目录
- 1. 题目
- 1.1 存储过程
- 1.2 存储函数
- 1.3 事务处理
- 2. 解答
- 2.1 存储过程
- 2.2 存储函数
- 2.3 事务处理
1. 题目
1.1 存储过程
-
创建表
RandNumber:字段:id自增长,data int; 创建存储过程向表中插入指定个数的随机数(1-99),但如果插入的数为50,则终止插入。 -
创建存储过程,根据员工的工作时间,如果大于
6年时,将其转到经理办公室工作,并调用该存储过程。 -
创建存储过程,比较两个员工的实际收入,若前者比后者高输出
1,若两者相等输出0,若后者比前者高输出-1,并调用该存储过程。 -
创建存储过程
p(in name char(10),out income decimal(7,2)),计算一个员工的实际收入,并调用该存储过程,将员工 朱骏 的实际收入保存在一个用户变量中。 -
创建存储过程
raise(in edu char(6),in x decimal(5,1))将所有某种学历的员工的收入提高%x, 并调用该存储过程,将所有硕士学历的员工的收入提高10%。
1.2 存储函数
-
创建存储函数
getAver(did int),计算某个部门的平均工资(实际收入); -
调用该函数,显示平均工资最高和最低的部门名称。
1.3 事务处理
设置事务处理为手动提交,建立两个连接。
-
观察
@@transaction_isolation设置为read-uncommited时,脏读的情况。
1)在一个连接A中,设置@@transaction_isolation设置为read-uncommited,开始事务,显示employees表中‘ 王林 ’员工信息;
2)在另一个连接B中,修改‘ 王林 ’的workYear为10年;
3)在连接A中显示employees表的员工信息,观察‘王林’的workYear;
4)在一个连接B中,回滚刚才的修改操作;
5)在连接A中显示employees表的员工信息,观察‘王林’的workYear。 -
观察
@@transaction_isolation设置为read-commited时,不可重复读的情况。
1)在一个连接A中,设置@@transaction_isolation设置为read-commited;
2)开始事务,显示employees表中‘王林’员工信息;
3)在另一个连接B中,修改‘王林’的workYear为10年;
4)在连接A中显示employees表的员工信息,观察‘王林’的workYear;
5)在一个连接B中,提交刚才的修改操作;
6)在连接A中显示employees表的员工信息,观察‘王林’的workYear,提交事务。 -
观察
@@transaction_isolation设置为repeatable-read时,幻读的情况。
1)在一个连接A中,设置@@transaction_isolation设置为repeatable-read;
2)开始事务,显示employees表中所有员工信息,观察记录的数目;
3)在另一个连接B中,在employees表插入一条记录,并提交事务;
4)在连接A中显示employees表的员工信息,观察记录的数目;
5)在连接A中,将所有员工的workYear增加一年,观察被修改的记录的数目;
6)在连接A中提交事务;
8)在连接A再次显示employees表中所有员工信息,观察记录的数目; -
设置
@@transaction_isolation设置为serializable;
重复第3个实验的操作,观察操作中出现的现象。
2. 解答
2.1 存储过程
use yggl;
-
创建表
RandNumber:字段:id自增长,data int; 创建存储过程向表中插入指定个数的随机数(1-99),但如果插入的数为50,则终止插入。drop table if EXISTS `yggl`.`RandNumber`; CREATE TABLE if not EXISTS`yggl`.`RandNumber` (`id` int NOT NULL AUTO_INCREMENT,`data` int NOT NULL,PRIMARY KEY (`id`) );drop PROCEDURE if EXISTS p_RandNumber; delimiter $ create procedure p_RandNumber(in n int) begindeclare temp int;declare i int default(1);set temp = 1 + floor(rand()*99);while i <= n and temp != 50 doinsert into randnumber values (null, temp);set temp = 1 + floor(rand()*99);set i = i + 1;end while; end$ delimiter ;set @n=100; call p_RandNumber(@n); select * from randnumber; -
创建存储过程,根据员工的工作时间,如果大于
6年时,将其转到经理办公室工作,并调用该存储过程。drop PROCEDURE if EXISTS p2; delimiter $ create procedure p2() begindeclare did char(3); # 部门编号declare eid char(6); # 员工编号select departments.DepartmentID into didfrom departmentswhere departments.DepartmentName = '经理办公室';select employees.EmployeeID into eidfrom employeeswhere employees.WorkYear > 6;update employeesset DepartmentID = didwhere employees.EmployeeID in(eid); end$ delimiter ;call p2(); -
创建存储过程,比较两个员工的实际收入,若前者比后者高输出
1,若两者相等输出0,若后者比前者高输出-1,并调用该存储过程。drop PROCEDURE if EXISTS p3; delimiter $ create procedure p3(in mname1 char(10), in mname2 char(10)) begindeclare m1 float; # 第一个人的实际收入declare m2 float; # 第二个人的实际收入declare flag int; # 1,0,-1select salary.InCome - salary.OutCome into m1from salary join employees on salary.EmployeeID = employees.EmployeeIDwhere employees.`Name` = mname1;select salary.InCome - salary.OutCome into m2from salary join employees on salary.EmployeeID = employees.EmployeeIDwhere employees.`Name` = mname2;if m1 > m2 thenset flag = 1;elseif m1 = m2 thenset flag = 0;elseset flag = -1;end if;select flag; end$ delimiter ;call p3('王浩', '伍容华'); -
创建存储过程
p(in name char(10),out income decimal(7,2)),计算一个员工的实际收入,并调用该存储过程,将员工 朱骏 的实际收入保存在一个用户变量中。drop PROCEDURE if EXISTS p; delimiter $ create procedure p(in `name` char(10),out income decimal(7,2)) beginselect salary.InCome - salary.OutCome into incomefrom salary join employees on salary.EmployeeID = employees.EmployeeIDwhere employees.`Name` = `name`;end$ delimiter ;set @c=1; call p('朱骏', @c); select @c; -
创建存储过程
raise(in edu char(6),in x decimal(5,1))将所有某种学历的员工的收入提高%x, 并调用该存储过程,将所有硕士学历的员工的收入提高10%。drop PROCEDURE if EXISTS raise; delimiter $ create procedure raise(in edu char(6), in x decimal(5,1)) beginupdate salaryset salary.InCome = salary.InCome*(1+x/100)where EmployeeID in(select employees.EmployeeIDfrom employeeswhere employees.Education = edu); end$ delimiter ;call raise('硕士', 10);
2.2 存储函数
-
创建存储函数
getAver(did int),计算某个部门的平均工资(实际收入);set GLOBAL log_bin_trust_function_creators = 1; # 一共只需要设置一次drop FUNCTION if exists getAver; delimiter $ create FUNCTION getAver(did int) returns float # 返回某个部门的平均工资(实际收入) begindeclare aver float;select AVG(salary.InCome - salary.OutCome) into averfrom employees join salary on employees.EmployeeID = salary.EmployeeIDwhere employees.DepartmentID = did;return aver; end$ delimiter ; -
调用该函数,显示平均工资最高和最低的部门名称。
# 平均工资最高的部门 select departments.DepartmentName, getAver(departments.DepartmentID) as avg_salary from departments ORDER BY avg_salary desc limit 1; # 平均工资最低的部门 select departments.DepartmentName, getAver(departments.DepartmentID) as avg_salary from departments ORDER BY avg_salary asc limit 1;
2.3 事务处理
设置事务处理为手动提交,建立两个连接。
set @@autocommit = 0;

-
观察
@@transaction_isolation设置为read-uncommited时,脏读的情况。
1)在一个连接A中,设置@@transaction_isolation设置为read-uncommited,开始事务,显示employees表中‘ 王林 ’员工信息;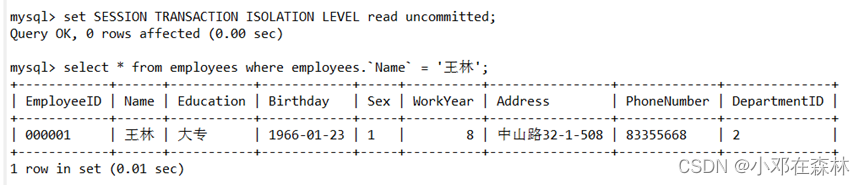
2)在另一个连接
B中,修改‘ 王林 ’的workYear为10年;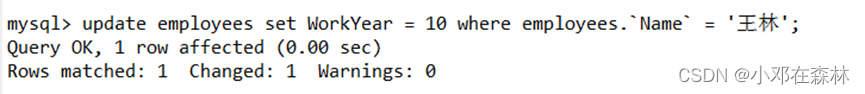
3)在连接
A中显示employees表的员工信息,观察‘王林’的workYear;
4)在一个连接
B中,回滚刚才的修改操作;
5)在连接
A中显示employees表的员工信息,观察‘王林’的workYear。
结论:一个事务
B读取了另一个未提交的并行事务A写的数据。【脏读】 -
观察
@@transaction_isolation设置为read-commited时,不可重复读的情况。
1)在一个连接A中,设置@@transaction_isolation设置为read-commited;
2)开始事务,显示
employees表中‘王林’员工信息;
3)在另一个连接
B中,修改‘王林’的workYear为10年;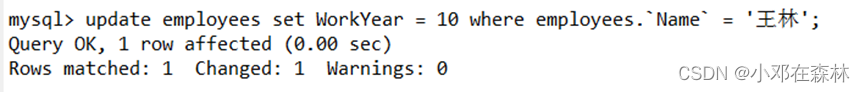
4)在连接
A中显示employees表的员工信息,观察‘王林’的workYear;
5)在一个连接
B中,提交刚才的修改操作;
6)在连接
A中显示employees表的员工信息,观察‘王林’的workYear,提交事务。
结论:一个事务A重新读取前面读取过的数据,发现该数据已经被另一个已提交的事务B修改过。【不可重复读】
-
观察
@@transaction_isolation设置为repeatable-read时,幻读的情况。
1)在一个连接A中,设置@@transaction_isolation设置为repeatable-read;
2)开始事务,显示
employees表中所有员工信息,观察记录的数目;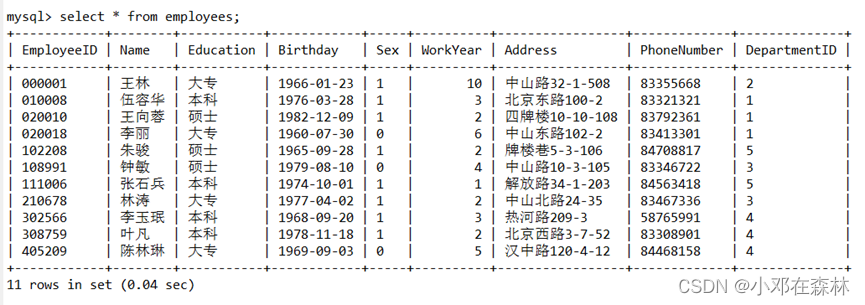
3)在另一个连接
B中,在employees表插入一条记录,并提交事务;
4)在连接
A中显示employees表的员工信息,观察记录的数目;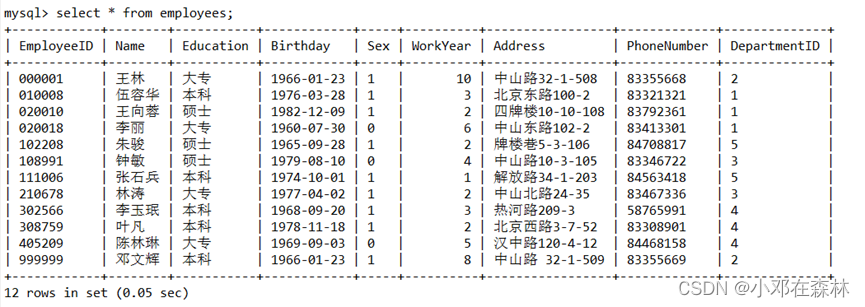
5)在连接
A中,将所有员工的workYear增加一年,观察被修改的记录的数目;
6)在连接
A中提交事务;
7)在连接
A再次显示employees表中所有员工信息,观察记录的数目;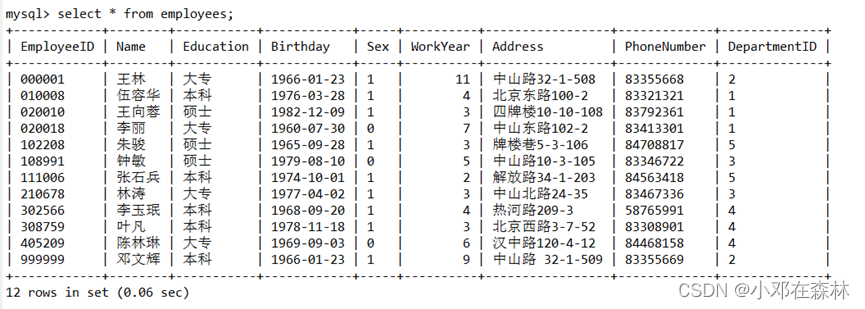
结论:一个事务重新执行一个查询,返回一套符合查询条件的行, 发现这些行因为其他最近提交的事务而发生了改变。【幻读】
-
设置
@@transaction_isolation设置为serializable;
重复第3个实验的操作,观察操作中出现的现象,即:1)在一个连接
A中,设置@@transaction_isolation设置为serializable;
2)开始事务,显示
employees表中所有员工信息,观察记录的数目;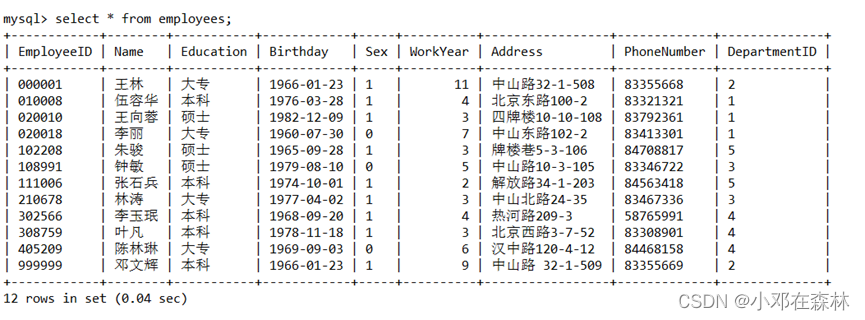
3)在另一个连接
B中,在employees表插入一条记录,并提交事务;
4)在连接
A中显示employees表的员工信息,观察记录的数目;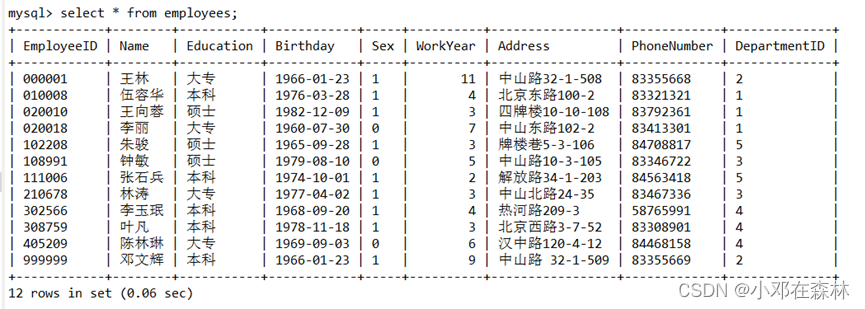
5)在连接
A中,将所有员工的workYear增加一年,观察被修改的记录的数目;
6)在连接
A中提交事务;
7)在连接
A再次显示employees表中所有员工信息,观察记录的数目;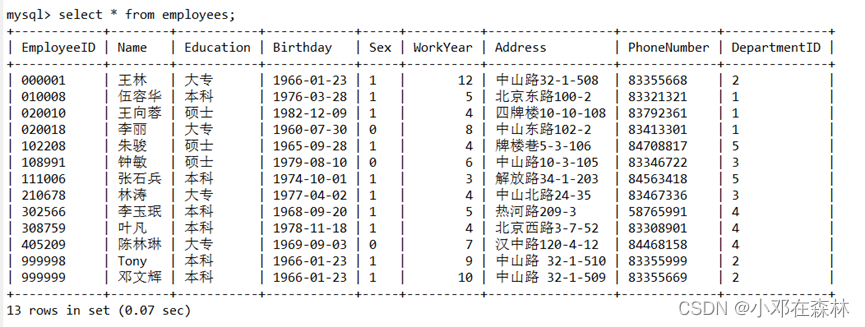
结论:对于同一个数据来说,在同一个时间段内,只能有一个会话可以访问,包括SELECT和DML,这样可以避免幻读问题。也就是说,对于同一(行)记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。【可序列化】




![[笔记] Windows内核课程:保护模式《二》段寄存器介绍](https://img-blog.csdnimg.cn/e03204ef92904648a8e871910b244787.png)