import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer ( X, dropout) : assert 0 <= dropout <= 1 if dropout == 1 : return torch. zeros_like( X) if dropout == 0 : return Xmask = ( torch. rand( X. shape) > dropout) . float ( ) return mask * X / ( 1.0 - dropout)
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784 , 10 , 256 , 256
dropout1, dropout2 = 0.2 , 0.5 class Net ( nn. Module) : def __init__ ( self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training = True ) : super ( Net, self) . __init__( ) self. num_inputs = num_inputsself. training = is_trainingself. lin1 = nn. Linear( num_inputs, num_hiddens1) self. lin2 = nn. Linear( num_hiddens1, num_hiddens2) self. lin3 = nn. Linear( num_hiddens2, num_outputs) self. relu = nn. ReLU( ) def forward ( self, X) : H1 = self. relu( self. lin1( X. reshape( ( - 1 , self. num_inputs) ) ) ) if self. training == True : H1 = dropout_layer( H1, dropout1) H2 = self. relu( self. lin2( H1) ) if self. training == True : H2 = dropout_layer( H2, dropout2) out = self. lin3( H2) return outnet = Net( num_inputs, num_outputs, num_hiddens1, num_hiddens2)
num_epochs, lr, batch_size = 10 , 0.5 , 256
loss = nn. CrossEntropyLoss( reduction= 'none' )
train_iter, test_iter = d2l. load_data_fashion_mnist( batch_size)
trainer = torch. optim. SGD( net. parameters( ) , lr= lr)
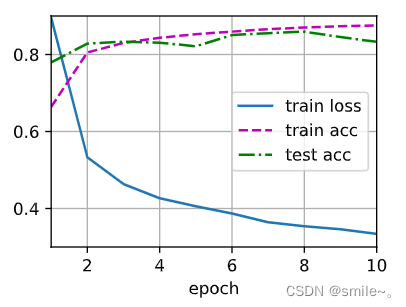
d2l. train_ch3( net, train_iter, test_iter, loss, num_epochs, trainer)
import torch
from torch import nn
from d2l import torch as d2l
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784 , 10 , 256 , 256
dropout1, dropout2 = 0.2 , 0.5
net= nn. Sequential( nn. Flatten( ) , nn. Linear( 784 , 256 ) , nn. ReLU( ) , nn. Dropout( dropout1) , nn. Linear( 256 , 256 ) , nn. ReLU( ) , nn. Dropout( dropout2) , nn. Linear( 256 , 10 ) )
def init_weights ( m) : if type ( m) == nn. Linear: nn. init. normal_( m. weight, std= 0.01 ) net. apply ( init_weights)
batch_size = 256
train_iter, test_iter = d2l. load_data_fashion_mnist( batch_size)
num_epochs, lr= 10 , 0.5
loss = nn. CrossEntropyLoss( reduction= 'none' )
trainer= torch. optim. SGD( net. parameters( ) , lr= lr)
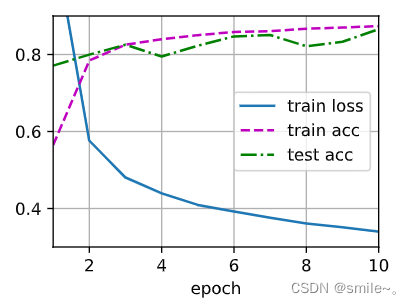
d2l. train_ch3( net, train_iter, test_iter, loss, num_epochs, trainer)



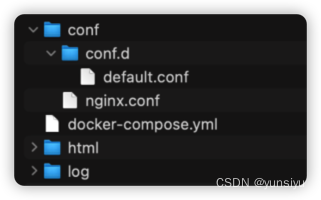
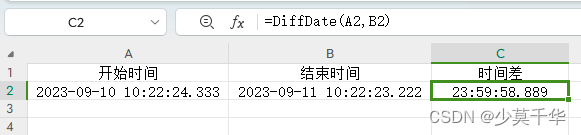
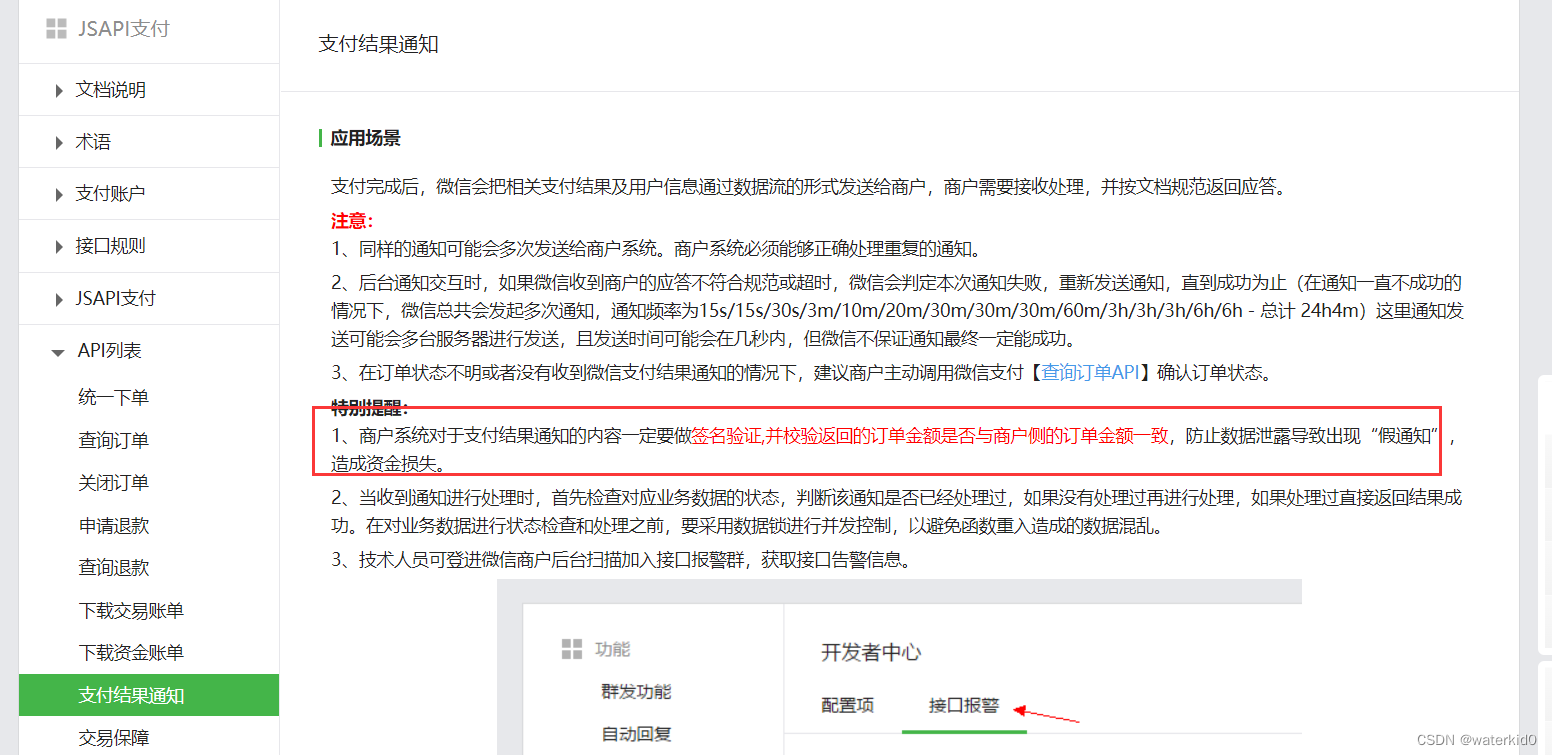
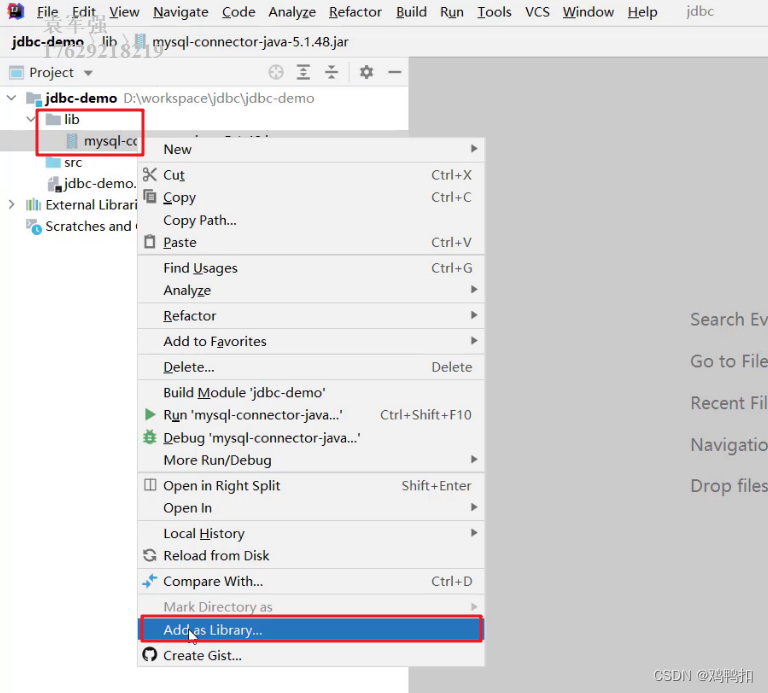


![[MongoDB]-权限验证管理](https://img-blog.csdnimg.cn/5dd44de7ddc1444ab6d05dff49863a82.png)