1、String
1.1、介绍
String 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值,value其实不仅是字符串, 也可以是数字(整数或浮点数),value 最多可以容纳的数据长度是 512M
1.2、内部实现
String类型的底层数据结构实现是int和SDS(Simple Dynamic String,简单动态字符串)
-
SDS
- SDS不仅可以保存文本数据,还可以保存二进制数据
-
SDS获取字符串长度的时间复杂度是O(1)
- 而 SDS 结构里用 len 属性记录了字符串长度,所以复杂度为 O(1)
-
Redis的SDS API是安全的,拼接字符串不会造成缓冲区溢出
- SDS 在拼接字符串之前会检查 SDS 空间是否满足要求,如果空间不够会自动扩容,所以不会导致缓冲区溢出的问题
-
SDS数据结构

- len:记录buf数组中已使用字节的数量
- free:记录buf数组中未使用字节的数量
- buf[]: 字节数组,用于保存字符串
1.3、常用命令
1.3.1、基础操作
# 设置 key-value 类型的值
SET key value
# 根据key,获取对应的value
GET key
# 判断某个key是否存在
EXISTS key
# 返回key所存储的字符串值的长度
STRLEN key
# 删除某个key对应的值
DEL key
1.3.2、批量操作
# 批量设置key - value
MSET key1 value1 key2 value2
# 批量获取多个key对应的value
MGET key1 key2
1.3.3、计数器
字符串的内容发为整数的时候可以使用计数器操作
# 设置一个number的key,值为0(整数)
SET number 0
# 将key中存储的数字值增1
INCR number
# 将key中存储的数字值增10
INCRBY number 10
# 将key中存储的数字值减1
DECR number 1
# 将key中存储的数字值减10
DECRBY number 10
1.3.4、过期操作
默认为永不过期
# 设置key在 10秒后过期(该方法是针对已存在的key设置的过期时间)
EXPIRE key 10
# 查看key还有多久过期
TTL key
# 设置key-value,并设置key过期时间为10秒
# 方式一
SET key value EX 10
# 方式二
SETEX key 10 value
1.3.5、判断是否存在
不存在即插入
SETNX key value
1.4、应用场景
-
缓存对象
- 缓存整个对象的JSON
- SET user:1 ‘{“name”:“PP”, “age”:18}’
- 缓存整个对象的JSON
-
采用将 key 进行分离为 user:ID:属性,采用 MSET 存储,用 MGET 获取各属性值
- MSET user:1:name PP user:1:age 18 user:2:name CC user:2:age 20
-
常规计数
-
业务场景
-
访问次数
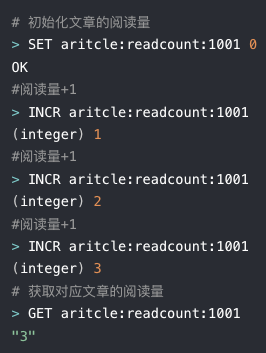
-
点赞
-
转发
-
库存数量
-
-
-
分布式锁
-
SET命令的NX参数
- 如果key不存在,显示插入成功,可以用来表示加锁成功
- 如果key存在,则会显示插入失败,可以用来表示加锁失败
-
-
对分布式锁加上过期时间,分布式锁的命令:SET lock_key unique_value NX PX 10000
- lock_key就是key键
- unique_value 是客户端生成的唯一的标识
- NX 代表只在 lock_key 不存在时,才对 lock_key 进行设置操作
- PX 10000 表示设置 lock_key 的过期时间为 10s,这是为了避免客户端发生异常而无法释放锁
-
通过lua脚本保证解锁的原子性
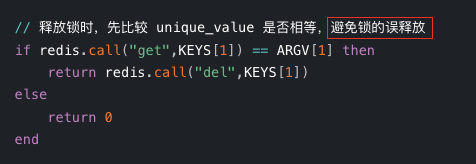
-
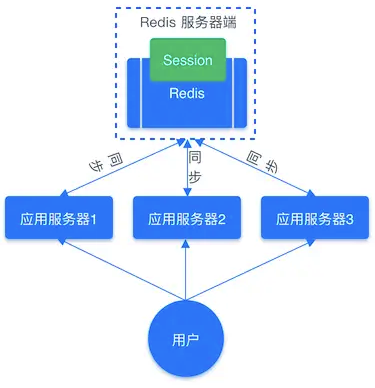
共享Session信息
-
设计
-
借助 Redis 对这些 Session 信息进行统一的存储和管理,这样无论请求发送到那台服务器,服务器都会去同一个 Redis 获取相关的 Session 信息,这样就解决了分布式系统下 Session 存储的问题
-
-
2、List
2.1、介绍
List 列表是简单的字符串列表,按照插入顺序排序,可以从头部或尾部向 List 列表添加元素。
列表的最大长度为 2^32 - 1,也即每个列表支持超过 40 亿个元素
特点:
-
高效的节点重排能力【按照插入顺序排序,头插、尾插】
-
顺序访问节点
-
通过增删节点灵活调整链表长度
2.2、内部实现
-
listNode
-
结构

-
双端链表
-
链表节点带有prev和next指针
-
获取某个节点的前置节点和后置节点复杂度都是O(1)
-

-
-
list
- 结构

-
无环链表
-
表头节点的prev指针和表尾节点的next指针都指向NULL
-
对链表的访问以NULL为终点
-
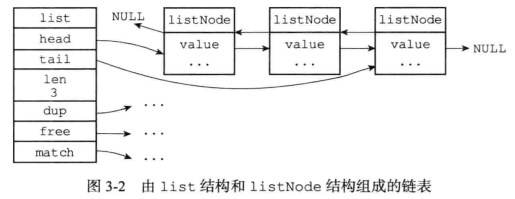
总结:
-
带表头指针和表尾指针
- 通过list结构的head指针和tail指针
-
获取链表的表头节点和表尾节点的复杂度为O(1)
-
带链表长度计数器
- list结构的len属性可以获取链表中节点数量
-
时间复杂度为O(1)
-
多态
- 链表节点使用void*指针来保存节点值
-
通过list结构的dup、free、match三个属性为节点值设置类型特定函数
-
链表可以保存各种不同类型的值
2.3、常用命令
-
LPUSH key value [ value … ]
- 将一个或多个值value插入到key列表的表头(最左边,头插)
- 最后插入的值在最前面
-
RPUSH key value [ value … ]
- 将一个或多个值value插入到key列表的表尾(最右边)
- 保证最后插入的值,在尾巴
-
LPOP
- 移除并返回key列表的头元素
-
RPOP
- 移除并返回key列表的尾元素
-
LRANGE key start stop
- 返回列表key中指定区间内的元素
-
区间以偏移量start 和 stop指定,从0开始
-
BLPOP key [ key … ] timeout
- 从key列表表头弹出一个元素,没有就阻塞timeout秒,如果timeout = 0 就一直阻塞
-
BRPOP key [ key … ] timeout
- 从key列表表尾弹出一个元素,没有就阻塞timeout秒,如果timeout = 0 就一直阻塞
RPUSH、LRANGE、LINDEX和LPOP的使用示例:
# 在向列表推入新元素之后,该命令会返回列表当前的长度
127.0.0.1:6379> RPUSH list-key item1
(integer) 1
127.0.0.1:6379> RPUSH list-key item2
(integer) 2
127.0.0.1:6379> RPUSH list-key item1
(integer) 3
# 使用0为范围的起始索引,-1为范围的结束索引,可以取出列表包含的所有元素
127.0.0.1:6379> LRANGE list-key 0 -1
1) "item1"
2) "item2"
3) "item1"
# 使用LINDEX可以从列表里面取出单个元素,被取出元素仍然在列表内
127.0.0.1:6379> LINDEX list-key 1
"item2"
# 从列表里面弹出一个元素,被弹出的元素将不再存在于列表内
127.0.0.1:6379> LPOP list-key
"item1"
127.0.0.1:6379> LRANGE list-key 0 -1
1) "item2"
2) "item1"
127.0.0.1:6379>
2.4、应用场景
-
消息队列
-
存取消息需求
-
消息保存
-
List
- LPUSH + RPOP
- RPUSH + LPOP
-
-
处理重复的消息
-
保证消息可靠性
-
-
-
生产者&消费者

- 生产者使用 LPUSH key value[value…] 将消息插入到队列的头部,如果 key 不存在则会创建一个空的队列再插入消息
- 消费者使用 RPOP key 依次读取队列的消息,先进先出
3、Hash
3.1、介绍
Hash 是一个键值对(key - value)集合,其中 value 的形式如: value=[{field1,value1},...{fieldN,valueN}]
Hash 特别适合用于存储对象
特点:
-
一个键(key)可以和一个值(value)进行关联
-
每个键,独一无二
3.2、内部实现
Redis的字典使用哈希表做为底层实现,一个哈希表里面可以有多个哈希表节点,每个哈希表节点保存了字典中的一个键值对
-
Dictht结构

- table是一个数组,数组中的每个元素都是一个指向dicyEntry结构的指针,每个dictEntry结构保存着一个键值对
- size属性记录了哈希表的大小,即table数组的大小
- used记录哈希表目前已有节点(键值对)的数量
-
DictEntry结构

- key 保存键值对中的键
- v保存键值对中的值
-
dict结构

-
dictType结构

3.3、常用命令
-
HSET key field value
- 设置key 的键值对
-
案例
- 存

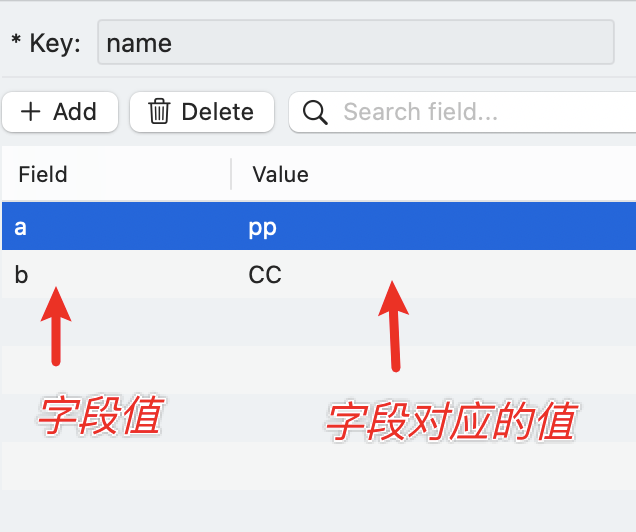
-
HGET key field
-
获取key中field的值

-
-
HMSET key field value [field value…]
- 在一个哈希表key中存储多个键值对


- 在一个哈希表key中存储多个键值对
-
HMGET key field [field …]
-
批量获取数据
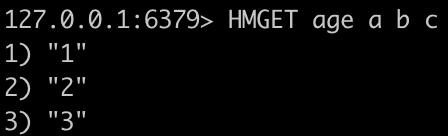
-
-
HDEL key field [field …]
- 删除哈希表key中的field键值
-
HLEN key
- 返回哈希表key中field的数量
-
HGETALL key
- 返回哈希表key中所有的键值
-
HINCRBY key field n
- 为哈希表key中field键的值加上增量n
HSET、HGET、HGETALL和HDEL的使用示例:
# 在尝试添加键值对到散列的时候,命令会返回一个值来表示给定的键是否已经存在于散列里面
# 1不存在,0存在
127.0.0.1:6379> HSET hash-key sub-key1 value1
(integer) 1
127.0.0.1:6379> HSET hash-key sub-key2 value2
(integer) 1
127.0.0.1:6379> HSET hash-key sub-key1 value1
(integer) 0
# 获取散列包含的所有键值对
127.0.0.1:6379> HGETALL hash-key
1) "sub-key1"
2) "value1"
3) "sub-key2"
4) "value2"
# 在删除键值对的时候,命令会返回一个值来表示给定的键在移除之前是否存在于散列里面
# 1存在,0不存在
127.0.0.1:6379> HDEL hash-key sub-key2
(integer) 1
127.0.0.1:6379> HDEL hash-key sub-key2
(integer) 0
# 从散列里面获取某个键的值
127.0.0.1:6379> HGET hash-key sub-key1
"value1"
127.0.0.1:6379> HGETALL hash-key
1) "sub-key1"
2) "value1"
3.4、应用场景
-
缓存对象
-
购物车
- 添加商品:HSET cart:{用户id} {商品id} 1
- 添加数量:HINCRBY cart:{用户id} {商品id} 1
- 商品总数:HLEN cart:{用户id}
- 删除商品:HDEL cart:{用户id} {商品id}
- 获取购物车所有商品:HGETALL cart:{用户id}
3.5、解决键冲突
Redis的哈希表采用链地址法(separate chaining)来解决键冲突
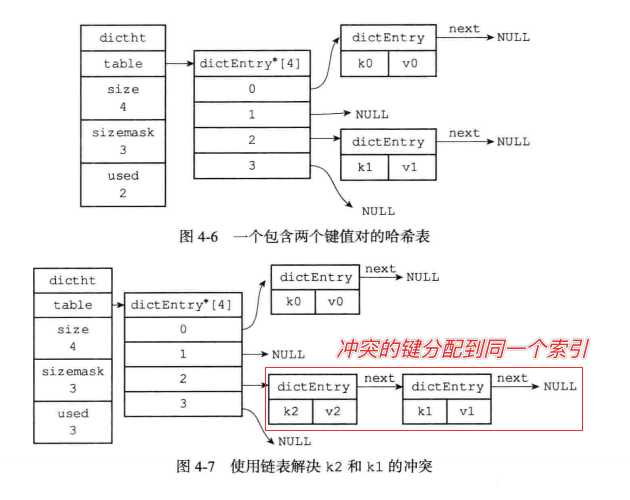
每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表连接起来,这就解决键冲突问题
4、Set
4.1、介绍
Set 类型是一个无序并唯一的键值集合,它的存储顺序不会按照插入的先后顺序进行存储。
一个集合最多可以存储 2^32-1 个元素。概念和数学中个的集合基本类似,可以交集,并集,差集等等,所以 Set 类型除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集。
特点:
-
无序,存储顺序不会按照插入的先后顺序进行存储
-
唯一,Set只能存储非重复元素
4.2、内部实现
-
哈希表+整数集合
-
intset
-
结构

-
contents
- 整数集合的每个元素都是contents数组的一个数组项(item)
- 各个项在数组中按值的大小从小到大有序地排列
- 数组中不包含任何重复项
-
length
- 记录了整数集合包含的元素数量,即contents数组的长度
-
-
4.3、常用命令
- 常用操作
# 往集合key中存入元素,元素存在则忽略,若key不存在则新建
SADD key member [member ...]
# 从集合key中删除元素
SREM key member [member ...]
# 获取集合key中所有元素
SMEMBERS key
# 获取集合key中的元素个数
SCARD key# 判断member元素是否存在于集合key中
SISMEMBER key member# 从集合key中随机选出count个元素,元素不从key中删除
SRANDMEMBER key [count]
# 从集合key中随机选出count个元素,元素从key中删除
SPOP key [count]
- 运算操作
# 交集运算
SINTER key [key ...]
# 将交集结果存入新集合destination中
SINTERSTORE destination key [key ...]# 并集运算
SUNION key [key ...]
# 将并集结果存入新集合destination中
SUNIONSTORE destination key [key ...]# 差集运算
SDIFF key [key ...]
# 将差集结果存入新集合destination中
SDIFFSTORE destination key [key ...]
SADD、SMEMBERS、SISMEMBER和SREM的使用示例:
127.0.0.1:6379> SADD set-key item
(integer) 1
127.0.0.1:6379> SADD set-key item2
(integer) 1
127.0.0.1:6379> SADD set-key item3
(integer) 1
127.0.0.1:6379> SADD set-key item
(integer) 0
127.0.0.1:6379> SMEMBERS set-key
1) "item2"
2) "item3"
3) "item"
127.0.0.1:6379> SISMEMBER set-key item4
(integer) 0
127.0.0.1:6379> SISMEMBER set-key item
(integer) 1
127.0.0.1:6379> SREM set-key item2
(integer) 1
127.0.0.1:6379> SREM set-key item2
(integer) 0
127.0.0.1:6379> SMEMBERS set-key
1) "item2"
2) "item"
4.4、应用场景
集合的主要几个特性,无序、不可重复、支持并交差等操作。
因此 Set 类型比较适合用来数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、错集和并集等,当我们存储的数据是无序并且需要去重的情况下,比较适合使用集合类型进行存储。
但是要提醒你一下,这里有一个潜在的风险。Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。
在主从集群中,为了避免主库因为 Set 做聚合计算(交集、差集、并集)时导致主库被阻塞,我们可以选择一个从库完成聚合统计,或者把数据返回给客户端,由客户端来完成聚合统计。
点赞
Set 类型可以保证一个用户只能点一个赞,这里举例子一个场景,key 是文章id,value 是用户id。
uid:1 、uid:2、uid:3 三个用户分别对 article:1 文章点赞了。
# uid:1 用户对文章 article:1 点赞
> SADD article:1 uid:1
(integer) 1
# uid:2 用户对文章 article:1 点赞
> SADD article:1 uid:2
(integer) 1
# uid:3 用户对文章 article:1 点赞
> SADD article:1 uid:3
(integer) 1
uid:1 取消了对 article:1 文章点赞。
> SREM article:1 uid:1
(integer) 1
获取 article:1 文章所有点赞用户 :
> SMEMBERS article:1
1) "uid:3"
2) "uid:2"
获取 article:1 文章的点赞用户数量:
> SCARD article:1
(integer) 2
判断用户 uid:1 是否对文章 article:1 点赞了:
> SISMEMBER article:1 uid:1
(integer) 0 # 返回0说明没点赞,返回1则说明点赞了
共同关注
Set 类型支持交集运算,所以可以用来计算共同关注的好友、公众号等。
key 可以是用户id,value 则是已关注的公众号的id。
uid:1 用户关注公众号 id 为 5、6、7、8、9,uid:2 用户关注公众号 id 为 7、8、9、10、11。
# uid:1 用户关注公众号 id 为 5、6、7、8、9
> SADD uid:1 5 6 7 8 9
(integer) 5
# uid:2 用户关注公众号 id 为 7、8、9、10、11
> SADD uid:2 7 8 9 10 11
(integer) 5
uid:1 和 uid:2 共同关注的公众号:
# 获取共同关注
> SINTER uid:1 uid:2
1) "7"
2) "8"
3) "9"
给 uid:2 推荐 uid:1 关注的公众号:
> SDIFF uid:1 uid:2
1) "5"
2) "6"
验证某个公众号是否同时被 uid:1 或 uid:2 关注:
> SISMEMBER uid:1 5
(integer) 1 # 返回0,说明关注了> SISMEMBER uid:2 5
(integer) 0 # 返回0,说明没关注
5、ZSet
5.1、介绍
Zset 类型(有序集合类型)相比于 Set 类型多了一个排序属性 score(分值),对于有序集合 ZSet 来说,每个存储元素相当于有两个值组成的,一个是有序集合的元素值,一个是排序值。
有序集合保留了集合不能有重复成员的特性(分值可以重复),但不同的是,有序集合中的元素可以排序。
5.2、内部实现
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
- 如果有序集合的元素个数小于
128个,并且每个元素的值小于64字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构; - 如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
5.3、常用命令
- 基本操作
# 往有序集合key中加入带分值元素
ZADD key score member [[score member]...]
# 往有序集合key中删除元素
ZREM key member [member...]
# 返回有序集合key中元素member的分值
ZSCORE key member
# 返回有序集合key中元素个数
ZCARD key # 为有序集合key中元素member的分值加上increment
ZINCRBY key increment member # 正序获取有序集合key从start下标到stop下标的元素
ZRANGE key start stop [WITHSCORES]
# 倒序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES]# 返回有序集合中指定分数区间内的成员,分数由低到高排序。
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]# 返回指定成员区间内的成员,按字典正序排列, 分数必须相同。
ZRANGEBYLEX key min max [LIMIT offset count]
# 返回指定成员区间内的成员,按字典倒序排列, 分数必须相同
ZREVRANGEBYLEX key max min [LIMIT offset count]
- 运算操作
# 并集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积
ZUNIONSTORE destkey numberkeys key [key...]
# 交集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积
ZINTERSTORE destkey numberkeys key [key...]
5.4、应用场景
Zset 类型(Sorted Set,有序集合) 可以根据元素的权重来排序,我们可以自己来决定每个元素的权重值。比如说,我们可以根据元素插入 Sorted Set 的时间确定权重值,先插入的元素权重小,后插入的元素权重大。
在面对需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,可以优先考虑使用 Sorted Set。
排行榜
有序集合比较典型的使用场景就是排行榜。例如学生成绩的排名榜、游戏积分排行榜、视频播放排名、电商系统中商品的销量排名等。
我们以博文点赞排名为例,PP发表了五篇博文,分别获得赞为 200、40、100、50、150。
# arcticle:1 文章获得了200个赞
> ZADD user:pp:ranking 200 arcticle:1
(integer) 1
# arcticle:2 文章获得了40个赞
> ZADD user:pp:ranking 40 arcticle:2
(integer) 1
# arcticle:3 文章获得了100个赞
> ZADD user:pp:ranking 100 arcticle:3
(integer) 1
# arcticle:4 文章获得了50个赞
> ZADD user:pp:ranking 50 arcticle:4
(integer) 1
# arcticle:5 文章获得了150个赞
> ZADD user:pp:ranking 150 arcticle:5
(integer) 1
文章 arcticle:4 新增一个赞,可以使用 ZINCRBY 命令(为有序集合key中元素member的分值加上increment):
> ZINCRBY user:pp:ranking 1 arcticle:4
"51"
查看某篇文章的赞数,可以使用 ZSCORE 命令(返回有序集合key中元素个数):
> ZSCORE user:pp:ranking arcticle:4
"50"
获取小林文章赞数最多的 3 篇文章,可以使用 ZREVRANGE 命令(倒序获取有序集合 key 从start下标到stop下标的元素):
# WITHSCORES 表示把 score 也显示出来
> ZREVRANGE user:pp:ranking 0 2 WITHSCORES
1) "arcticle:1"
2) "200"
3) "arcticle:5"
4) "150"
5) "arcticle:3"
6) "100"
获取小林 100 赞到 200 赞的文章,可以使用 ZRANGEBYSCORE 命令(返回有序集合中指定分数区间内的成员,分数由低到高排序):
> ZRANGEBYSCORE user:pp:ranking 100 200 WITHSCORES
1) "arcticle:3"
2) "100"
3) "arcticle:5"
4) "150"
5) "arcticle:1"
6) "200"
6、BitMap
6.1、介绍
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。
由于 bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。

6.2、内部实现
Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。
String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态,你可以把 Bitmap 看作是一个 bit 数组。
6.3、常用命令
bitmap 基本操作:
# 设置值,其中value只能是 0 和 1
SETBIT key offset value# 获取值
GETBIT key offset# 获取指定范围内值为 1 的个数
# start 和 end 以字节为单位
BITCOUNT key start end
bitmap 运算操作:
# BitMap间的运算
# operations 位移操作符,枚举值AND 与运算 &OR 或运算 |XOR 异或 ^NOT 取反 ~
# result 计算的结果,会存储在该key中
# key1 … keyn 参与运算的key,可以有多个,空格分割,not运算只能一个key
# 当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作 0。返回值是保存到 destkey 的字符串的长度(以字节byte为单位),和输入 key 中最长的字符串长度相等。
BITOP [operations] [result] [key1] [keyn…]# 返回指定key中第一次出现指定value(0/1)的位置
BITPOS [key] [value]
6.4、应用场景
Bitmap 类型非常适合二值状态统计的场景,这里的二值状态就是指集合元素的取值就只有 0 和 1 两种,在记录海量数据时,Bitmap 能够有效地节省内存空间。
签到统计
在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态。
签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一个月(假设是 31 天)的签到情况用 31 个 bit 位就可以,而一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。
假设我们要统计 ID 100 的用户在 2022 年 6 月份的签到情况,就可以按照下面的步骤进行操作。
第一步,执行下面的命令,记录该用户 6 月 3 号已签到。
SETBIT uid:sign:100:202206 2 1
第二步,检查该用户 6 月 3 日是否签到。
GETBIT uid:sign:100:202206 2
第三步,统计该用户在 6 月份的签到次数。
BITCOUNT uid:sign:100:202206
这样,我们就知道该用户在 6 月份的签到情况了。
如何统计这个月首次打卡时间呢?
Redis 提供了 BITPOS key bitValue [start] [end]指令,返回数据表示 Bitmap 中第一个值为 bitValue 的 offset 位置。
在默认情况下, 命令将检测整个位图, 用户可以通过可选的 start 参数和 end 参数指定要检测的范围。所以我们可以通过执行这条命令来获取 userID = 100 在 2022 年 6 月份首次打卡日期:
BITPOS uid:sign:100:202206 1
需要注意的是,因为 offset 从 0 开始的,所以我们需要将返回的 value + 1 。
判断用户登陆态
Bitmap 提供了 GETBIT、SETBIT 操作,通过一个偏移值 offset 对 bit 数组的 offset 位置的 bit 位进行读写操作,需要注意的是 offset 从 0 开始。
只需要一个 key = login_status 表示存储用户登陆状态集合数据, 将用户 ID 作为 offset,在线就设置为 1,下线设置 0。通过 GETBIT判断对应的用户是否在线。 5000 万用户只需要 6 MB 的空间。
假如我们要判断 ID = 10086 的用户的登陆情况:
第一步,执行以下指令,表示用户已登录。
SETBIT login_status 10086 1
第二步,检查该用户是否登陆,返回值 1 表示已登录。
GETBIT login_status 10086
第三步,登出,将 offset 对应的 value 设置成 0。
SETBIT login_status 10086 0
连续签到用户总数
如何统计出这连续 7 天连续打卡用户总数呢?
我们把每天的日期作为 Bitmap 的 key,userId 作为 offset,若是打卡则将 offset 位置的 bit 设置成 1。
key 对应的集合的每个 bit 位的数据则是一个用户在该日期的打卡记录。
一共有 7 个这样的 Bitmap,如果我们能对这 7 个 Bitmap 的对应的 bit 位做 『与』运算。同样的 UserID offset 都是一样的,当一个 userID 在 7 个 Bitmap 对应对应的 offset 位置的 bit = 1 就说明该用户 7 天连续打卡。
结果保存到一个新 Bitmap 中,我们再通过 BITCOUNT 统计 bit = 1 的个数便得到了连续打卡 7 天的用户总数了。
Redis 提供了 BITOP operation destkey key [key ...]这个指令用于对一个或者多个 key 的 Bitmap 进行位元操作。
operation可以是and、OR、NOT、XOR。当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作0。空的key也被看作是包含0的字符串序列。
假设要统计 3 天连续打卡的用户数,则是将三个 bitmap 进行 AND 操作,并将结果保存到 destmap 中,接着对 destmap 执行 BITCOUNT 统计,如下命令:
# 与操作
BITOP AND destmap bitmap:01 bitmap:02 bitmap:03
# 统计 bit 位 = 1 的个数
BITCOUNT destmap
即使一天产生一个亿的数据,Bitmap 占用的内存也不大,大约占 12 MB 的内存(10^8/8/1024/1024),7 天的 Bitmap 的内存开销约为 84 MB。同时我们最好给 Bitmap 设置过期时间,让 Redis 删除过期的打卡数据,节省内存
7、HyperLogLog
待补充…
7.1、介绍
7.2、内部实现
7.3、常用命令
7.4、应用场景
8、GEO
待补充…
8.1、介绍
8.2、内部实现
8.3、常用命令
8.4、应用场景
9、Stream
待补充…