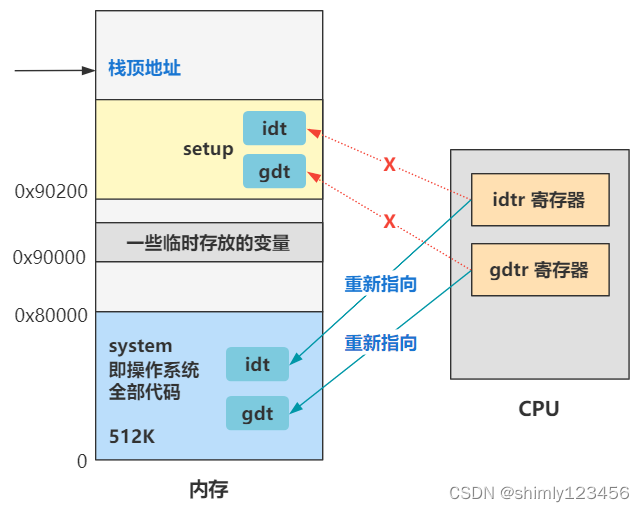
来到了这样一段代码。
jmp after_page_tables
...
after_page_tables:push 0push 0push 0push L6push _mainjmp setup_paging
L6:jmp L6
那就是开启分页机制,并且跳转到 main 函数。
如何跳转到之后用 c 语言写的 main.c 里的 main 函数,是个有趣的事,也包含在这段代码里。不过我们先瞧瞧这分页机制是如何开启的,也就是 setup_paging 这个标签处的代码。
setup_paging:mov ecx,1024*5xor eax,eaxxor edi,edipushfcldrep stosdmov eax,_pg_dirmov [eax],pg0+7mov [eax+4],pg1+7mov [eax+8],pg2+7mov [eax+12],pg3+7mov edi,pg3+4092mov eax,00fff007hstd
L3: stosdsub eax,00001000hjge L3popfxor eax,eaxmov cr3,eaxmov eax,cr0or eax,80000000hmov cr0,eaxret
别怕,我们一点点来分析。
首先要了解的就是,啥是分页机制?
还记不记得之前我们在代码中给出一个内存地址,在保护模式下要先经过分段机制的转换,才能最终变成物理地址,就是这样。
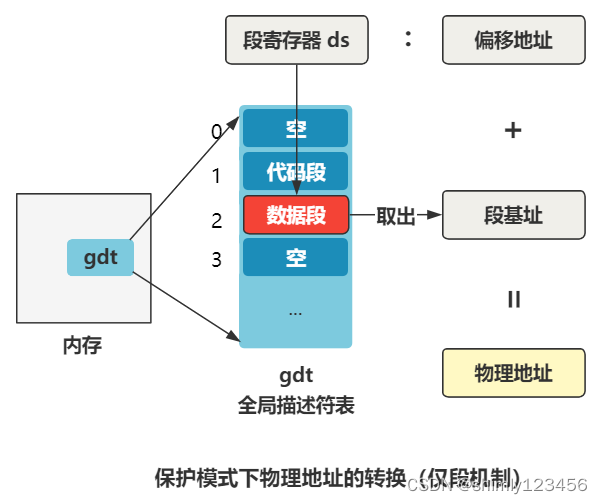
这是在没有开启分页机制的时候,只需要经过这一步转换即可得到最终的物理地址了,但是在开启了分页机制后,又会多一步转换。
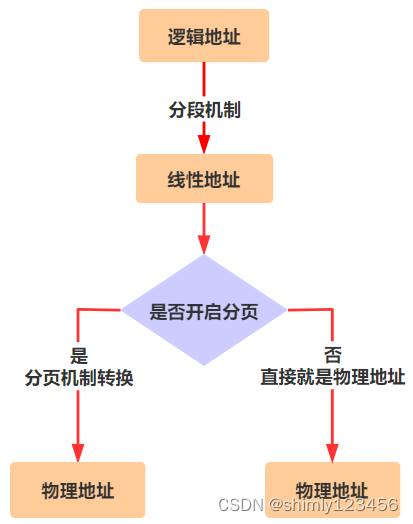
也就是说,在没有开启分页机制时,由程序员给出的逻辑地址,需要先通过分段机制转换成物理地址。但在开启分页机制后,逻辑地址仍然要先通过分段机制进行转换,只不过转换后不再是最终的物理地址,而是线性地址,然后再通过一次分页机制转换,得到最终的物理地址。
分段机制我们已经清楚如何对地址进行变换了,那分页机制又是如何变换的呢?我们直接以一个例子来学习过程。
比如我们的线性地址(已经经过了分段机制的转换)是
15M
二进制表示就是
0000000011_0100000000_000000000000
我们看一下它的转换过程
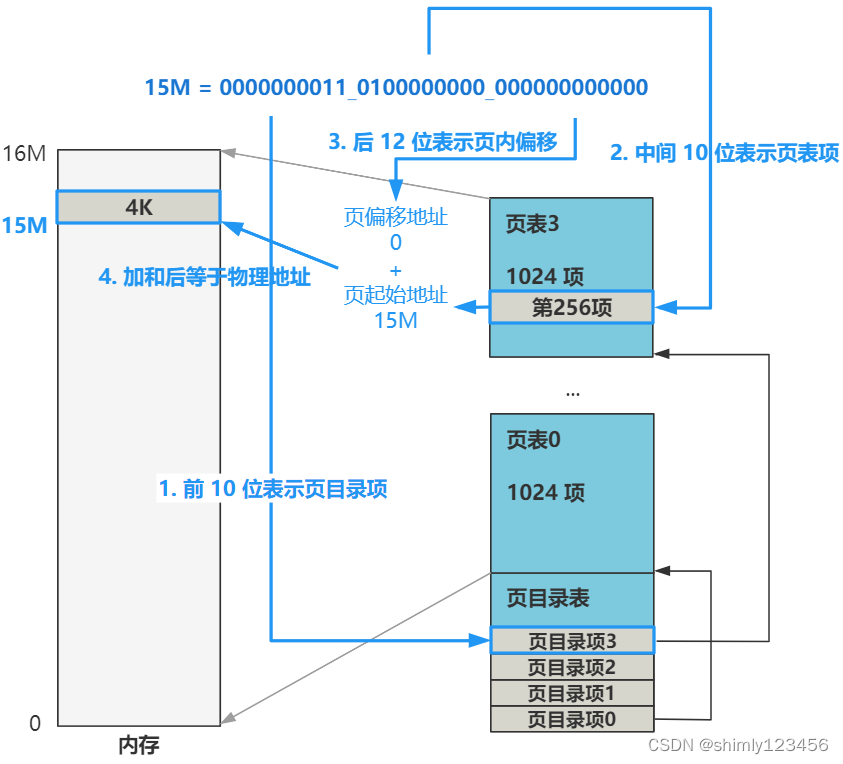
也就是说,CPU 在看到我们给出的内存地址后,首先把线性地址被拆分成
高 10 位:中间 10 位:后 12 位
高 10 位负责在页目录表中找到一个页目录项,这个页目录项的值加上中间 10 位拼接后的地址去页表中去寻找一个页表项,这个页表项的值,再加上后 12 位偏移地址,就是最终的物理地址。
而这一切的操作,都由计算机的一个硬件叫 MMU,中文名字叫内存管理单元,有时也叫 PMMU,分页内存管理单元。由这个部件来负责将虚拟地址转换为物理地址。
所以整个过程我们不用操心,作为操作系统这个软件层,只需要提供好页目录表和页表即可,这种页表方案叫做二级页表,第一级叫页目录表 PDE,第二级叫页表 PTE。他们的结构如下。

之后再开启分页机制的开关。其实就是更改 cr0 寄存器中的一位即可(31 位),还记得我们开启保护模式么,也是改这个寄存器中的一位的值。
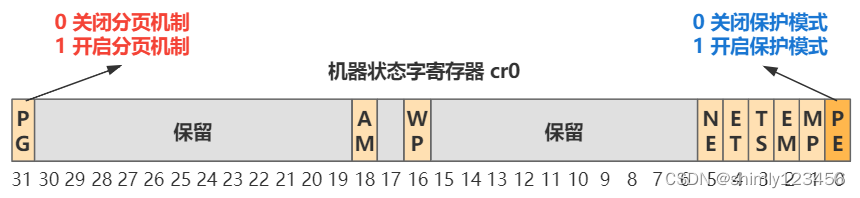
然后,MMU 就可以帮我们进行分页的转换了。此后指令中的内存地址(就是程序员提供的逻辑地址),就统统要先经过分段机制的转换,再通过分页机制的转换,才能最终变成物理地址。
所以这段代码,就是帮我们把页表和页目录表在内存中写好,之后开启 cr0 寄存器的分页开关,仅此而已,我们再把代码贴上来。
setup_paging:mov ecx,1024*5xor eax,eaxxor edi,edipushfcldrep stosdmov eax,_pg_dirmov [eax],pg0+7mov [eax+4],pg1+7mov [eax+8],pg2+7mov [eax+12],pg3+7mov edi,pg3+4092mov eax,00fff007hstd
L3: stosdsub eax,00001000hjge L3popfxor eax,eaxmov cr3,eaxmov eax,cr0or eax,80000000hmov cr0,eaxret
我们先说这段代码最终产生的效果吧。
当时 linux-0.11 认为,总共可以使用的内存不会超过 16M,也即最大地址空间为 0xFFFFFF。
而按照当前的页目录表和页表这种机制,1 个页目录表最多包含 1024 个页目录项(也就是 1024 个页表),1 个页表最多包含 1024 个页表项(也就是 1024 个页),1 页为 4KB(因为有 12 位偏移地址),因此,16M 的地址空间可以用 1 个页目录表 + 4 个页表搞定。
4(页表数)* 1024(页表项数) * 4KB(一页大小)= 16MB
所以,上面这段代码就是,将页目录表放在内存地址的最开头,还记得上一讲开头让你留意的 _pg_dir 这个标签吧?
_pg_dir:
_startup_32:mov eax,0x10mov ds,ax...
之后紧挨着这个页目录表,放置 4 个页表,代码里也有这四个页表的标签项。
.org 0x1000 pg0:
.org 0x2000 pg1:
.org 0x3000 pg2:
.org 0x4000 pg3:
.org 0x5000
最终将页目录表和页表填写好数值,来覆盖整个 16MB 的内存。随后,开启分页机制。此时内存中的页表相关的布局如下。
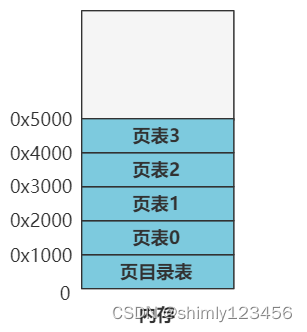
这些页目录表和页表放到了整个内存布局中最开头的位置,就是覆盖了开头的 system 代码了,不过被覆盖的 system 代码已经执行过了,所以无所谓。
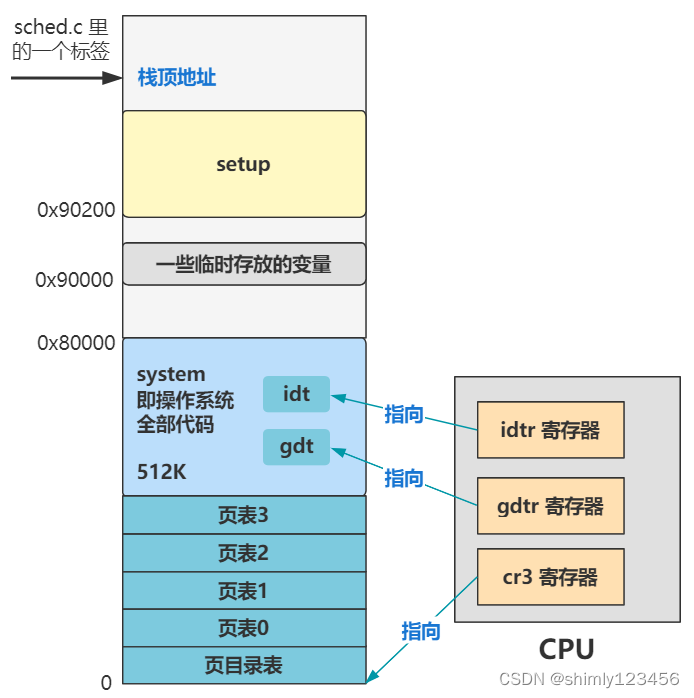
同时,如 idt 和 gdt 一样,我们也需要通过一个寄存器告诉 CPU 我们把这些页表放在了哪里,就是这段代码。
xor eax,eax
mov cr3,eax
你看,我们相当于告诉 cr3 寄存器,0 地址处就是页目录表,再通过页目录表可以找到所有的页表,也就相当于 CPU 知道了分页机制的全貌了。
至此后,整个内存布局如下。
那么具体页表设置好后,映射的内存是怎样的情况呢?那就要看页表的具体数据了,就是这一坨代码。
setup_paging:...mov eax,_pg_dirmov [eax],pg0+7mov [eax+4],pg1+7mov [eax+8],pg2+7mov [eax+12],pg3+7mov edi,pg3+4092mov eax,00fff007hstd
L3: stosdsub eax, 1000hjpe L3...
很简单,对照刚刚的页目录表与页表结构看。

前五行表示,页目录表的前 4 个页目录项,分别指向 4 个页表。比如页目录项中的第一项 [eax] 被赋值为 pg0+7,也就是 0x00001007,根据页目录项的格式,表示页表地址为 0x1000,页属性为 0x07 表示改页存在、用户可读写。
后面几行表示,填充 4 个页表的每一项,一共 4*1024=4096 项,依次映射到内存的前 16MB 空间。
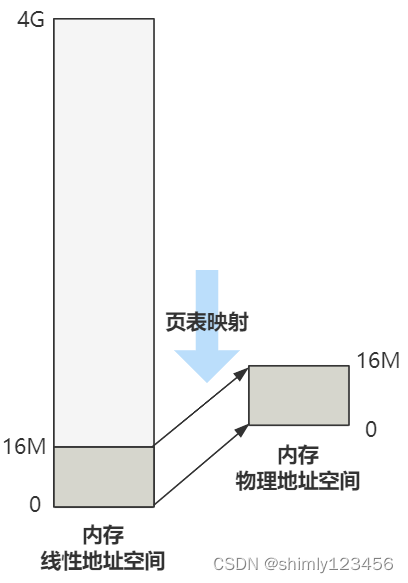
画出图就是这个样子,其实刚刚的图就是。
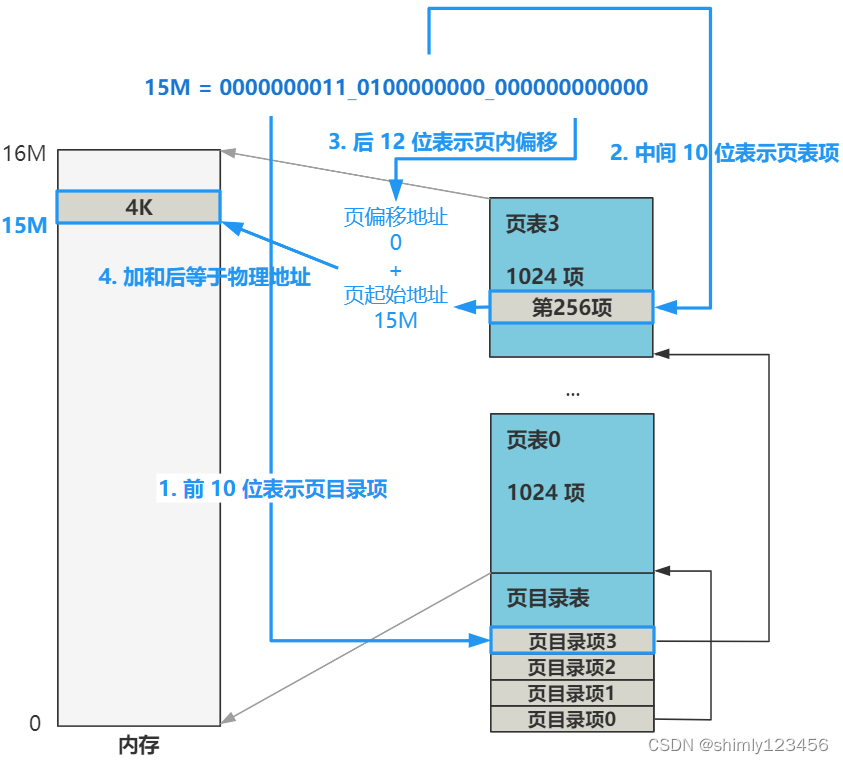
看,最终的效果就是,经过这套分页机制,线性地址将恰好和最终转换的物理地址一样。
现在只有四个页目录项,也就是将前 16M 的线性地址空间,与 16M 的物理地址空间一一对应起来了。
好了,我知道你目前可能有点晕头转向,关于地址,我们已经出现了好多词了,包括逻辑地址、线性地址、物理地址,以及本文中没出现的,你可能在很多地方看到过的虚拟地址。
而这些地址后面加上空间两个字,似乎又成为了一个新词,比如线性地址空间、物理地址空间、虚拟地址空间等。
那就是时候展开一波讨论,将这块的内容梳理一番了,且听我说。
Intel 体系结构的内存管理可以分成两大部分,也就是标题中的两板斧,分段和分页。
分段机制在之前几回已经讨论过多次了,其目的是为了为每个程序或任务提供单独的代码段(cs)、数据段(ds)、栈段(ss),使其不会相互干扰。
分页机制是本回讲的内容,开机后分页机制默认是关闭状态,需要我们手动开启,并且设置好页目录表(PDE)和页表(PTE)。其目的在于可以按需使用物理内存,同时也可以在多任务时起到隔离的作用,这个在后面将多任务时将会有所体会。
在 Intel 的保护模式下,分段机制是没有开启和关闭一说的,它必须存在,而分页机制是可以选择开启或关闭的。所以如果有人和你说,它实现了一个没有分段机制的操作系统,那一定是个外行。
再说说那些地址:
逻辑地址:我们程序员写代码时给出的地址叫逻辑地址,其中包含段选择子和偏移地址两部分。
线性地址:通过分段机制,将逻辑地址转换后的地址,叫做线性地址。而这个线性地址是有个范围的,这个范围就叫做线性地址空间,32 位模式下,线性地址空间就是 4G。
物理地址:就是真正在内存中的地址,它也是有范围的,叫做物理地址空间。那这个范围的大小,就取决于你的内存有多大了。
虚拟地址:如果没有开启分页机制,那么线性地址就和物理地址是一一对应的,可以理解为相等。如果开启了分页机制,那么线性地址将被视为虚拟地址,这个虚拟地址将会通过分页机制的转换,最终转换成物理地址。
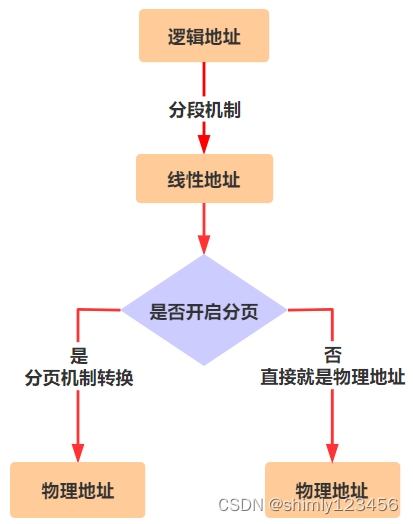
但实际上,我本人是不喜欢虚拟地址这个叫法的,因为它在 Intel 标准手册上出现的次数很少,我觉得知道逻辑地址、线性地址、物理地址这三个概念就够了,逻辑地址是程序员给出的,经过分段机制转换后变成线性地址,然后再经过分页机制转换后变成物理地址,就这么简单。
好了,我们终于把这些杂七杂八的,idt、gdt、页表都设置好了,并且也开启了保护模式,之后我们就要做好进入 main.c 的准备了,那里是个新世界!
不过进入 main.c 之前还差最后一哆嗦,就是 head.s 最后的代码,也就是本文开头的那段代码。
jmp after_page_tables
...
after_page_tables:push 0push 0push 0push L6push _mainjmp setup_paging
L6:jmp L6
看到没,这里有个 push _main,把 main 函数的地址压栈了,那最终跳转到这个 main.c 里的 main 函数,一定和这个压栈有关。
压栈为什么和跳转到这里还能联系上呢?留作本文思考题,下一篇将揭秘这个过程,你会发现仍然简单得要死。
欲知后事如何,且听下回分解。 (能猜到为什么把 main 压栈,ret 会使用栈指针指向的地址来做跳转)
此外, call 指令会自动把 PC+4 压入栈中
继续看闪客文章 第十回
书接上回,上回书咱们说到,我们终于把这些杂七杂八的,idt、gdt、页表都设置好了,并且也开启了保护模式,相当于所有苦力活都做好铺垫了,之后我们就要准备进入 main.c!那里是个新世界!
注意不是进入,而是准备进入哦,就差一哆嗦了。
由于上一讲的知识量非常大,所以这一讲将会非常简单,作为进入 main 函数前的衔接,大家放宽心。
这仍然要回到上一讲我们跳转到设置分页代码的那个地方(head.s 里),这里有个骚操作帮我们跳转到 main.c。
after_page_tables:push 0push 0push 0push L6push _mainjmp setup_paging
...
setup_paging:...ret
直接解释起来非常简单。
push 指令就是压栈,五个 push 指令过去后,栈会变成这个样子。
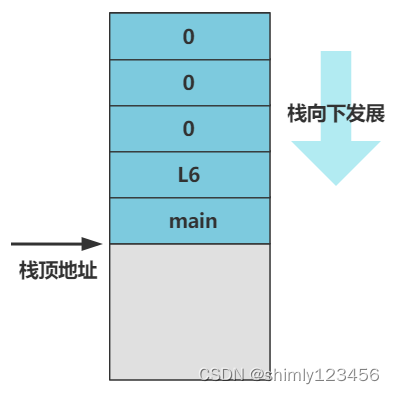
然后注意,setup_paging 最后一个指令是 ret,也就是我们上一回讲的设置分页的代码的最后一个指令,形象地说它叫返回指令,但 CPU 可没有那么聪明,它并不知道该返回到哪里执行,只是很机械地把栈顶的元素值当做返回地址,跳转去那里执行。
再具体说是,把 esp 寄存器(栈顶地址)所指向的内存处的值,赋值给 eip 寄存器,而 cs:eip 就是 CPU 要执行的下一条指令的地址。而此时栈顶刚好是 main.c 里写的 main 函数的内存地址,是我们刚刚特意压入栈的,所以 CPU 就理所应当跳过来了。
当然 Intel CPU 是设计了 call 和 ret 这一配对儿的指令,意为调用函数和返回,具体可以看后面本回扩展资料里的内容。
至于其他压入栈的 L6 是用作当 main 函数返回时的跳转地址,但由于在操作系统层面的设计上,main 是绝对不会返回的,所以也就没用了。而其他的三个压栈的 0,本意是作为 main 函数的参数,但实际上似乎也没有用到,所以也不必关心。
总之,经过这一个小小的骚操作,程序终于跳转到 main.c 这个由 c 语言写就的主函数 main 里了!我们先一睹为快一下。
void main(void) {ROOT_DEV = ORIG_ROOT_DEV;drive_info = DRIVE_INFO;memory_end = (1<<20) + (EXT_MEM_K<<10);memory_end &= 0xfffff000;if (memory_end > 16*1024*1024)memory_end = 16*1024*1024;if (memory_end > 12*1024*1024) buffer_memory_end = 4*1024*1024;else if (memory_end > 6*1024*1024)buffer_memory_end = 2*1024*1024;elsebuffer_memory_end = 1*1024*1024;main_memory_start = buffer_memory_end;mem_init(main_memory_start,memory_end);trap_init();blk_dev_init();chr_dev_init();tty_init();time_init();sched_init();buffer_init(buffer_memory_end);hd_init();floppy_init();sti();move_to_user_mode();if (!fork()) {init();}for(;;) pause();
}
没错,这就是这个 main 函数的全部了。
而整个操作系统也会最终停留在最后一行死循环中,永不返回,直到关机。
好了,至此,整个第一部分就圆满结束了,为了跳进 main 函数的准备工作,我称之为进入内核前的苦力活,就完成了!我们看看我们做了什么。
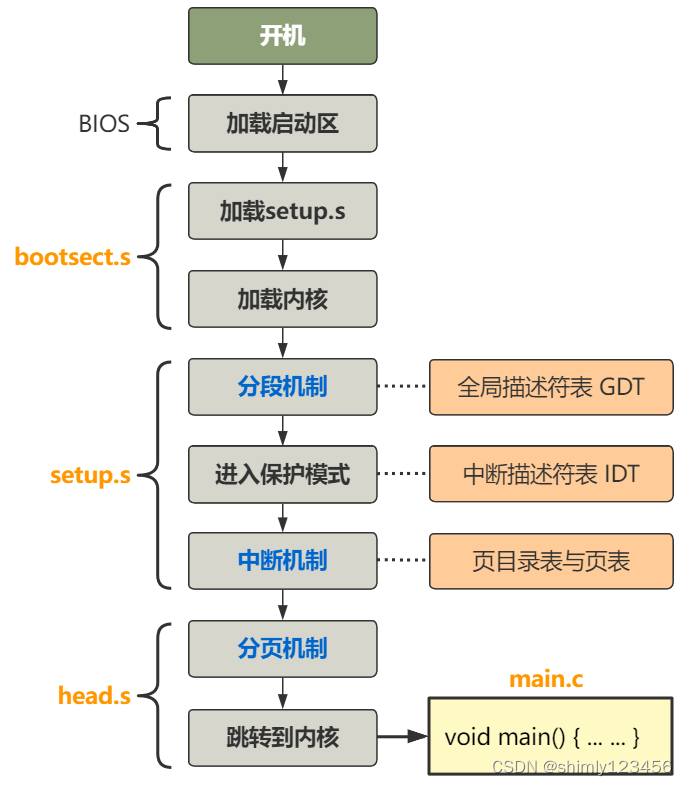
我把这些称为进入内核前的苦力活,经过这样的流程,内存被搞成了这个样子。
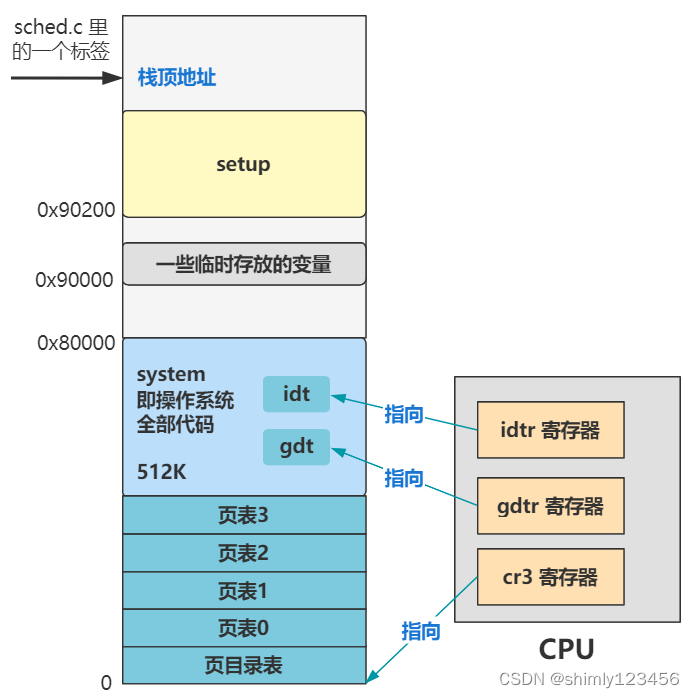
之后,main 方法就开始执行了,靠着我们辛辛苦苦建立起来的内存布局,向崭新的未来前进!
欲知后事如何,且听下回分解。
总结来说,head.s 做的事情包括:
- 设置内核要使用的栈段和栈指针
- 初始化 idt (触发中断什么也不干)
- 再次设置 gdt (原先 gdt 的位置后面很可能会被覆盖掉)
- 设置页表基寄存器
- 开启分页 MMU
- 进入 main 函数 (使用 push main + ret)

![[C国演义] 第十三章](https://img-blog.csdnimg.cn/d9080d84e70240d6b48d8a5fbd82b6f3.png)