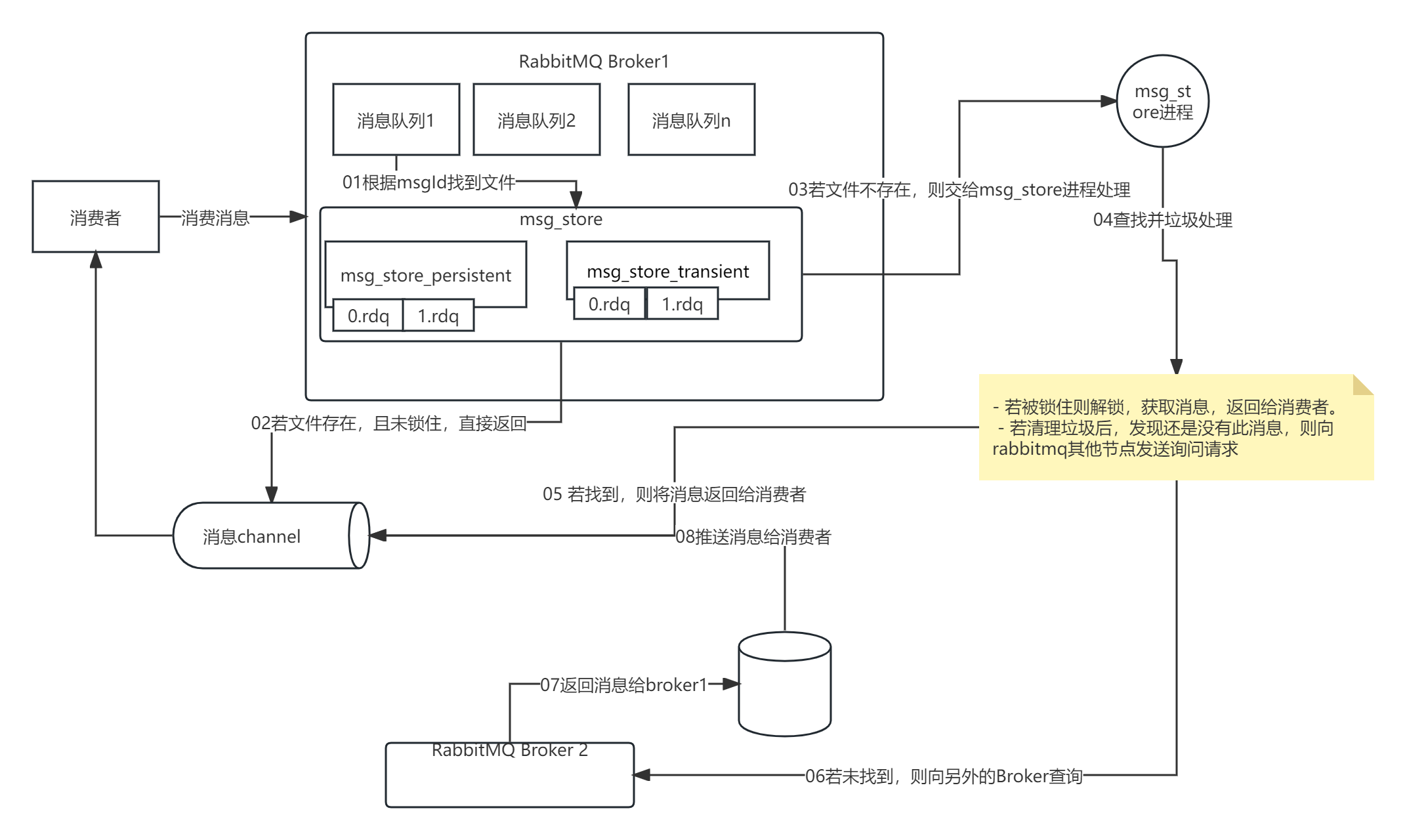
🔔目的
提升后端API性能的主要目的是为了提高系统整体的响应速度、并发能力以及可用性。主要原因包括:
-
提高用户体验
后端API性能好可以减少响应延迟,给用户流畅的体验。
-
提高系统吞吐量
优化API性能可以提高系统的整体吞吐量,处理更多用户请求。
-
节省服务器资源成本
优化API提高资源利用率,减少对计算、内存、网络等资源的占用。
-
提高系统稳定性
良好的API性能可以防止请求积压造成的链路阻塞,减少超时、服务降级等问题。
-
促进业务发展
性能良好的API可以支撑更复杂的业务场景,为产品迭代和业务增长提供保障。
-
提升运维效率
代码和架构优化可以降低重复工作量,减少故障排查时间。
-
增强系统容错能力
优化后可以应对更大的流量冲击和失效情形。
🔔优化概述
-
代码优化
通过算法优化、减少IO等方式优化程序,使其高效运行。
-
缓存使用
通过Redis、Memcache等缓存数据库缓存常用数据,减少数据库查询。
-
CDN加速
使用CDN缓存静态资源,减少服务器压力。
-
异步处理
通过消息队列、事件驱动等方式实现异步处理,提高并发能力。
-
服务拆分
将服务拆分为小的单元服务,采用微服务架构。
-
流量控制
通过限流、降级等方式控制流量并保护服务稳定运行。
-
数据库优化
优化数据库模式,使用索引、读写分离等技术提升数据库效率。
-
并发优化
通过线程池、非阻塞IO等方式提升系统并发性能。
-
服务器扩容
垂直扩容服务器或利用云服务横向扩容,增强处理能力。
🔔具体实践
-
线程池化
池化技术(Pooling)的关键思想就是重用,其目的是为了避免每次需要资源时都要重复创建和销毁,从而提高性能和资源利用率。
以数据库连接池为例,不使用连接池的时候,每次操作数据库都需要:- 创建数据库连接
- 执行sql语句
- 关闭数据库连接
这样重复创建和关闭连接会非常耗费资源。
而引入连接池后,可以提前创建好一定数量的连接,放入连接池待用。需要时直接从池中取出已有连接使用,操作完毕再放回池中,而不需要重复创建连接。
同样,线程池也是提前创建线程,组成线程池待用,需要时直接派一个空闲线程执行任务,从而避免了频繁创建和销毁线程的资源消耗。
池化技术重在提高资源的重复利用率。目的是为了提高性能,减少不必要的性能开销。现在几乎所有的连接资源都会使用池化技术进行管理。 -
批量入库
对于需要批量插入或者更新到数据库的操作,可以先批量处理逻辑完之后再统一一次性插入数据库,这样做的优势在于
-
减少网络交互,提高写入效率。
向数据库批量插入可以减少客户端与数据库之间的网络往返。
-
可以对数据进行预处理。
可以在入库前对数据进行过滤、转换等优化。
-
减少索引更新开销。
可以关闭索引,批量插入后再重建索引,从而减少索引更新带来的开销。
-
可以执行更复杂的SQL逻辑。
批处理可以构建更复杂的SQL逻辑完成数据导入。
-
提高数据库并发能力。
批量写入可以聚合成少量大事务,可以减少数据库并发Transaction的数量。
-
-
异步执行
在设计接口时,对于一些非核心业务逻辑,如果这部分逻辑执行时间长且不影响主业务流程,我们可以考虑“异步”执行这些逻辑。
具体来说,可以通过以下技术方案实现:-
使用消息队列,让主业务逻辑快速返回,将非核心逻辑作为消息放入队列异步执行。
-
设计异步线程或定时任务,在主线程返回后,异步线程负责后台执行非核心逻辑。
-
利用事件编程模型,主业务逻辑触发事件,事件监听者异步响应事件执行非核心逻辑。
-
非核心逻辑作为微服务单独部署,主业务快速调用微服务,微服务后台异步执行逻辑。
-
使用reactor模式,主线程接收请求触发非核心逻辑,再通过多线程异步执行非核心处理。
常见的异步有:
- 多线程 - 在新线程中执行异步任务,主线程不等待异步线程结束即返回。
- 事件/回调 - 主线程注册回调,异步任务完成后由系统调用回调函数,通知主线程。
- Future/Promise - 主线程返回一个future对象,异步线程设置future的结果,主线程可以获取future的结果。
- Reactor模式 - 基于事件循环的模型,主线程接收请求,dispatch事件给异步线程池处理。
-消息队列 - 主线程产生消息,通过消息队列进行异步处理。如 RabbitMQ, Kafka。 - Observable - 主线程注册Observer,由Observable异步调用Observer的回调方法。如 RxJava。
- Async/Await - 使用async标记的函数自动异步执行,await可以等待异步函数结果。
- 协程 - 可以手动控制协程的切换,实现异步处理。如Goroutine。
-
-
使用缓存
恰当地使用缓存,可以大大的提升接口的性能。
使用缓存的主要好处有:
-
减少数据库查询,降低后端负载
缓存可以存储热点数据,减少对数据库的查询,降低后端存储系统的压力。 -
加速读取速度
从缓存读取数据比数据库查询要快得多,可以显著提高访问速度。 -
改善用户体验
加速系统响应,用户会感受到更流畅的用户体验。 -
提高系统扩展能力
缓存层可以作为数据库前的缓冲层,让系统支持更高的负载。 -
降低基础设施成本
减少存储系统扩容提升需求,降低整体IT成本。 -
保护核心数据系统
缓存可充当外部系统与核心存储之间的屏障。 -
帮助实现高可用性
缓存可作为备份数据源,在主数据源不可用时提供冗余数据访问。
常见的缓存有:
-
Redis - 基于内存的键值缓存,支持多种数据结构,性能极高。
-
Memcached - 简单的内存键值缓存,没有Redis丰富的数据结构。
-
-
慢查询优化
可以从以下几点优化:
- 数据库结构优化
- 合理设计表结构,避免冗余数据。
- 对于高并发修改的字段,拆分到单独表中。
- 对访问频繁的列建立索引。
- SQL语句优化
- 尽量避免全表扫描,先通过索引字段过滤数据。
- 避免在索引列上做函数转换。
- 对多个表Join时,保证Join条件列有索引。
- 合理利用慢查询日志分析和调优查询。
- 数据库参数优化
- 调整max_connections、table_open_cache等系统变量。
- 调整innodb_buffer_pool_size、innodb_log_file_size等InnoDB存储引擎参数。
- 架构优化
- 对热点数据进行缓存。
- 对可读数据库使用主从复制分离读写。
- 拆分数据库,分散压力。
- 使用索引代替Join查询。
- 程序优化
- 避免N+1问题,使用Join提前预加载关联数据。
- 避免频繁小请求数据库,可以批处理或异步处理。
- 数据库结构优化
-
锁粒度避免过粗
在设计并发程序时,使用锁(mutex)来保护共享资源,但锁的范围不能设计得过于宽泛,这称为锁的粒度问题。
过粗的锁粒度意味着锁的范围过于宽泛,例如对整个应用只有一把大锁。这会带来以下问题:-
锁争用过于频繁,并发程度低
-
可能会发生死锁
-
锁的获取和释放频繁上下文切换,性能消耗严重
因此需要注意锁粒度的选择:
-
只在访问共享资源时加锁,不要锁住无关代码
-
可以将一个大锁拆分为多个细粒度的锁
-
根据代码逻辑设计锁的范围,避免锁过多或过少
-
不同的线程访问不同资源应该用不同的锁
示例
private void A(){ }//共享方法 private void B(){ }private int C(){synchronized(this){A();B();} }修改为
private void A(){ }//共享方法 private void B(){ }private int C(){A();synchronized(this){B();} } -
-
串行改并行
在设计程序时,原本采用了串行逻辑,即一个任务完成后再执行下一个任务。这种模型导致任务只能顺序执行,整体吞吐量受到限制。
为提高吞吐量,可以考虑将程序逻辑改为并行执行。具体做法是:- 把任务进行拆分,同一类任务使用多个实例并行地执行。
- 对于需要顺序的任务,可以使用消息队列将任务异步化,提高并行程度。
- 对串行的业务流程进行重构,看哪些环节可以通过多线程、异步来并行执行。
- 对串行访问的共享资源,使用锁或CAS算法来控制并发访问。
- 使用线程池、actor模型等并发框架,提高程序对多核CPU的利用率。
通过程序逻辑从串行改为并行,可以显著提升系统整体的吞吐量和处理能力。需要注意资源竞争和死锁等并发问题。适当保留关键串行流程来实现正确性。
比如 串行
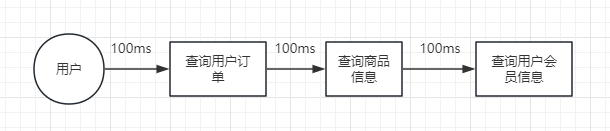
改成
并行
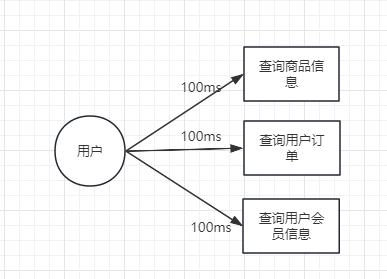
🔔写在最后
如果大家对相关文章感兴趣,可以关注公众号"架构殿堂",会持续更新AIGC,java基础面试题, netty, spring boot, spring cloud等系列文章,一系列干货随时送达!