NumPy是用于数值计算的强大工具,提供了许多数组运算和数学函数,允许你执行各种操作,包括基本运算、统计计算、线性代数、元素级操作等
1.基本运算
1.1 四则运算
NumPy数组支持基本的四则运算(加法、减法、乘法和除法),它们是元素级别的运算,也称为逐元素运算;
-
numpy.add(): 加法运算,或使用:+; -
numpy.subtract(): 减法运算,或使用:-; -
numpy.multiply(): 乘法运算,或使用:*; -
numpy.divide(): 除法运算,或使用:/;
import numpy as np
if __name__ == '__main__':
arr1 = np.array([1, 2, 3, 4])
arr2 = np.array([10, 20, 30, 40])
# 加法运算
print("加法运算(add):", np.add(arr1, arr2))
print("加法运算(+):", arr1 + arr2)
# 减法运算
print("减法运算(subtract):", np.subtract(arr1, arr2))
print("减法运算(-):", arr1 - arr2)
# 乘法运算
print("乘法运算(multiply):", np.multiply(arr1, arr2))
print("乘法运算(*):", arr1 * arr2)
# 除法运算
print("除法运算(divide):", np.divide(arr1, arr2))
print("除法运算(/):", arr1 / arr2)
"""
加法运算(add): [11 22 33 44]
加法运算(+): [11 22 33 44]
减法运算(subtract): [ -9 -18 -27 -36]
减法运算(-): [ -9 -18 -27 -36]
乘法运算(multiply): [ 10 40 90 160]
乘法运算(*): [ 10 40 90 160]
除法运算(divide): [0.1 0.1 0.1 0.1]
除法运算(/): [0.1 0.1 0.1 0.1]
"""
1.2 平方根
公式说明: 平方根,又叫二次方根,表示为: ; 如 ,那么 4的平方根就是2,表示为:
import numpy as np
if __name__ == '__main__':
arr = np.array([1, 4, 9, 16])
print("一维数组平方根运算:", np.sqrt(arr))
two_arr = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8]
])
print("二维数组平方根运算:\n", np.sqrt(two_arr))
"""
一维数组平方根运算: [1. 2. 3. 4.]
二维数组平方根运算:
[[1. 1.41421356 1.73205081 2. ]
[2.23606798 2.44948974 2.64575131 2.82842712]]
"""
1.3 幂运算
公式说明: 用于表示一个数(底数)被另一个数(指数)多次相乘的结果,它通常以符号 表示,其中
a是底数,b是指数;如: 表示2的立方,计算结果为:2 * 2 * 2 = 8
import numpy as np
if __name__ == '__main__':
arr = np.array([1, 2, 3, 4])
print("一维数组幂运算:\n", np.power(arr, 2))
two_arr = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8]
])
print("二维数组幂运算:\n", np.power(two_arr, 2))
"""
一维数组幂运算:
[ 1 4 9 16]
二维数组幂运算:
[[ 1 4 9 16]
[25 36 49 64]]
"""
2.统计运算
2.1 求和
np.sum(): 用于计算数组元素总和的函数。它可以接受多个参数,但最常用的是对单个数组进行求和。
import numpy as np
if __name__ == '__main__':
# 一维数求和运算
arr = np.array([1, 2, 3, 4])
print("一维数组求和运算:", np.sum(arr))
# 二维数组求和运算
two_arr = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8]
])
print("二维数组求和运算:", np.sum(two_arr))
# 三维数组求和运算
three_arr = np.arange(6).reshape((1, 3, 2))
print("三维数组:\n", three_arr)
print("三维数组求和运算:", np.sum(three_arr))
"""
一维数组求和运算: 10
二维数组求和运算: 36
三维数组:
[[[0 1]
[2 3]
[4 5]]]
三维数组求和运算: 15
"""
2.2 平均值
np.mean(): 用于计算数组元素平均值的函数。它可以接受多个参数,但最常用的是对单个数组进行平均值计算。
mean(a, axis=None, dtype=None, out=None, keepdims=np._NoValue, *,where=np._NoValue)
a. 参数说明:
-
axis:可以指定在哪个轴上进行平均值计算。默认情况下,它会对整个数组进行计算,返回一个标量值。 -
dtype:可以指定结果的数据类型。默认情况下,结果的数据类型与输入数组的数据类型相同。 -
keepdims:默认情况下,返回一个降维后的数组(标量),但如果设置keepdims=True,则结果将保持与输入数组相同的维度 -
where:它接受一个布尔数组或条件表达式,当参数不为空时,将只计算满足条件的元素的平均值,而忽略不满足条件的元素。
b.代码示例:
import numpy as np
if __name__ == '__main__':
# 一维数组
one_arr = np.array([10, 20, 30, 40])
# 二维数组
two_arr = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8]
])
print("---------------- 不指定参数时 ----------------")
print("一维数组,求平均值:", np.mean(one_arr))
print("二维数组,求平均值:", np.mean(two_arr))
print("---------------- 使用axis参数 ----------------")
print("二维数组,对列求平均值:", np.mean(two_arr, axis=0))
print("二维数组,对行求平均值:", np.mean(two_arr, axis=1))
print("---------------- 使用dtype参数 ----------------")
mean_dtype = np.mean(two_arr, dtype=np.float32)
mean_no_dtype = np.mean(two_arr)
print("二维数组,求平均值:{},类型:{} 不指定dtype时类型:{}".format(mean_dtype, type(mean_dtype), type(mean_no_dtype)))
print("---------------- 使用keepdims ----------------")
print("二维数组,求平均值;指定:keepdims:", np.mean(two_arr, keepdims=True))
print("---------------- 使用where ----------------")
print("一维数组,求平均值;指定:where > 20:", np.mean(one_arr, where=one_arr > 20))
print("二维数组,求平均值;指定:where > 6:", np.mean(two_arr, where=two_arr > 6))
"""
---------------- 不指定参数时 ----------------
一维数组,求平均值: 25.0
二维数组,求平均值: 4.5
---------------- 使用axis参数 ----------------
二维数组,对列求平均值: [3. 4. 5. 6.]
二维数组,对行求平均值: [2.5 6.5]
---------------- 使用dtype参数 ----------------
二维数组,求平均值:4.5,类型:<class 'numpy.float32'> 不指定dtype时类型:<class 'numpy.float64'>
---------------- 使用keepdims ----------------
二维数组,求平均值;指定:keepdims: [[4.5]]
---------------- 使用where ----------------
一维数组,求平均值;指定:where > 20: 35.0
二维数组,求平均值;指定:where > 6: 7.5
"""
2.3 中位数
np.median() 是用于计算数组的中位数的函数。
numpy.median(a, axis=None, out=None, overwrite_input=False, keepdims=False)
a.参数说明:
-
axis:指定计算中位数时要沿着哪个轴操作。默认值为None,表示在整个数组上计算中位数。 -
out:可选参数,用于指定存储结果的输出数组。如果未提供,则创建一个新的数组来存储结果。 -
overwrite_input:可选参数,如果设置为True,则允许直接修改输入数组以节省内存。默认值为False。 -
keepdims:可选参数,如果设置为True,则结果将保持与输入数组相同的维度。默认值为False。
b. 代码示例:
import numpy as np
if __name__ == '__main__':
# 一维数组
one_arr = np.array([10, 20, 30, 40])
print("一维数组中位数:", np.median(one_arr))
# 二维数组
two_arr = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8]
])
print("二维数组中位数:", np.median(two_arr))
print("二维数组,沿行计算中位数:", np.median(two_arr, axis=1))
print("二维数组,沿列计算中位数:", np.median(two_arr, axis=0))
"""
一维数组中位数: 25.0
二维数组中位数: 4.5
二维数组,沿行计算中位数: [2.5 6.5]
二维数组,沿列计算中位数: [3. 4. 5. 6.]
"""
2.4 方差
方差是统计学中用来衡量一组数据的离散程度或分散程度的一种度量。它表示数据集中各个数据点与数据集均值之间的差异程度。方差越大,数据点相对于均值的分散程度就越高,方差越小,数据点相对于均值的分散程度就越低。

a. 计算方差示例:

在NumPy中使用函数np.var() 用于计算数组的方差。它的语法如下:
numpy.var(a, axis=None, dtype=None, out=None, ddof=0, keepdims=False)
b. 参数说明:
-
axis:指定计算方差时要沿着哪个轴操作。默认值为None,表示在整个数组上计算方差。 -
dtype:可选参数,用于指定结果的数据类型。默认值为None,表示结果的数据类型由输入数组决定。 -
out:可选参数,用于指定存储结果的输出数组。如果未提供,则创建一个新的数组来存储结果。 -
ddof:可选参数,表示自由度的调整量。默认值为0,表示标准的样本方差计算。通常在样本较小的情况下,将ddof设置为1以进行无偏估计。 -
keepdims:可选参数,如果设置为True,则结果将保持与输入数组相同的维度。默认值为False。
c.代码示例:
import numpy as np
if __name__ == '__main__':
# 一维数组
one_arr = np.array([5, 8, 12, 15, 20])
print("一维数组方差:", np.var(one_arr))
# 二维数组
two_arr = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8]
])
print("二维数组方差:", np.var(two_arr))
print("二维数组,沿行计算方差:", np.var(two_arr, axis=1))
print("二维数组,沿列计算方差:", np.var(two_arr, axis=0))
print("-------------------------- 指定:ddof ------------------------------")
print("二维数组方差:", np.var(two_arr))
print("二维数组,沿行计算方差:", np.var(two_arr, axis=1, ddof=1))
print("二维数组,沿列计算方差:", np.var(two_arr, axis=0, ddof=1))
"""
一维数组方差: 27.6
二维数组方差: 5.25
二维数组,沿行计算方差: [1.25 1.25]
二维数组,沿列计算方差: [4. 4. 4. 4.]
-------------------------- 指定:ddof ------------------------------
二维数组方差: 5.25
二维数组,沿行计算方差: [1.66666667 1.66666667]
二维数组,沿列计算方差: [8. 8. 8. 8.]
"""
2.5 标准差
标准差是一种用于度量数据集的离散程度或分散程度的统计指标,它是方差的平方根。标准差用于衡量数据点相对于数据集的均值的平均偏离程度,它提供了一种对数据集中数据分布的散布情况的直观认识。 标准差公式:
在NumPy中使用函数np.var() 用于计算数组的标准差,下面是代码示例:
import numpy as np
if __name__ == '__main__':
# 一维数组
one_arr = np.array([5, 8, 12, 15, 20])
print("一维数组标准差:", np.std(one_arr))
# 二维数组
two_arr = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8]
])
print("二维数组标准差:", np.std(two_arr))
print("二维数组,沿行计算标准差:", np.std(two_arr, axis=1))
print("二维数组,沿列计算标准差:", np.std(two_arr, axis=0))
"""
一维数组标准差: 5.253570214625479
二维数组标准差: 2.29128784747792
二维数组,沿行计算标准差: [1.11803399 1.11803399]
二维数组,沿列计算标准差: [2. 2. 2. 2.]
"""
2.6 最值
在numpy中,使用np.max()获取数组中最大值,使用np.min()获取数组中最小值;
import numpy as np
if __name__ == '__main__':
# 一维数组
one_arr = np.array([5, 8, 12, 15, 20])
print("一维数组最大值:", np.max(one_arr))
print("一维数组最小值:", np.min(one_arr))
# 二维数组
two_arr = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8]
])
print("二维数组最大值:", np.max(two_arr))
print("二维数组最小值:", np.min(two_arr))
print("------------------- 沿轴计算最值----------------------------")
print("二维数组,沿行计算最大值:", np.max(two_arr, axis=1))
print("二维数组,沿列计算最大值:", np.max(two_arr, axis=0))
"""
一维数组最大值: 20
一维数组最小值: 5
二维数组最大值: 8
二维数组最小值: 1
------------------- 沿轴计算最值----------------------------
二维数组,沿行计算最大值: [4 8]
二维数组,沿列计算最大值: [5 6 7 8]
"""
3. 广播运算
3.1 介绍
NumPy中的广播(Broadcasting)是一种强大的特性,它允许在不同形状的数组之间执行元素级操作,而无需显式地将数组形状调整为相同的形状。这使得NumPy能够高效地执行各种元素级运算,而不需要额外的内存消耗。
具体广播的规则如下:
-
规则1:如果两个数组的维度不同,将形状较小的数组的维度用1填充,直到两个数组的维度一致。 -
规则2:如果两个数组在某个维度上相同或其中一个维度大小为 1,那么可以进行广播。 -
规则3:如果两个数组在某个维度上的大小既不相同也不为1,则广播会失败,导致 ValueError
3.2 规则1-示例说明
规则1:如果两个数组的维度不同,将形状较小的数组的维度用1填充,直到两个数组的维度一致。
import numpy as np
if __name__ == '__main__':
arr1 = np.array([1, 2, 3]) # 形状:(3,)
print("数组1:", arr1)
arr2 = np.array([[10], [20]]) # 形状:(2, 1)
print("数组2:\n", arr2)
result = arr1 + arr2
print("广播规则1结果: \n", result)
"""
数组1: [1 2 3]
数组2:
[[10]
[20]]
广播规则1结果:
[[11 12 13]
[21 22 23]]
"""
说明: arr1 的形状是 (3,),arr2 的形状是 (2, 1),根据规则1,将 arr1 的形状用1填充,变为 (1, 3),然后两个数组的维度一致,可以进行广播。
3.3 规则2-示例说明
规则2:如果两个数组在某个维度上相同或其中一个维度大小为 1,那么可以进行广播。
import numpy as np
if __name__ == '__main__':
arr1 = np.array([[1, 2, 3], [4, 5, 6]]) # 形状:(2, 3)
print("arr1:\n", arr1)
arr2 = np.array([10, 20, 30]) # 形状:(3,)
print("arr2:", arr2)
result = arr1 + arr2
print("广播规则2结果: \n", result)
"""
arr1:
[[1 2 3]
[4 5 6]]
arr2: [10 20 30]
广播规则2结果:
[[11 22 33]
[14 25 36]]
"""
说明: 在进行广播时,NumPy会从最右边的维度开始比较。在这种情况下,arr2 的最右边的维度大小为 3,而 arr1 的对应维度大小也为 3。满足规则2,可以进行广播。
3.4 规则3-示例说明
如果两个数组在某个维度上的大小既不相同也不为1,则广播会失败,导致 ValueError。
import numpy as np
if __name__ == '__main__':
arr1 = np.array([[1, 2, 3], [4, 5, 6]]) # 形状:(2, 3)
print("arr1:\n ", arr1)
arr2 = np.array([10, 20]) # 形状:(2,)
print("arr2:", arr2)
try:
result = arr1 + arr2
except ValueError as e:
result = "ValueError: {}".format(e)
print("广播规则3结果:", result)
"""
arr1:
[[1 2 3]
[4 5 6]]
arr2: [10 20]
广播规则3结果: ValueError: operands could not be broadcast together with shapes (2,3) (2,)
"""
说明: 在进行广播时,NumPy会从最右边的维度开始比较。在这种情况下,arr2 的最右边的维度的大小为2,而 arr1 的对应维度的大小为3。这两个大小既不相同,也不为1,因此广播规则3被触发,导致广播失败。
4. 矩阵运算
4.1 创建矩阵
在NumPy中,矩阵本质上也是一个数组,拥有数组的所有属性和方法;但矩阵又有一些不同于数组的特性和方法。如下:
-
矩阵是二维的,不能像数组一样幻化成任意维度。 -
矩阵的乘法不同于数组乘法。
在NumPy中,可以使用np.mat()和np.matrix()创建矩阵,如下代码示例:
import numpy as np
if __name__ == '__main__':
# 使用np.matrix创建矩阵
matrix_a = np.matrix([[1, 2], [3, 4]])
print("matrix_a: \n {} \n matrix_a类型:{}".format(matrix_a, type(matrix_a)))
# 使用mat创建矩阵
matrix_b = np.mat(np.arange(4).reshape(2, 2))
print("matrix_b: \n {} \n matrix_b类型:{}".format(matrix_b, type(matrix_b)))
"""
matrix_a:
[[1 2]
[3 4]]
matrix_a类型:<class 'numpy.matrix'>
matrix_b:
[[0 1]
[2 3]]
matrix_b类型:<class 'numpy.matrix'>
"""
4.2 矩阵特有属性
矩阵有几个特有的属性,如转置矩阵、逆矩阵、共轭矩阵、共轭转置矩阵等
import numpy as np
if __name__ == '__main__':
# 使用mat创建矩阵
matrix_a = np.mat(np.arange(6).reshape(2, 3))
print("matrix_a: \n", matrix_a)
# 获取其转置矩阵
print("matrix_a转置矩阵: \n", matrix_a.T)
# 获取其共轭转置矩阵
print("matrix_a共轭转置矩阵: \n", matrix_a.H)
# 获取其逆矩阵
print("matrix_a逆矩阵: \n", matrix_a.I)
# 获取其数据的视图(ndarray类)
print("matrix_a其数据的视图: \n", matrix_a.A)
print("matrix_a其数据的视图-类型: \n", type(matrix_a.A))
"""
matrix_a:
[[0 1 2]
[3 4 5]]
matrix_a转置矩阵:
[[0 3]
[1 4]
[2 5]]
matrix_a共轭转置矩阵:
[[0 3]
[1 4]
[2 5]]
matrix_a逆矩阵:
[[-0.77777778 0.27777778]
[-0.11111111 0.11111111]
[ 0.55555556 -0.05555556]]
matrix_a其数据的视图:
[[0 1 2]
[3 4 5]]
matrix_a其数据的视图-类型:
<class 'numpy.ndarray'>
"""
4.3 矩阵乘法
并不是所有的矩阵都可以直接相乘,需要满足一定规则,才可以进行矩阵乘法运算,规则如下:
-
列数等于行数: 第一个矩阵的列数必须等于第二个矩阵的行数。如果第一个矩阵的形状是 (m, n),那么第二个矩阵的形状应该是(n, p)。两个矩阵相乘的结果将是一个新矩阵,其形状为(m, p)。 -
对应维度的大小要一致: 除了满足列数等于行数的条件外,对应维度的大小也需要一致。具体来说,第一个矩阵的列数要与第二个矩阵的行数一致。如: 矩阵 A 形状为 (3, 2)和矩阵 B 形状为(2, 4),对应维度的大小是2,它们是一致的。
import numpy as np
if __name__ == '__main__':
# 使用mat创建矩阵
matrix_a = np.mat(np.random.randint(1, 10, size=(4, 2)))
print("matrix_a: \n", matrix_a)
matrix_b = np.mat(np.random.randint(1, 10, size=(2, 3)))
print("matrix_b: \n", matrix_b)
print("matrix_dot: \n", matrix_a.dot(matrix_b))
print("matrix_dot2: \n", matrix_a * matrix_b)
"""
matrix_a:
[[4 1]
[8 2]
[7 8]
[3 4]]
matrix_b:
[[7 7 3]
[3 5 7]]
matrix_dot:
[[31 33 19]
[62 66 38]
[73 89 77]
[33 41 37]]
matrix_dot2:
[[31 33 19]
[62 66 38]
[73 89 77]
[33 41 37]]
"""
对于数组而言,使用
*相乘和使用np.dot函数相乘是完全不同的两种乘法;对于矩阵来说,不管是使用*相乘还是使用np.dot函数相乘,结果都是np.dot函数相乘的结果,因为矩阵没有对应元素相乘这个概念。
下图是两个矩阵相乘时,如果计算出结果的示意图
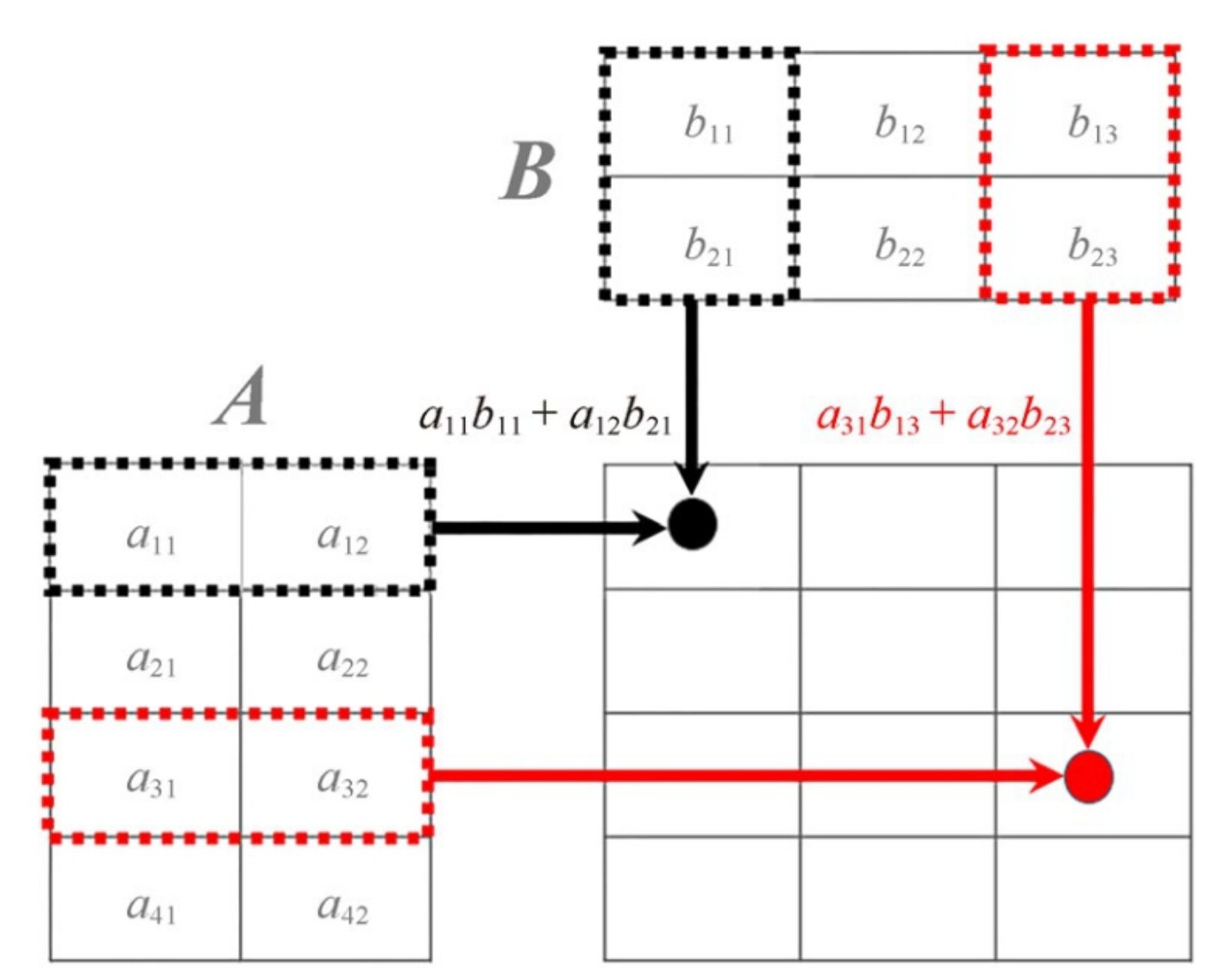
本文由 mdnice 多平台发布


![练[GYCTF2020]EasyThinking](https://img-blog.csdnimg.cn/img_convert/4f92eff3de45a3a5f254d1f13fe99f7b.png)