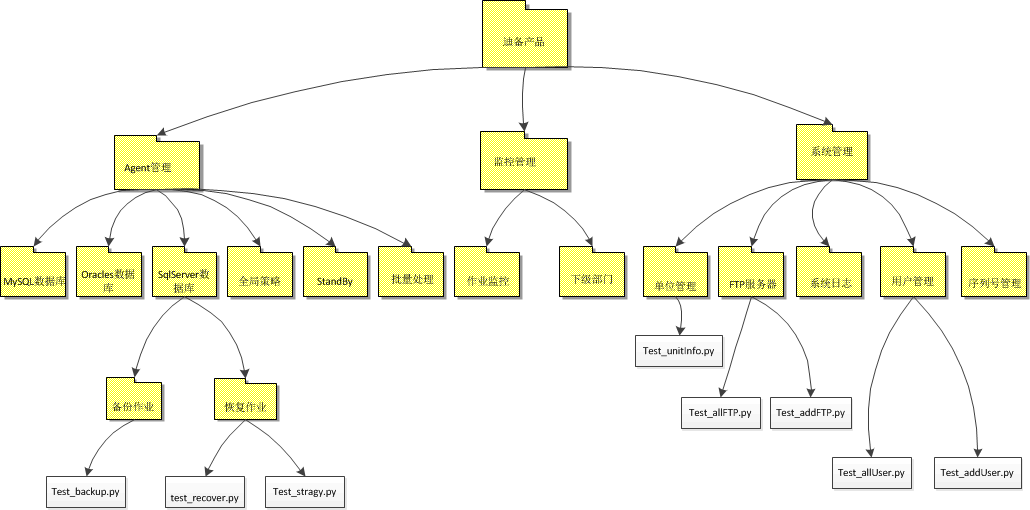
激活函数映射——引入非线性性质
h =(Σ(W * X)+b)
y=σ(h)
将h的值通过激活函数σ映射到一个特定的输出范围内的一个值,通常是[0, 1]或[-1, 1]
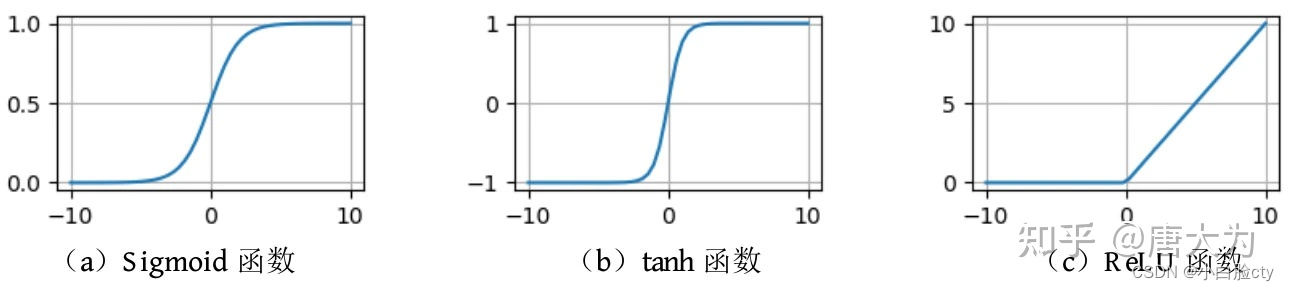
1 Sigmoid激活函数
逻辑回归LR模型的激活函数
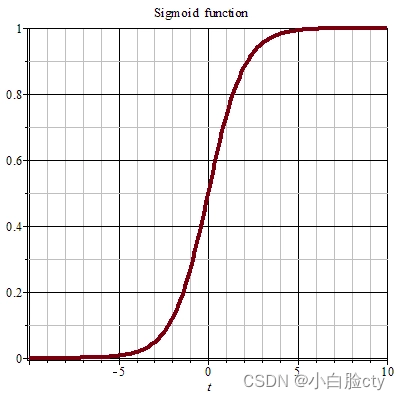
Sigmoid函数(Logistic函数)将输入值映射到0和1之间的范围,具有平滑的S形曲线。它在二元分类问题中常用,因为它可以将输出解释为概率,表示某个事件发生的概率。
在特征相差比较复杂或是相差不是特别大时效果比较好。
在深度学习中,由于sigmoid存在梯度消失现象,因此使用ReLU。
优点
平滑、易于求导。
缺点
- 计算量大:反向传播求误差梯度时,求导涉及除法
- 梯度消失:反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
- 输出恒为正:sigmoid函数的输出恒为正值,不是以零为中心的,这会导致权值更新时只能朝一个方向更新,从而影响收敛速度。
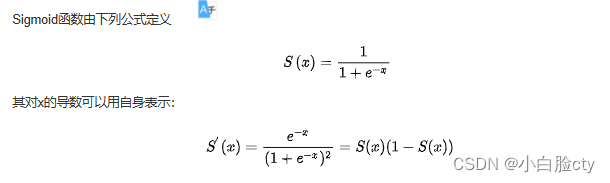
2 Tanh激活函数
tanh 激活函数是sigmoid 函数的改进版,是以零为中心的对称函数,收敛速度快,不容易出现 loss 值晃动,但是无法解决梯度消失的问题。
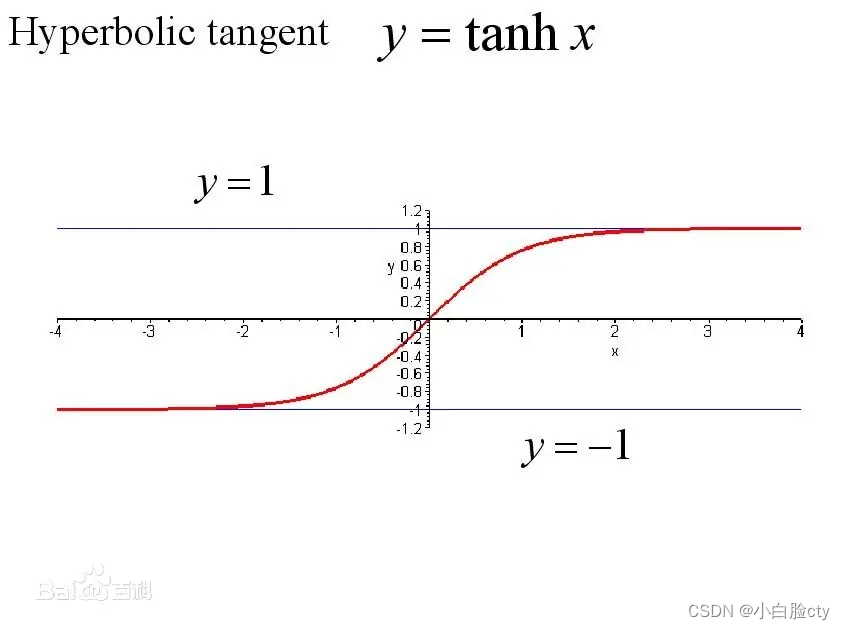
Tanh函数将输入值映射到-1和1之间的范围,也具有S形曲线。它在神经网络中广泛用于隐藏层,可以使输出具有零中心化的性质,有助于网络的训练。
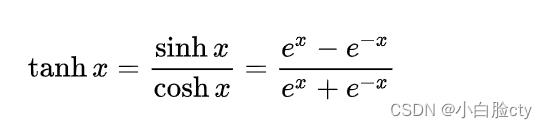
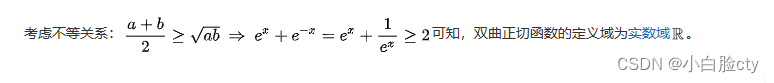
2.1 运算

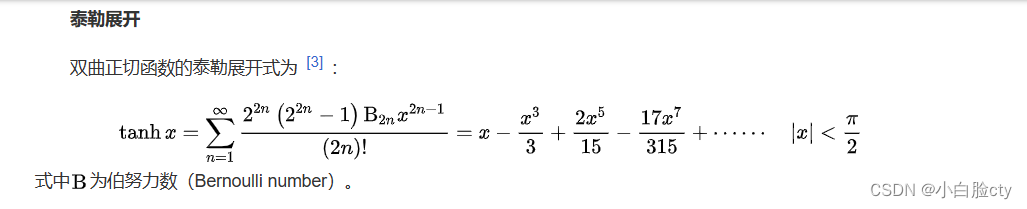


3 ReLU激活函数
ReLU(Rectified Linear Unit),又称修正线性单元。
通常指代以斜坡函数及其变种为代表的非线性函数。
将负数输入值置为零,对正数输入值保持不变。它在深度神经网络中常用,因为它具有线性部分和非线性部分,有助于解决梯度消失问题。
3.1 斜坡函数(ReLU)
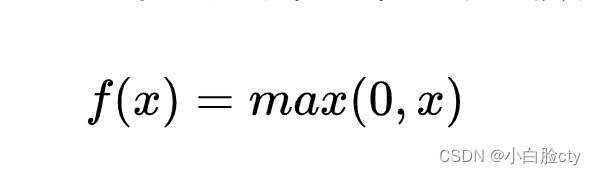
3.2 带泄露线性整流(Leaky ReLU)
在输入值为负的时候,带泄露线性整流函数(Leaky ReLU)的梯度为一个常数,而不是0。在输入值为正的时候,带泄露线性整流函数和普通斜坡函数保持一致.
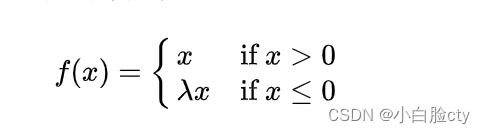
3.3 参数线性整流(Parametric ReLU)
在深度学习中,如果设定为一个可通过反向传播算法(Backpropagation)学习的变量,那么带泄露线性整流又被称为参数线性整流(Parametric ReLU)。
3.4 带泄露随机线性整流(Randomized Leaky ReLU,RReLU)
最早是在Kaggle全美数据科学大赛(NDSB)中被首先提出并使用的。相比于普通带泄露线性整流函数,带泄露随机线性整流在负输入值段的函数梯度是一个取自连续性均匀分布概率模型的随机变量
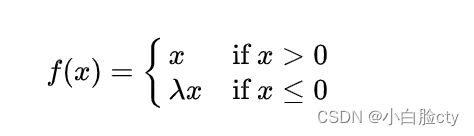
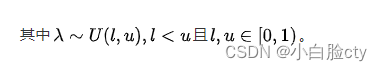
3.5 噪声线性整流(Noisy ReLU)
噪声线性整流(Noisy ReLU)是修正线性单元在考虑高斯噪声的基础上进行改进的变种激活函数。对于神经元的输入值{\displaystyle x},噪声线性整流加上了一定程度的正态分布的不确定性(使得预测值更加合理)
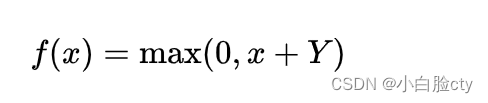
其中随机变量Y~N(0,σ(x)).
当前噪声线性整流函数在受限玻尔兹曼机(Restricted Boltzmann Machine)在计算机图形学的应用中取得了比较好的成果。
3.6 ReUL优势
- 仿生物学原理
相关大脑方面的研究表明生物神经元的信息编码通常是比较分散及稀疏的。通常情况下,大脑中在同一时间大概只有1%-4%的神经元处于活跃状态。
使用线性修正以及正则化(regularization)可以对机器神经网络中神经元的活跃度(即输出为正值)进行调试;
相比之下,逻辑函数在输入为0时达到,即已经是半饱和的稳定状态,不够符合实际生物学对模拟神经网络的期望。不过需要指出的是,一般情况下,在一个使用修正线性单元(即线性整流)的神经网络中大概有50%的神经元处于激活态。
- 更加有效率的梯度下降以及反向传播:避免了梯度爆炸和梯度消失问题。
- 简化计算过程:没有了其他复杂激活函数中诸如指数函数的影响;同时活跃度的分散性使得神经网络整体计算成本下降。

![Linux[find命令]-根据路径和条件搜索指定文件并删除](https://img-blog.csdnimg.cn/c3e9126283de4a04aabaec997a6f0349.png)