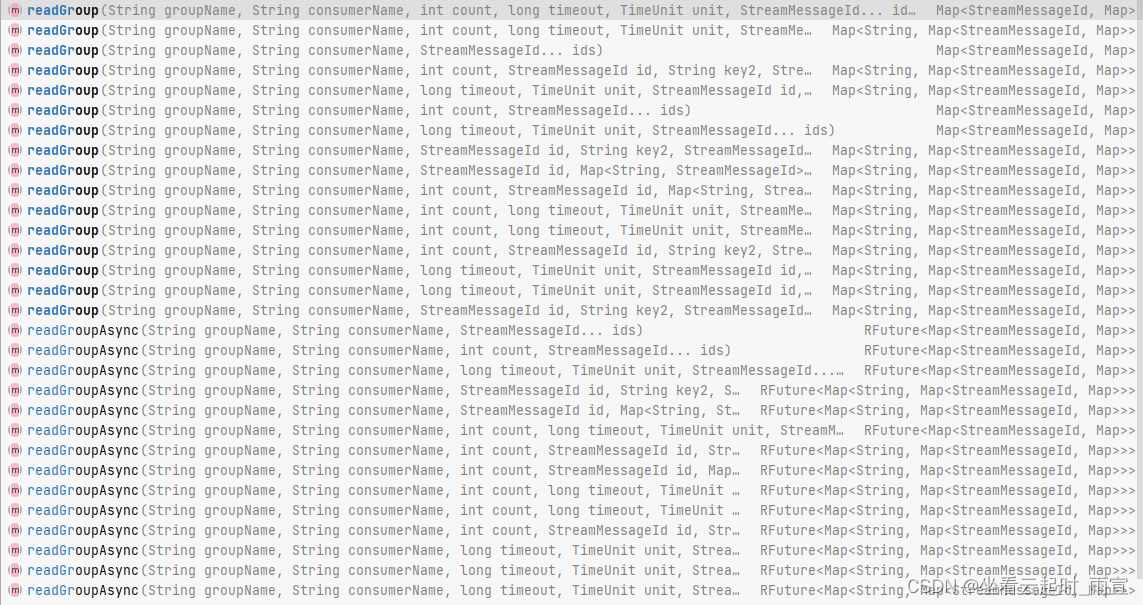
中英文场景文本图像超分辨率的基准
摘要:场景文本图像超分(STISR,Scene Text Image Super-resolution)就是将低分辨率图像恢复为具有令人愉快的视觉和可读的文本内容。现有工作都是处理笔画简单的英文字符而不是复杂的中文字符。本文中,作者提出了一个真实场景下的中英文基准数据集,命名为Real-CE,目的是为了恢复低精度的中文字符。这个基准数据集拥有1935/783的真实的高精度-低精度的文本图像对(包括3378个文本行),训练/测试可使用2X,4X缩放的方式,并有细节性的标注,包括检测框和文本记录。此外,作者还设计了边缘增强的学习方法,这种方法提供了结构性的监督和特征区域,有效的重建了中文字符的密度结构。作者在提出的数据集上评估了已有超分方法,对比了使用边缘增强的损失函数的算法效果。代码和数据链接:https://github.com/mjq11302010044/Real-CE。
1.介绍
2.相关工作
3.Real-CE基准
提出的数据集基准包括中文和英文的高清-低清图像对,评估协议有5个度量方法。
3.1 Dataset Construction(数据集构造)
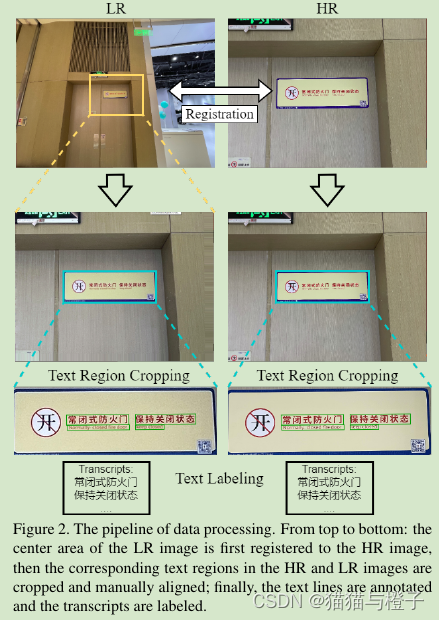
通过多个步骤重构了数据集,包括数据收集,登记( registration),文本裁剪和文本标注,如图2。
3.2 Dataset Statistics(数据集统计信息)
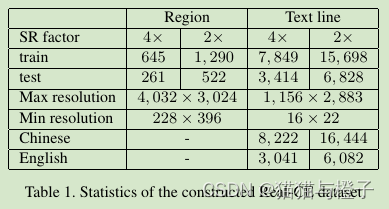
作者整理的数据包含2X和4X放缩方式进行训练和测试,数据信息统计如表1,Real-CE中包含33789个文本行对子。其中24666为中文,剩下的为英文。
3.3 Evaluation Protocol(评估协议)
在Real-CE数据集上评估STISR模型的性能,作者使用了5种度量,包括结构相似性指数测度(SSIM)【39】,峰值信噪比(PSNR),学习感知图像块相似性(LPIPS)【42】,得到的归一化编辑距离(NED)和单词准确性(ACC)。在这些度量方法中,PSNR,SSIM和LPIPS测试的误差是重建高清图像和真实结果的误差。特定的,PSNR和SSIM评估图像空间,LPIPS评估特征空间。ACC和NED使用文本识别模型来评估重建高清图像的精度。作者使用了预训练的CRNN【32,5】作为文本识别模型用于评估。ACC计算预测序列的单词级准确性。NED在预测的文本序列P和真实文本图像标签G计算方式如下:
ED(.)代表编辑距离计算,|P|和|G|分别表示预测标签和真实标签。因而,当NED值较大时,被预测的序列更加精确,更加逼近真实标签。当作者评估长文本,当我们测量长文本时,ACC指数可能不能完全反映字符级别的识别正确性,而NED可以以更细粒度的方式进行测量。
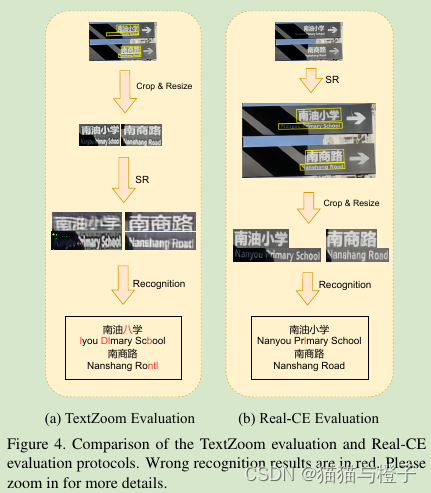
在测试过程中,训练STISR模型在原始的LR文本区域重建HR的图像。文本行在重建HR图像时会被裁剪,保持原始比例,用于ACC和NED识别评估。评估处理如图4(b)。评估TextZoom的度量协议【35】(看图4(a)),训练和评估文本行使用固定尺寸和形状,作者的协议体以避免文本信息需要进行缩放操作。如图4(a)这种操作对中文处理不是很有话,由于低重建质量和识别精度。
4. 文本边缘增强STISR
不同于英文字符,中文字符是由笔画构成(可参看【5】),有更多复杂的内部结构。因而,需要对中文文本的重建进行精细的设计。本节中,作者提出了一种边缘感知学习方法,使用边缘图作为输入,使用边缘感知作为监督。
4.1 Text Edge Map(文本边缘图)
图像中的文本信息不可避免的混合有复杂的背景信息。这就弱化了文本结构的显著性,也在某种程度上影响着文本重建处理。文本边缘信息有助于处理问题,因为它有效引导了STISR模型,更好地注意到文本结构和笔画。
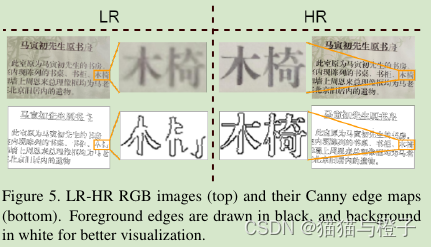
作者使用了Canny边缘检测器【3】计算文本边缘图,在训练过程中用C表示。文本边缘图区域用1表示轮廓区域,0代表背景。因而,文本边缘图包含文本结构。图5中,可以看到字符的形状和结构,在LR-HR图像对中可能不够清晰,但是使用canny 边缘图之后,文本形状和结构被增强。作者计算LR和HR图像的边缘信息。LR边缘图像CLR和LR图像在通道维度上进行concat作为网络结构的输入,如图6所示,因为这种额外的输入,STISR模型可以学到更加强壮的精炼的文本结构特征表征。
4.2 Edge-aware Loss(边缘感知损失)
作者基于计算的边缘特征图提出了边缘感知损失。首先,STISR模型输出用于重建HR文本图像,估计的HR文本边缘特征图
。被估计的文本边缘特征用于在训练阶段获得额外的监督,但是在测试阶段就不在需要。EA损失用于计算估计的文本边缘特征图和真实边缘图在像素级别和特征级别的损失。
在像素级别,我们在图像区域使用L1损失用于估计HR边缘特征图。被估计的文本边缘特征用于在训练阶段获得额外的监督,但是在测试阶段就不在需要。EA损失用于计算估计的文本边缘特征图和真实边缘图在像素级别和特征级别的损失。
在像素级别,我们在图像区域使用L1损失用于估计HR边缘特征图和真实的HR图像的边缘特征图CH之间的损失。因此,EA损失用于像素级别损失,表示如下:
此外像素级别的监督,计算特征级别的EA损失:
这里F表示预训练特征提取网络(本文中使用VGG19【34】)。和
表示估计的特征表征和真实HR的图像的特征表征。
和
分别表示估计的特征表征的文本边缘图和真实HR的文本边缘图。图像特征通过边缘特征进行element-wise操作进行加权(例如
)增强结构区域。最终,L1损失用于在固执结构和真实结构中增强特征。可以再补充文档中查看细节分析。最后,与彩色图像张的L1损失和EA损失项一起,整个损失韩式L就计算如下:
其中和
是平衡参数。
5. 实验结果
本章节,作者使用提出的基准数据集,通过对比已有的STISR算法,验证了提出的EA loss可以提升STISR算法的性能。优化器使用Adam。当在Real-CE训练集上训练,epoch总数是400.学习率设置是2X10-4.在计算EA损失L_EA.作者使用了预训练VGG19【34】预训练中的Conv5-4。公式(4)中的参数alfa和bata分别设置为1和5X10-4.当计算基于识别的度量,作者首先从全文本图像中裁剪文本行,然后缩放高清文本行用于字符识别。
5.1 Effectiveness of Real-CE Dataset(Real-CE数据集的有效性)
本章节中,作者展示了实验验证提出的Real-CE数据集超越现有真实SR数据集的优势,例如TextZoom【35】和RealSR【2】。TextZoom是用于英文超分算法的数据集,没有汉字字符。RealSR是为真实世界的自然图像超分辨率而构建。作者在三个数据集上评估了5个SOTA的SISR模型和4个SOTA的STISR模型。这5个SISR模型分别是SRRes【20】,RRDB【38】,EDSR【22】,RCAN【45】,和ELAN【44】,前四个是基于CNN的模型,最后一个是基于transformer的模型。四个STISR模型分别是TSRN【35】,TPGSR【25】,TBSRN【4】和TATT【26】,前两个是基于CNN的模型,后面2个是基于transformer的模型。
所有的STISR和SISR模型分别使用Real-CE,TextZoom和RealSR数据集合训练,测试使用Real-CE。SISR模型一般支持任意的属于尺寸,原始的测试图片作为输入,PNSR,SSIM和LPIPS度量用于原始图像尺寸上。请注意,这是我们基准测试的默认评估协议,如3.3节描述。但是,大多数STISR模型【35,25,4,26】仅仅支持固定尺寸的输入。所以,开始的时候裁剪和缩放测试图片到固定的尺寸作为网络的输入,然后将网络输出与调整大小的真实图片作比较如:PNSR,SSIM和LPIPS。
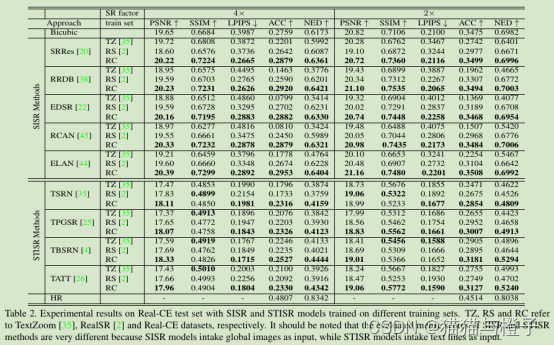
比较SISR和STISR模型的量化结果如表2。在TextZoom上训练的模型结果在基于图像度量和基于识别度量上获得了更差的结果。这是因为TextZoom训练集合中缺乏复杂的字符结构,因而训练的模型不能够处理复杂Real-CE测试集的中文字符。此外,使用TextZoom,超分辨模型只能够使用固定尺寸的数据进行训练,这就很难处理其他尺寸的字符。在RealSR【2】上训练的模型也获得了较差的结果,因为RealSR主要基于自然图像SISR。相比而言,STISR和SISR模型在Real-CE上训练获得了更好的文本恢复能力。此外,应当注意评估SISR的度量得分和STISR的度量的分方法是不一样的,SISR是将整图作为输入,而STISR是将文本行作为输入。
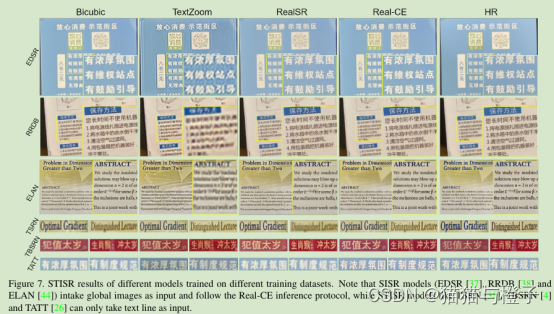
图7可视化在SISR和STISR模型在三个数据集上训练后的SR结果。为了方便,作者输入不同的图像道不同的模型中,并使用更加复杂的评估方式。模型的文本恢复结果使用TextZoom非常模糊,并包含伪影。这也是因为TextZoom缺乏复杂的中文字符结构的训练样本。此外,TextZoom仅仅支持固定尺寸的训练和训练算法结构不能够泛化到其他尺寸的测试数据集上。在RealSR上的算法模型结果伪影较少,复杂笔画才会比较模糊。对比而言,在Real-CE数据上模型训练结果拥有更加清晰的边缘,在中英文字符上拥有更多的可读性。更多的可视化结果可以查看补充性材料。在合成的LR-HR数据集和Real-CE数据集上比较STISR,请查看补充材料。
5.2 Effectiveness of the EA loss(EA loss的有效性)
作者使用不同的loss(),通过测试SISR和STISR算法模型验证了EA损失的有效性。这里作者使用了三个SISR算法模型,包括SRRes【20】,RRDB【38】和ELAN【44】,和2个STISR模型,包括TBSRN【4】和TATT【26】,在实验中,评估结果和5.1节的一样。
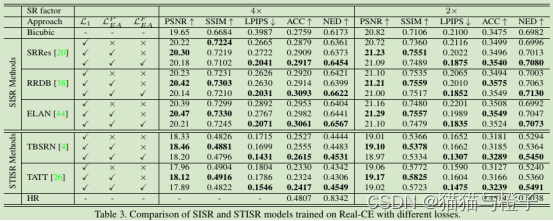
量化评估结果如表3,通过比较只使用L1损失,算法模型训练使用L1和强调了增强PSNR/SSIM得分。因为
对图像边缘进行了像素级的监督,可以从而改进像素度量。但是,感知度量(如:LPIPS)的提升和识别度量也是有限的。通过增加
损失训练,所有的模型在LPIPS和识别精度上得到了显著的提升,特别是4X结果上。这表明字符结构信息对文本易读性很重要。因为字符结构可以使用
来增强,文本识别得到有效提升。
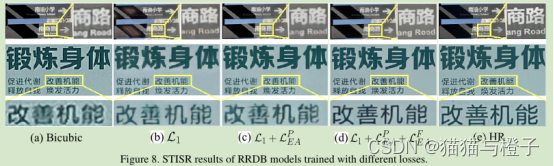
通过使用RRDB模型,作者可视化了STISR使用不同损失时的结果,如图8.首先,只使用RRDB和L1算是训练结果与双线性插值相比,展示了性能有限的提升。通过损失训练,重建后的文本图像具有更清晰的字符边缘,得到了很大的增强。如图8(c)。通过进一步整合
损失,有效提升了边缘清晰度和局部的对比对,有效的提升了中文文本内容的可视化,如图8(d)。此外,更多的结果可以查看补充性文档。
5.3 Failure Cases(失败的例子)

作者提出的方法在某些情况下会失败:当字符图像非常模糊和字符结构很复杂,如图9所示。尽管输出边缘清晰,但是有些笔画却错了。这是因为细笔画在低精度的图像中非常模糊。这种情形下,可以合并语义信息以提供帮助文本修复,这将是我们未来的工作。
6.结论
本文中,作者创立了中英文基准数据集,命名为Real-CE,可用于图像超分辨率(STISR)模型的训练。包括了1935张训练样本和783张测试样本。文本区域中包括33789行文本行,里面有24666行是复杂结构的中文文本。作者进一步提出了边缘增强(EA, edge-aware)学习方法用于重建中文文本,该方法用于计算文本边缘图,部署EA损失引导STISR模型学习星恋。实验结果正面使用Real-CE数据集训练可以使文字变得更加清晰,更加可读。EA学习策略可以有效的有效的提升图像质量。Real-CE数据集为研究者提供了一个基准,可供研究者研究中文文本图像的恢复方法。