DeepWalk

使用随机游走采样得到每个结点x的上下文信息,记作Context(x)。
SkipGram优化的目标函数:P(Context(x)|x;θ)
θ = argmax P(Context(x)|x;θ)
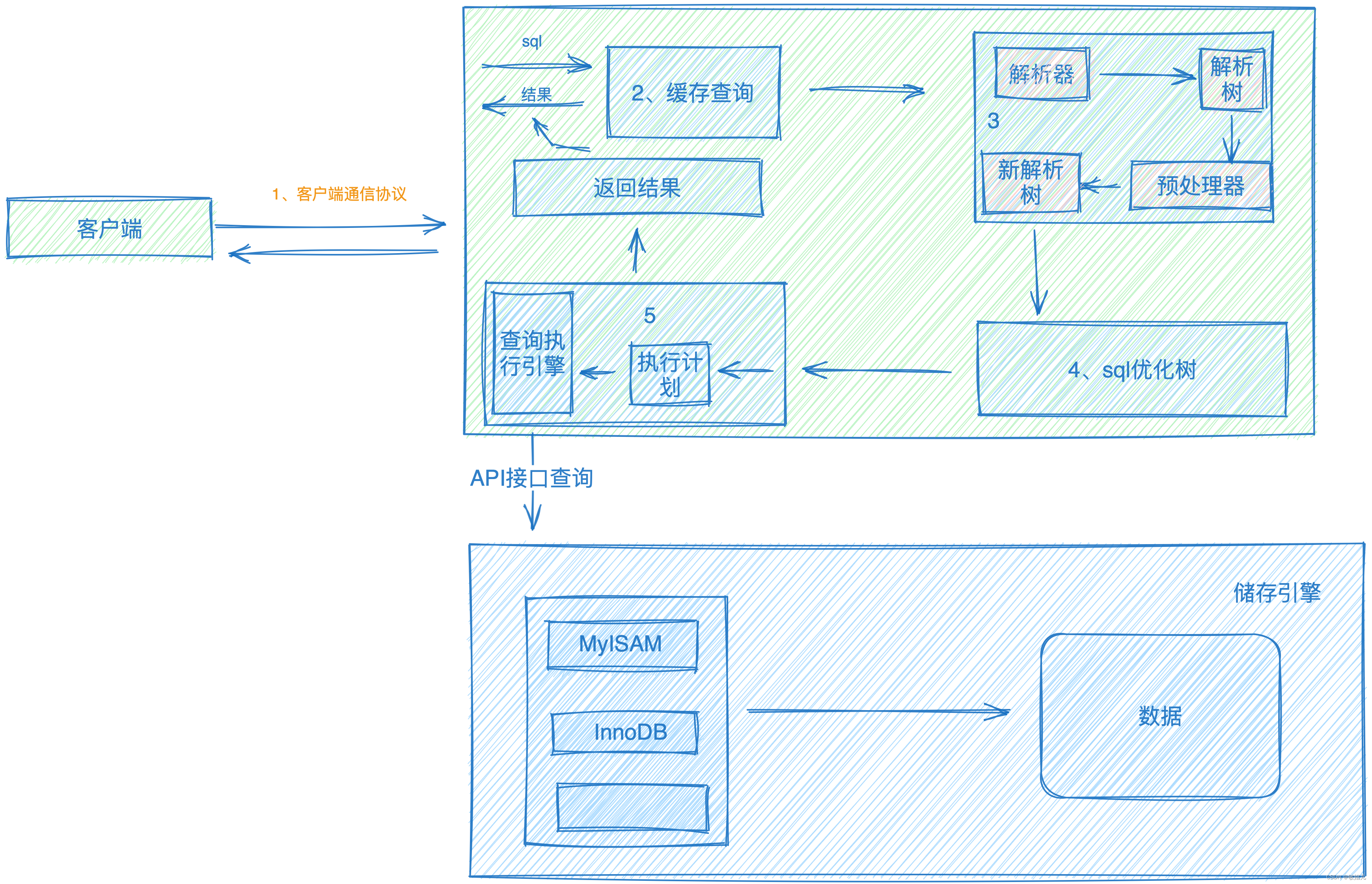
DeepWalk这种GraphEmbedding方法是一种无监督方法,个人理解有点类似生成模型的Encoder过程,下面的代码中,node_proj是一个简单的线性映射函数,加上elu激活函数,可以看作Encoder的过程。Encoder结束后就得到了Embedding后的隐变量表示。其实GraphEmbedding要的就是这个node_proj,但是由于没有标签,只有训练数据的内部特征,怎么去训练呢?这就需要看我们的训练任务了,个人理解,也就是说,这种无监督的embedding后的结果取决于你的训练任务,也就是Decoder过程。Embedding后的编码对Decoder过程越有利,损失函数也就越小,编码做的也就越好。在word2vec中,有两种训练任务,一种是给定当前词,预测其前两个及后两个词发生的条件概率,采用这种训练任务做出的embedding就是skip-gram;还有一种是给定当前词前两个及后两个词,预测当前词出现的条件概率,采用这种训练任务做出的embedding就是CBOW.DeepWalk作者的论文中采用的是skip-gram。故复现也采用skip-gram进行复现。
针对skip-gram对应的训练任务,代码中的node_proj相当于编码器,h_o_1和h_o_2相当于解码器。Encoder和Decoder可以先联合训练,训练结束后,可以只保留Encoder的部分,舍弃Decoder的部分。当再来一个独热编码的时候,可以直接通过node_proj映射,即完成了独热编码的embedding过程。
(本代码假定在当前结点去往各邻接结点的可能性相同,即不考虑边的权重)
import pandas as pd
import torch
import torch.nn as nn
import numpy as np
import random
import torch.nn.functional as F
import networkx as nx
from torch.nn import CrossEntropyLoss
from torch.optim.lr_scheduler import CosineAnnealingLR
from torch.distributions import Categorical
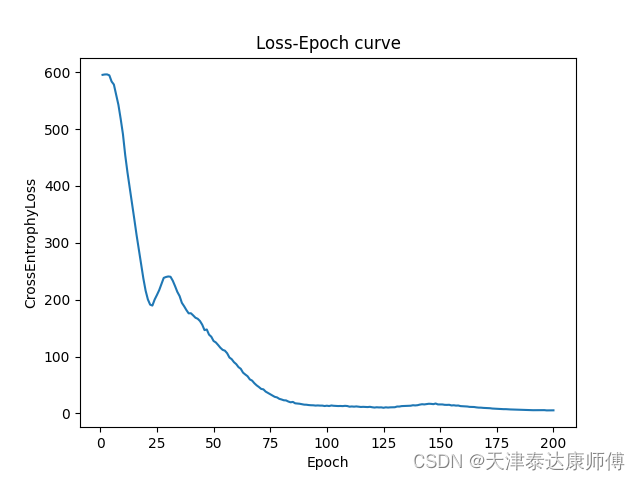
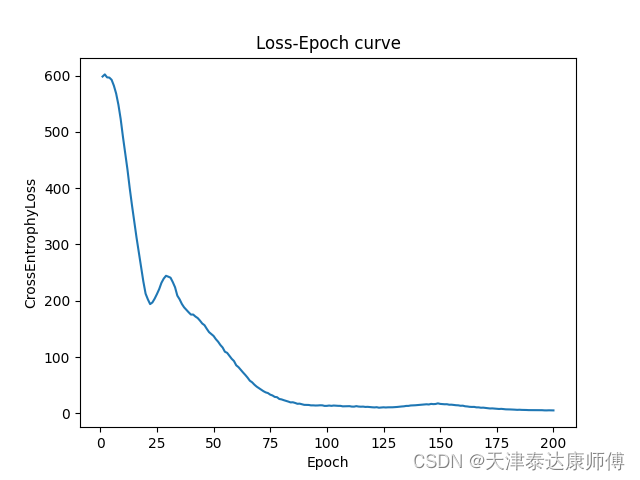
import matplotlib.pyplot as pltclass MyGraph():def __init__(self,device):super(MyGraph, self).__init__()self.G = nx.read_edgelist(path='data/wiki/Wiki_edgelist.txt',create_using=nx.DiGraph(),nodetype=None,data=[('weight',int)])self.adj_matrix = nx.attr_matrix(self.G)self.edges = nx.edges(self.G)self.edges_emb = torch.eye(len(self.G.edges)).to(device)self.nodes_emb = torch.eye(len(self.G.nodes)).to(device)class GraphEmbedding(nn.Module):def __init__(self,nodes_num,edges_num,device,emb_dim = 10):super(GraphEmbedding, self).__init__()self.device = deviceself.nodes_proj = nn.Parameter(torch.randn(nodes_num,emb_dim))self.edges_proj = nn.Parameter(torch.randn(edges_num,emb_dim))self.h_o_1 = nn.Parameter(torch.randn(emb_dim,nodes_num * 2))self.h_o_2 = nn.Parameter(torch.randn(nodes_num * 2,nodes_num))def forward(self,G:MyGraph):self.nodes_proj,self.edges_proj = self.nodes_proj.to(self.device),self.edges_proj.to(device)self.h_o_1,self.h_o_2 = self.h_o_1.to(self.device),self.h_o_2.to(self.device)# Encoderedges_emb,nodes_emb = torch.matmul(G.edges_emb,self.edges_proj),torch.matmul(G.nodes_emb,self.nodes_proj)nodes_emb = F.elu_(nodes_emb)edges_emb,nodes_emb = edges_emb.to(device),nodes_emb.to(device)# Decoderpolicy = self.DeepWalk(G,gamma=5,window=2)outputs = torch.matmul(torch.matmul(nodes_emb[policy[:,0]],self.h_o_1),self.h_o_2)policy,outputs = policy.to(device),outputs.to(device)return policy,outputsdef DeepWalk(self,Graph:MyGraph,gamma:int,window:int,eps=1e-9):# Calculate transpose matrixadj_matrix = torch.tensor(Graph.adj_matrix[0], dtype=torch.float32)for i in range(adj_matrix.shape[0]):adj_matrix[i,:] /= (torch.sum(adj_matrix[i]) + eps)adj_nodes = Graph.adj_matrix[1].copy()random.shuffle(adj_nodes)nodes_idx, route_result = [],[]for node in adj_nodes:node_idx = np.where(np.array(Graph.adj_matrix[1]) == node)[0].item()node_list = self.Random_Walk(adj_matrix,window=window,node_idx=node_idx)route_result.append(node_list)return torch.tensor(route_result)def Random_Walk(self,adj_matrix:torch.Tensor,window:int,node_idx:int):node_list = [node_idx]for i in range(window):pi = self.HMM_process(adj_matrix,node_idx)if torch.sum(pi) == 0:pi += 1 / pi.shape[0]node_idx = Categorical(pi).sample().item()node_list.append(node_idx)return node_listdef HMM_process(self,adj_matrix:torch.Tensor,node_idx:int,eps=1e-9):pi = torch.zeros((1, adj_matrix.shape[0]), dtype=torch.float32)pi[:,node_idx] = 1.0pi = torch.matmul(pi,adj_matrix)pi = pi.squeeze(0) / (torch.sum(pi) + eps)return piif __name__ == "__main__":epochs = 200device = torch.device("cuda:1")cross_entrophy_loss = CrossEntropyLoss().to(device)Graph = MyGraph(device)Embedding = GraphEmbedding(nodes_num=len(Graph.G.nodes), edges_num=len(Graph.G.edges),device=device).to(device)optimizer = torch.optim.Adam(Embedding.parameters(),lr=1e-5)scheduler=CosineAnnealingLR(optimizer,T_max=50,eta_min=0.05)loss_list = []epoch_list = [i for i in range(1,epochs+1)]for epoch in range(epochs):policy,outputs = Embedding(Graph)outputs = outputs.unsqueeze(1).repeat(1,policy.shape[-1]-1,1).reshape(-1,outputs.shape[-1])optimizer.zero_grad()loss = cross_entrophy_loss(outputs, policy[:,1:].reshape(-1))loss.backward()optimizer.step()scheduler.step()loss_list.append(loss.item())print(f"Loss : {loss.item()}")plt.plot(epoch_list,loss_list)plt.xlabel('Epoch')plt.ylabel('CrossEntrophyLoss')plt.title('Loss-Epoch curve')plt.show()
Node2Vec
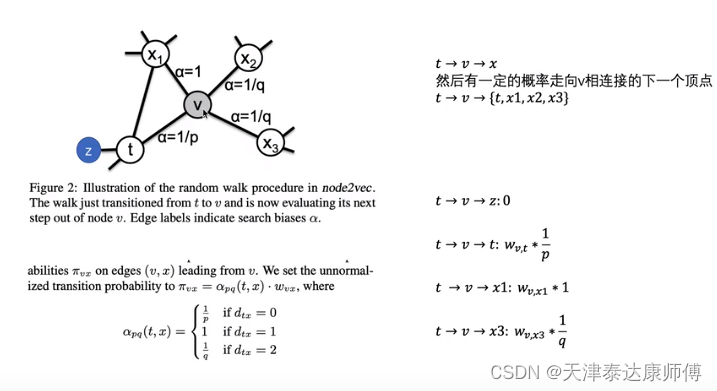

修改Random_Walk函数如下:
def Random_Walk(self,adj_matrix:torch.Tensor,window:int,node_idx:int):node_list = [node_idx]for i in range(window):pi = self.HMM_process(adj_matrix,node_idx)if torch.sum(pi) == 0:pi += 1 / pi.shape[0]if i > 0:v,t = node_list[-1],node_list[-2]x_list = torch.nonzero(adj_matrix[v]).squeeze(-1)for x in x_list:if t == x: # 0pi[x] *= 1/self.pelif adj_matrix[t][x] == 1: # 1pi[x] *= 1else: # 2pi[x] *= 1/self.qnode_idx = Categorical(pi).sample().item()node_list.append(node_idx)return node_list
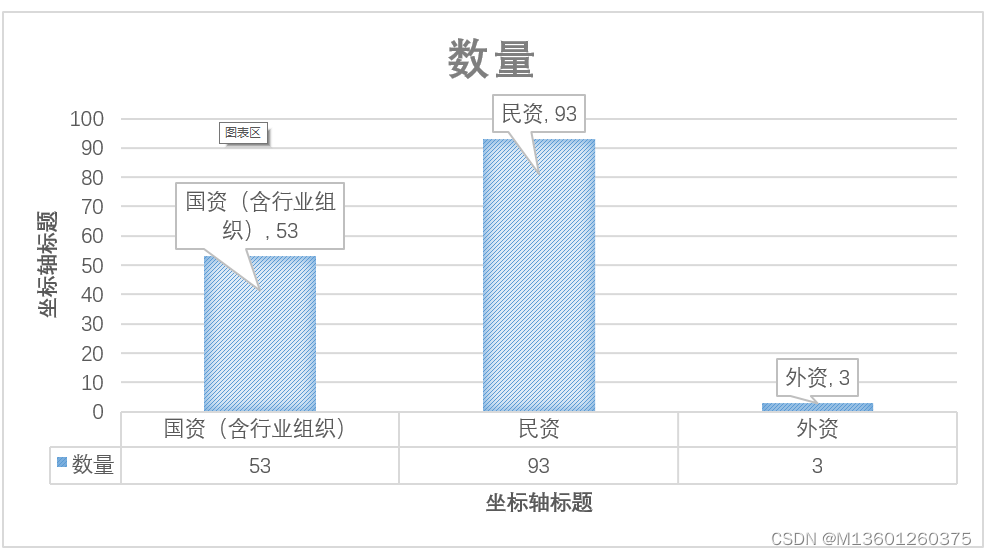
结果如下,这里令p=2,q=3,即1/p=0.5,1/q=0.33,会相对保守周围。结果似乎好了那么一点点。