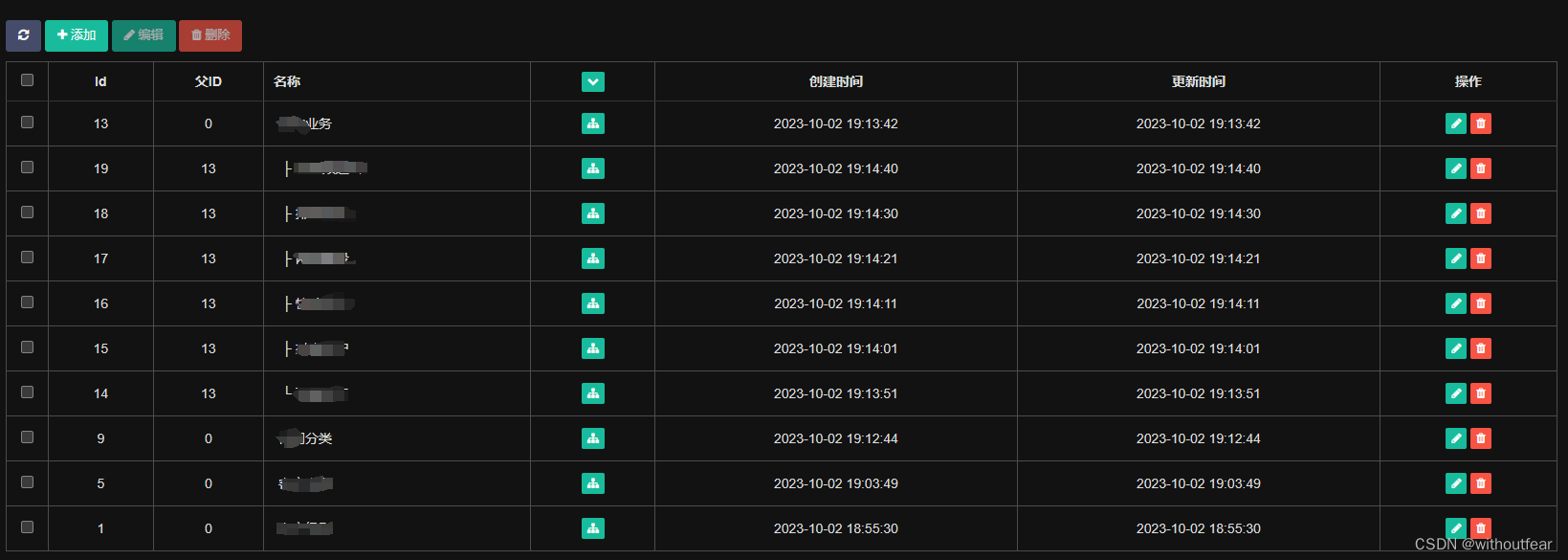
1.
两次卷积,一次池化。得到一个三维特征图,然后让三维的特征图,三个值进行相乘拉成特征向量,把得到的结果需要靠全连接层。
带参数计算才算一层
算conv的个数+FC全连接层=就得到卷积神经网络的层数
FC:全连接层
2.
3.reset网络(残差网络)
H(x)=F(x)+x
F(X)如果做的不好就不要了,令它为0;x是原本就有的映射。

残差网络可以降低错误率。
4.感受野
(1)通过堆叠多个33的卷积核来代替大尺度卷积核(减少所需参数)
比如某篇论文提到,通过堆叠两个33的卷积核替代55的卷积核,堆叠三个33的卷积核替代7*7的卷积核。
(2)感受野定义:在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层区域的大小,被称作感受野。输出feature map上的一个单元对应输入层上的区域大小。

5.

6.递归神经网络(RNN)
一般CNN适用于CV(视觉)
一般RNN适用于NLP(自然语言处理)
RNN:前一个时刻训练出的中间结果特征,也会对后一个时刻产生影响。

如果输入的是一个单词,比如x=i ,x1=am, xt=china
我们可以把单词转换成3维向量。(将单词转换成特征向量,然后根据时间顺序进行排列)
RNN的记忆能力强大,能把之前所有的结果记录下来,可能结果会产生误差。
LSTM网络:忘记一些没必要的特征。







5.将词文本转换成词向量
(1)只要有了向量就可以用不同的方法计算相似度
(2)数据的维度越高,能提供的信息也越多,从而计算结果的可靠性更值得信赖。
(3)相似的词在特征表达中比较相似。
在词向量中输入和输出分别是什么?
(1)通常是在词的层面上来构建特征,word2vec就是把词换成向量。
(2)相似的词在特征表达中比较相似,所以词的特征也是有实际意义的。
(3)构建训练数据,
CBOW:
Skipgram: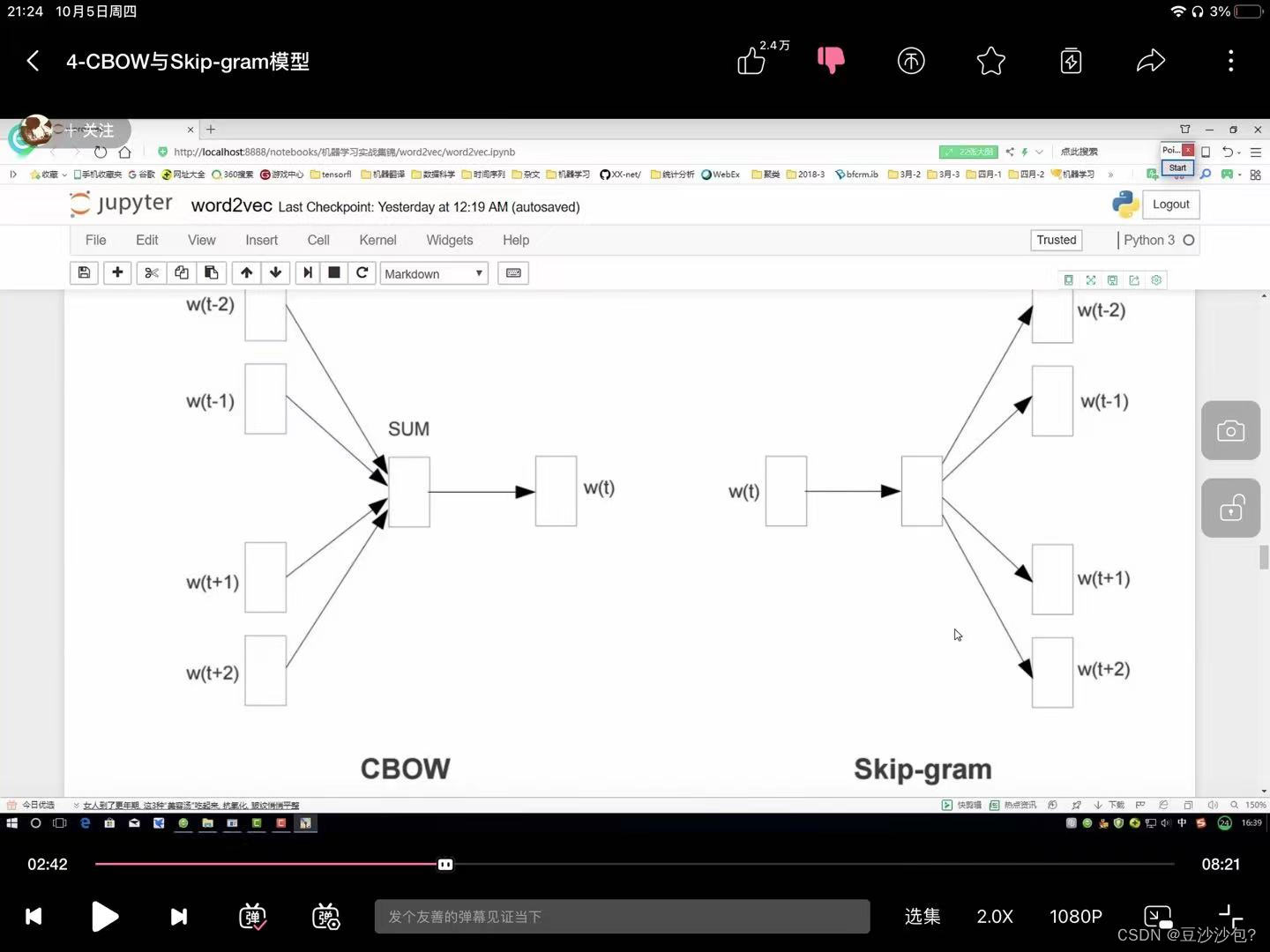
如果语料库稍微大一些,可能的结果会很多,最后一层相当于softmax,计算会耗时,
方案1:输入两个单词,看他们是不是前后对应的输入和输出,相当于二分类任务
方法2:把输入的两个单词都当成输入,看原本应该是输出的那个单词符合正确的结果的概率是多少。(2)负样本(负采样模型):加入一些没有在输出语料库的单词,构造负样本。负采样样本:一般取参数5.1)初始化词向量矩阵