前言
监督学习往往需要大量的标注数据, 而标注数据的成本比较高 . 因此 , 利用大量的无标注数据来提高监督学习的效果有着十分重要的意义. 这种利用少量标注数据和大量无标注数据进行学习的方式称为 半监督学习 ( Semi-Supervised Learning, SSL ). 本文将介绍两种半监督学习算法 : 自训练和协同训练 .
自训练
自训练(Self-training )是一种半监督学习的方法,它通过结合有标签数据和无标签数据来提高模型的性能。在自训练中,首先使用有标签数据进行初始模型的训练,然后使用该模型对无标签数据进行预测,并将置信度较高的预测结果作为伪标签加入到有标签数据集中,再重新训练模型。通过迭代这个过程,逐步扩充有标签数据集和改进模型。

协同训练
协同训练 ( Co-Training ) 是自训练的一种改进方法 , 通过两个基于不同 视角 ( view ) 的分类器来互相促进. 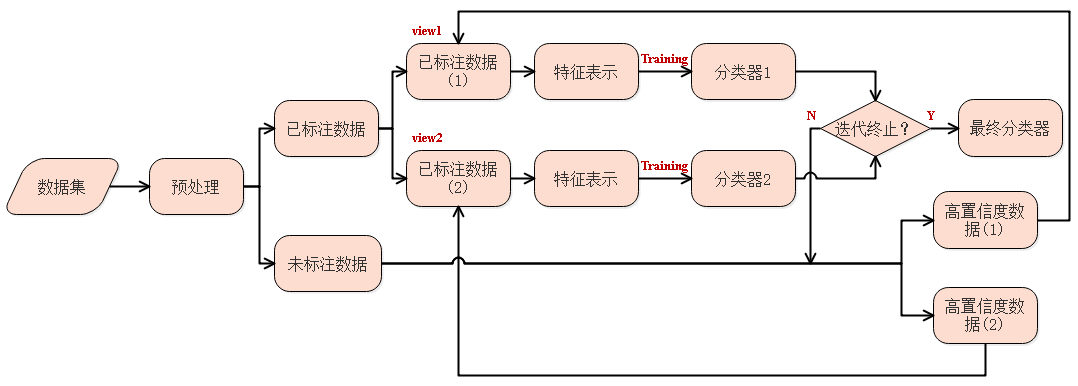
协同训练结构图
由于不同视角的条件独立性, 在不同视角上训练出来的模型就相当于从不同视角来理解问题, 具有一定的互补性 . 协同训练就是利用这种互补性来进行自训练的一种方法.
首先在训练集上根据不同视角分别训练两个模型𝑓 1 和 𝑓 2 ,然后用 𝑓 1 和 𝑓2 在无标注数据集上进行预测,各选取预测置信度比较高的样本加入训练集,重新训练两个不同视角的模型,并不断重复这个过程.
协同训练的基本框架如下:
1. 初始阶段:将有标签数据集随机分成两个子集,分别为视角 1 和视角 2 。使用视角 1 的特征训练模型 1 ,使用视角 2 的特征训练模型 2 。
2. 交替迭代:在每次迭代中,使用已训练好的模型对无标签数据进行预测,并选择置信度较高的样本加入到相应的视角的有标签数据集中。
3. 模型更新:使用扩充后的有标签数据集重新训练模型 1 和模型 2 。
4. 重复步骤 2 和步骤 3 ,直到满足停止条件(如达到最大迭代次数或模型性能不再提升)。