文章目录
- EM算法
- 思路
- E步
- M步
- 直观感觉
- GMM模型
- VAE
- VAE思想
- 从GMM到VAE
- 公式推导
- 重参数
- VAE+神经网络
- 另一个视角的VAE
- 思想
- 为什么引入encoder
- 为什么要重参数
- 噪声与重建
- Discrete VAE
本文会从EM算法,GMM模型一步一步的的推导,在过渡到VAE模型,如果有熟悉的部分可以跳过。
Reference:
- [苏剑林] https://spaces.ac.cn/archives/5253
- Auto-Encoding Variational Bayes; arXiv:1312.6114 [stat.ML]
- 李宏毅 机器学习课程第六讲
- 机器学习白板推导 https://www.bilibili.com/video/BV1aE411o7qd/
EM算法
思路
首先回顾一下EM算法的过程:假设X是全体样本, θ \theta θ是全体参数。
那么MLE求解生成模型就是要求得一个 θ \theta θ,使得 P ( X ∣ θ ) P(X|\theta) P(X∣θ)最大。(因为假设X是抽自于某个分布)
也就是如下式子:
θ ^ = arg max θ P ( X ∣ θ ) \hat \theta = \argmax\limits_{\theta} P(X|\theta) θ^=θargmaxP(X∣θ)
一般为了方便求解,会加上一个log。
θ ^ = arg max θ l o g P ( X ∣ θ ) \hat \theta = \argmax\limits_{\theta} logP(X|\theta) θ^=θargmaxlogP(X∣θ)
假设存在一个隐变量Z,这个隐变量可以生成X。
此时:
- X称之为观测数据
- Z称之为隐藏数据
- (X,Z)称之为完全数据
于是我们可以改写上面式子(以下均为恒等变换,不懂的可以从右向左推一遍)
l o g P ( X ∣ θ ) = l o g P ( X , Z ∣ θ ) − l o g P ( Z ∣ X , θ ) logP(X|\theta)=logP(X,Z|\theta)-logP(Z|X,\theta) logP(X∣θ)=logP(X,Z∣θ)−logP(Z∣X,θ)
l o g P ( X ∣ θ ) = l o g P ( X , Z ∣ θ ) Q ( Z ) − l o g P ( Z ∣ X , θ ) Q ( Z ) logP(X|\theta)=log\frac{P(X,Z|\theta)}{Q(Z)}-log\frac{P(Z|X,\theta)}{Q(Z)} logP(X∣θ)=logQ(Z)P(X,Z∣θ)−logQ(Z)P(Z∣X,θ)
然后两边同时乘以Q(Z)(这里表示这个隐变量Z的一个先验分布)再对Z积分,得到
左边 = ∫ z Q ( Z ) l o g P ( X ∣ θ ) d z = l o g P ( X ∣ θ ) 左边=\int_zQ(Z)logP(X|\theta)dz=logP(X|\theta) 左边=∫zQ(Z)logP(X∣θ)dz=logP(X∣θ)
右边 = ∫ z Q ( Z ) l o g [ P ( X , Z ∣ θ ) Q ( Z ) ] d z − ∫ z Q ( Z ) l o g [ P ( Z ∣ X , θ ) Q ( Z ) ] d z 右边=\int_zQ(Z)log[\frac{P(X,Z|\theta)}{Q(Z)}]dz-\int_zQ(Z)log[\frac{P(Z|X,\theta)}{Q(Z)}]dz 右边=∫zQ(Z)log[Q(Z)P(X,Z∣θ)]dz−∫zQ(Z)log[Q(Z)P(Z∣X,θ)]dz
可以发现,右边的项是KL Divergence。也就是说:
− ∫ z Q ( Z ) l o g [ P ( Z ∣ X , θ ) Q ( Z ) ] d z = K L ( Q ( Z ) ∣ ∣ P ( Z ∣ X , θ ) ) ≥ 0 -\int_zQ(Z)log[\frac{P(Z|X,\theta)}{Q(Z)}]dz=KL(Q(Z)||P(Z|X, \theta)) \ge 0 −∫zQ(Z)log[Q(Z)P(Z∣X,θ)]dz=KL(Q(Z)∣∣P(Z∣X,θ))≥0
我们记左边的项为ELBo,也就是一个下界
那么
l o g ( P ( X ∣ θ ) ) = E L B o + K L ≥ E L B o = ∫ z Q ( Z ) l o g [ P ( X , Z ∣ θ ) Q ( Z ) ] d z log(P(X|\theta))=ELBo+KL\ge ELBo=\int_zQ(Z)log[\frac{P(X,Z|\theta)}{Q(Z)}]dz log(P(X∣θ))=ELBo+KL≥ELBo=∫zQ(Z)log[Q(Z)P(X,Z∣θ)]dz
由于KL的非负性,所以上述等式成立,也就是说我们找到了 l o g ( P ( X ∣ θ ) ) log(P(X|\theta)) log(P(X∣θ))的一个下界。我们只需要不断地优化提高这个下界,就可以使得其目标函数不断提高(其实这里还需要证明收敛性,不过略过)
E步
当我们固定 θ , X \theta, X θ,X时,左边( l o g ( P ( X ∣ θ ) ) log(P(X|\theta)) log(P(X∣θ)))是不变的,而右边我们想要提高下界ELBo。就可以通过最小化KL。KL最小时就是两个分布完全一致,也就说是当:
Q ( Z ) = P ( Z ∣ X , θ ) Q(Z)=P(Z|X, \theta) Q(Z)=P(Z∣X,θ)
时,ELBo最大,此时我们得到了Z的先验分布就是 Q ( Z ) = P ( Z ∣ X , θ ) Q(Z)=P(Z|X, \theta) Q(Z)=P(Z∣X,θ)
注意,此时我们固定了 θ \theta θ,所以我们不妨记此时的 θ \theta θ为 θ ( t ) \theta^{(t)} θ(t)也就是当前t时刻的的值。
Q ( Z ) = P ( Z ∣ X , θ ( t ) ) Q(Z)=P(Z|X, \theta^{(t)}) Q(Z)=P(Z∣X,θ(t))
M步
在E步中找到了Q的分布后,我们需要寻找在当前Q下能够让 l o g P ( X ∣ θ ) logP(X|\theta) logP(X∣θ)尽可能大的 θ \theta θ。
也就是说我们要最大化ELBo:
θ ^ = arg max θ ∫ z Q ( Z ) l o g [ P ( X , Z ∣ θ ) Q ( Z ) ] d z \hat\theta=\argmax\limits_{\theta} \int_zQ(Z)log[\frac{P(X,Z|\theta)}{Q(Z)}]dz θ^=θargmax∫zQ(Z)log[Q(Z)P(X,Z∣θ)]dz
我们替换ELBo的Q(Z)为M步得到的值,于是得到下面的式子:
θ ^ ( t + 1 ) = arg max θ ∫ z P ( Z ∣ X , θ ( t ) ) l o g [ P ( X , Z ∣ θ ) P ( Z ∣ X , θ ( t ) ) ] d z \hat\theta^{(t+1)}=\argmax\limits_{\theta}\int_zP(Z|X, \theta^{(t)})log[\frac{P(X,Z|\theta)}{P(Z|X, \theta^{(t)})}] dz θ^(t+1)=θargmax∫zP(Z∣X,θ(t))log[P(Z∣X,θ(t))P(X,Z∣θ)]dz
我们把log中的除法拆成加法:
θ ^ ( t + 1 ) = arg max θ ∫ z P ( Z ∣ X , θ ( t ) ) l o g [ P ( X , Z ∣ θ ) ] − P ( Z ∣ X , θ ( t ) ) l o g [ P ( Z ∣ X , θ ( t ) ) ] d z \hat\theta^{(t+1)}=\argmax\limits_{\theta}\int_zP(Z|X, \theta^{(t)})log[P(X,Z|\theta)] -P(Z|X, \theta^{(t)})log[P(Z|X, \theta^{(t)})] dz θ^(t+1)=θargmax∫zP(Z∣X,θ(t))log[P(X,Z∣θ)]−P(Z∣X,θ(t))log[P(Z∣X,θ(t))]dz
可以发现,后面的 − P ( Z ∣ X , θ ( t ) ) l o g [ P ( Z ∣ X , θ ( t ) ) -P(Z|X, \theta^{(t)})log[P(Z|X, \theta^{(t)}) −P(Z∣X,θ(t))log[P(Z∣X,θ(t))与 θ \theta θ无关,所以可以舍弃。于是我们得到了M步的目标:
θ ^ ( t + 1 ) = arg max θ ∫ z P ( Z ∣ X , θ ( t ) ) l o g [ P ( X , Z ∣ θ ) ] d z \hat\theta^{(t+1)}=\argmax\limits_{\theta}\int_zP(Z|X, \theta^{(t)})log[P(X,Z|\theta)] dz θ^(t+1)=θargmax∫zP(Z∣X,θ(t))log[P(X,Z∣θ)]dz
我们可以进一步改写上面的式子为期望的形式:
θ ^ ( t + 1 ) = E Z ∣ X , θ ( t ) [ l o g [ P ( X , Z ∣ θ ) ] ] \hat\theta^{(t+1)}=E_{Z|X,\theta^{(t)}}[log[P(X,Z|\theta)]] θ^(t+1)=EZ∣X,θ(t)[log[P(X,Z∣θ)]]
至此,期望最大化算法(EM)算法推导结束(除了收敛性证明)
直观感觉
直观的来看EM算法的两步可以归为如下步骤:
- 固定 θ \theta θ,然后寻找Z的先验P(Z),使得ELBo尽可能的大
- 解除 θ \theta θ的固定,然后在E步找到的P(Z)的前提下,最大化ELBo提升下界
GMM模型
高斯混合模型是一种生成模型,它假定存在着一个隐变量Z,Z是一个离散的概率分布,有K个取值,如下:
Z = 1 , 2.. , k P ( Z = i ) = p i ( i ∈ { 1 , 2.. , k } ) ∑ i p i = 1 Z=1,2..,k\\P(Z=i)=p_i(i \in \{1,2..,k\})\\\sum_ip_i=1 Z=1,2..,kP(Z=i)=pi(i∈{1,2..,k})i∑pi=1
然后,我们所要建模 P ( X ∣ θ ) P(X|\theta) P(X∣θ)由k个高斯分布乘以对应的z的概率值构成,也就是:
P ( X ∣ θ ) = ∑ i = 1 k p i N ( X ∣ Σ i , μ i ) P(X|\theta)=\sum_{i=1}^k p_iN(X|\Sigma_i, \mu_i) P(X∣θ)=i=1∑kpiN(X∣Σi,μi)
也就是说,有K个高斯分布组成了要建模的分布,这K个高斯分布的线性组合就是我们要求的分布。
其中:
θ = { Σ 1 , Σ 2 . . . Σ k , μ 1 , μ 2 . . . , μ k , p 1 , p 2 . . . p k } \theta=\{\Sigma_1,\Sigma_2...\Sigma_k, \mu_1, \mu_2..., \mu_k, p_1,p_2...p_k\} θ={Σ1,Σ2...Σk,μ1,μ2...,μk,p1,p2...pk}
GMM模型显然是一个含有隐变量的模型,二期我们可以直接通过EM算法来进行求解,但这里主要是为了讲解VAE。所以不写如何求解GMM了。
VAE
VAE思想
VAE的假设很简单:
- 存在着隐随机变量Z,该变量有一个先验分布 P θ ( Z ) P_\theta(Z) Pθ(Z)
- 从先验分布 P θ ( Z ) P_\theta(Z) Pθ(Z)中抽取样本z
- 由样本z得到条件分布 P θ ( X ∣ Z = z ) P_\theta(X|Z=z) Pθ(X∣Z=z),然后抽样得到X

如上图所示,隐变量Z决定了X的生成 ( 先忽略参数 ϕ ) (先忽略参数\phi) (先忽略参数ϕ)
以上就是VAE假设的样本生成过程。
从GMM到VAE
可以看到和GMM非常相似,但是这里VAE与GMM有所不同,因为VAE假设的Z是高维,连续的,这就带来了几个问题:
P θ ( X ) = ∫ z P θ ( Z ) P θ ( X ∣ Z ) d z P_\theta(X)=\int_z P_\theta(Z)P_\theta(X|Z) dz Pθ(X)=∫zPθ(Z)Pθ(X∣Z)dz
上述式子是我们熟悉的概率乘条件概率的式子,相当于GMM中的高斯分布线性组合。不过这里显然是无穷个高斯分布(因为积分是连续的)。
但是比较尴尬的问题出现了,这个积分是高维的,我们无法对其求解(也就是说是intractable的)。也就是说我们求解得到 P ( X ) P(X) P(X)。
那么用EM算法是否可以呢?这里也很难,因为EM算法的E步骤需要令:
Q θ ( Z ) = P θ ( Z ∣ X ) Q_\theta(Z)=P_\theta(Z|X) Qθ(Z)=Pθ(Z∣X)
而 P θ ( Z ∣ X ) P_\theta(Z|X) Pθ(Z∣X)而想要求这个分布也是intractable(因为需要用到 P ( X ) P(X) P(X)),所以我们无法直接求出。
于是我们改其道而行,我们另外找一个分布 q θ ( Z ∣ X ) q_\theta(Z|X) qθ(Z∣X)我们让这个分布无限的去逼近 P θ ( Z ∣ X ) P_\theta(Z|X) Pθ(Z∣X),也就是说两者的KL散度最小。
公式推导
我们重回到EM算法的最开始步骤,我们将第i个样本P(x^{(i)})拆解为KL和ELBo
l o g P ( x ( i ) ) = E L B o + K L ≥ E L B o logP(x^{(i)})=ELBo+KL \ge ELBo logP(x(i))=ELBo+KL≥ELBo
注意,KL的公式如下:
K L ( q ( z ) ∣ P ( z ∣ x ( i ) , θ ) ) KL(q(z)|P(z|x^{(i)},\theta)) KL(q(z)∣P(z∣x(i),θ))
我们把 q ( z ) q(z) q(z)替换为 Q ϕ ( z ∣ x ( i ) ) Q_\phi(z|x^{(i)}) Qϕ(z∣x(i)),于是就可以发现,其实我们就是在逼近这两者的分布。
于是我们得到了:
l o g P ( x ( i ) ) ≥ E L B o = E Q ϕ ( z ∣ x ( i ) ) [ l o g P θ ( x ( i ) , z ) − l o g Q ϕ ( z ∣ x ( i ) ) ] logP(x^{(i)})\ge ELBo = E_{Q_\phi(z|x^{(i)})}[logP_\theta(x^{(i)},z)-logQ_\phi(z|x^{(i)})] logP(x(i))≥ELBo=EQϕ(z∣x(i))[logPθ(x(i),z)−logQϕ(z∣x(i))]
这是一个下界,显然如同EM一样,我们只需要提高这个下界就可以不断地扩大 l o g P ( x ( i ) ) logP(x^{(i)}) logP(x(i))还能同时把 Q ϕ ( z ∣ x ( i ) ) Q_\phi(z|x^{(i)}) Qϕ(z∣x(i))给解出来。
我们进一步的进行变形(一下X可以看做是 x ( i ) x^{(i)} x(i)):
E Q ϕ ( Z ∣ X ) [ l o g P θ ( X , Z ) − l o g Q ϕ ( Z ∣ X ) ] = E Q ϕ ( Z ∣ X ) [ l o g P θ ( X ∣ Z ) + l o g P θ ( Z ) − l o g Q ϕ ( Z ∣ X ) ] = E Q ϕ ( Z ∣ X ) [ l o g P θ ( X ∣ Z ) + l o g P θ ( Z ) Q ϕ ( Z ∣ X ) ] = E Q ϕ ( Z ∣ X ) [ l o g P θ ( X ∣ Z ) ] − K L ( Q ϕ ( Z ∣ X ) ∣ ∣ P θ ( Z ) ) E_{Q_\phi(Z|X)}[logP_\theta(X,Z)-logQ_\phi(Z|X)]=\\E_{Q_\phi(Z|X)}[logP_\theta(X|Z) + logP_\theta(Z)-logQ_\phi(Z|X)]=\\E_{Q_\phi(Z|X)}[logP_\theta(X|Z) + log\frac{P_\theta(Z)}{Q_\phi(Z|X)}]=\\E_{Q_\phi(Z|X)}[logP_\theta(X|Z)] -KL(Q_\phi(Z|X)||P_\theta(Z)) EQϕ(Z∣X)[logPθ(X,Z)−logQϕ(Z∣X)]=EQϕ(Z∣X)[logPθ(X∣Z)+logPθ(Z)−logQϕ(Z∣X)]=EQϕ(Z∣X)[logPθ(X∣Z)+logQϕ(Z∣X)Pθ(Z)]=EQϕ(Z∣X)[logPθ(X∣Z)]−KL(Qϕ(Z∣X)∣∣Pθ(Z))
于是我们得到了最终的形式:
l o g P ( x ( i ) ) ≥ E Q ϕ ( z ∣ x ) [ l o g P θ ( x ( i ) ∣ z ) ] − K L ( Q ϕ ( z ∣ x ( i ) ) ∣ ∣ P θ ( z ) ) logP(x^{(i)})\ge E_{Q_\phi(z|x)}[logP_\theta(x^{(i)}|z)] -KL(Q_\phi(z|x^{(i)})||P_\theta(z)) logP(x(i))≥EQϕ(z∣x)[logPθ(x(i)∣z)]−KL(Qϕ(z∣x(i))∣∣Pθ(z))
从上面我们可以看出一些有意思的事,我们期望最大化ELBo,也就是说我们要最小化 K L ( Q ϕ ( z ∣ x ( i ) ) ∣ ∣ P θ ( z ) ) KL(Q_\phi(z|x^{(i)})||P_\theta(z)) KL(Qϕ(z∣x(i))∣∣Pθ(z))
就是说让这两个分布尽可能的接近,也就是说这里其实 Q ϕ ( z ∣ x ( i ) ) Q_\phi(z|x^{(i)}) Qϕ(z∣x(i))近似了 P θ ( z ) P_\theta(z) Pθ(z)。
这里可以看做一定encode的能力,给定数据X,然后生成隐变量的值Z。
然后另一部分可以看做要最大化给定Z时,还原出X的期望。也就是Decode的过程。
至此从优化的目标函数上来看,我们已经找到了Encoder和Decoder的两个相关优化目标。
到这里,为了优化这个目标,我们可以使用梯度上升的的方式,也就是对 ϕ \phi ϕ进行求导,然后再用蒙特卡洛采样得到梯度的近似值。
我们记
L ( θ , ϕ ; x ( i ) ) = E L B o = E Q ϕ ( z ∣ x ( i ) ) [ l o g P θ ( x ( i ) , z ) − l o g Q ϕ ( z ∣ x ( i ) ) ] L(\theta, \phi; x^{(i)})=ELBo=E_{Q_\phi(z|x^{(i)})}[logP_\theta(x^{(i)},z)-logQ_\phi(z|x^{(i)})] L(θ,ϕ;x(i))=ELBo=EQϕ(z∣x(i))[logPθ(x(i),z)−logQϕ(z∣x(i))]
我们令 f ( z ) = l o g P θ ( x ( i ) , z ) − l o g Q ϕ ( z ∣ x ( i ) ) f(z)=logP_\theta(x^{(i)},z)-logQ_\phi(z|x^{(i)}) f(z)=logPθ(x(i),z)−logQϕ(z∣x(i))
那么我们要求的梯度就是(以下 Q ϕ ( z ∣ x ( i ) ) Q_\phi(z|x^{(i)}) Qϕ(z∣x(i))记做 Q ϕ Q_\phi Qϕ)
∇ ϕ E Q ϕ [ f ( z ) ] = ∇ ϕ ∫ z Q ϕ f ( z ) d z = ∫ z ∇ ϕ Q ϕ f ( z ) d z = ∫ z f ( z ) Q ϕ ∇ Q ϕ l o g ( Q ϕ ) d z = E Q ϕ [ f ( z ) ∇ Q ϕ l o g ( Q ϕ ) ] \nabla_\phi E_{Q_\phi}[f(z)]=\nabla_\phi\int_zQ_\phi f(z) dz=\int_z\nabla_\phi Q_\phi f(z) dz \\=\int_zf(z)Q_\phi \nabla_{Q_\phi}log(Q_{\phi}) dz=E_{Q_\phi}[f(z)\nabla_{Q_\phi} log(Q_{\phi})] ∇ϕEQϕ[f(z)]=∇ϕ∫zQϕf(z)dz=∫z∇ϕQϕf(z)dz=∫zf(z)Qϕ∇Qϕlog(Qϕ)dz=EQϕ[f(z)∇Qϕlog(Qϕ)]
这里其实利用到了一个很有趣的性质 f ′ ( x ) = f ( x ) ∗ ( l o g f ( x ) ) ′ f'(x)=f(x)*(logf(x))' f′(x)=f(x)∗(logf(x))′于是把原本求的积分内的梯度再次变回了一个期望的形式。
而这个期望就可以使用蒙特卡洛的方式进行近似逼近了。
但是此时存在着一个问题

如图是VAE原论文中的蒙特卡洛近似后的结果,也就是用随机采样的得到的样本的计算后的均值近似原本的均值,这里存在着一个 z ( l ) z^{(l)} z(l),是从 Q ϕ ( z ∣ x ( i ) ) Q_{\phi}(z|x^{(i)}) Qϕ(z∣x(i))中抽样的,这个log就会造成很大的方差(因为越靠近0,就越陡峭)。
蒙特卡洛估计本身就是近似,方差又打再加上随机梯度下降的不确定性。所以导致很难进行优化。于是就引入了重参数技巧.
重参数
之所以出现了log,是因为对原本作为期望的分布 Q ϕ ( z ∣ x ( i ) ) Q_{\phi}(z|x^{(i)}) Qϕ(z∣x(i))进行了求导。于是坐着引入了一个新的变量 ϵ \epsilon ϵ,这个变量来与z产生关系:
z ~ ∼ g ϕ ( ϵ , x ( i ) ) ϵ ∼ p ( ϵ ) \tilde z\sim g_\phi(\epsilon,x^{(i)}) \\ \epsilon \sim p(\epsilon) z~∼gϕ(ϵ,x(i))ϵ∼p(ϵ)
可以注意到:
∫ Q ϕ ( z ∣ x ) f ( z ) d z = ∫ p ( ϵ ) f ( z ) d ϵ = ∫ p ( ϵ ) f ( g ϕ ( ϵ , x ( i ) ) ) d ϵ \int Q_\phi (z|x) f(z) dz=\int p(\epsilon) f(z) d\epsilon=\int p(\epsilon) f(g_\phi(\epsilon,x^{(i)})) d\epsilon ∫Qϕ(z∣x)f(z)dz=∫p(ϵ)f(z)dϵ=∫p(ϵ)f(gϕ(ϵ,x(i)))dϵ
此时我们就可以直接的估计出 E Q ϕ [ f ( z ) ] E_{Q_\phi}[f(z)] EQϕ[f(z)]
于是我们就得到:
E Q ϕ [ f ( z ) ] = E p ( ϵ ) [ f ( g ϕ ( ϵ , x ( i ) ) ) ] E_{Q_\phi}[f(z)]=E_{p(\epsilon)}[f(g_\phi(\epsilon,x^{(i)}))] EQϕ[f(z)]=Ep(ϵ)[f(gϕ(ϵ,x(i)))]
于是我们得到了一个估计值:
E p ( ϵ ) [ f ( g ϕ ( ϵ , x ( i ) ) ) ] ≈ 1 L ∑ i = 1 L f ( g ϕ ( ϵ ( i ) , x ( i ) ) ) 其中 ϵ i 采样于 p ( ϵ ) E_{p(\epsilon)}[f(g_\phi(\epsilon,x^{(i)}))]\approx \frac{1}{L}\sum_{i=1}^Lf(g_\phi(\epsilon^{(i)},x^{(i)}))\\其中\epsilon_i 采样于p(\epsilon) Ep(ϵ)[f(gϕ(ϵ,x(i)))]≈L1i=1∑Lf(gϕ(ϵ(i),x(i)))其中ϵi采样于p(ϵ)
然后我们重写L的式子:
L ( θ , ϕ ; x ( i ) ) = E L B o = E p ( ϵ ) [ l o g P θ ( x ( i ) , z ) − l o g Q ϕ ( z ∣ x ( i ) ) ] L(\theta, \phi; x^{(i)})=ELBo=E_{p(\epsilon)}[logP_\theta(x^{(i)},z)-logQ_\phi(z|x^{(i)})] L(θ,ϕ;x(i))=ELBo=Ep(ϵ)[logPθ(x(i),z)−logQϕ(z∣x(i))]
= 1 L ∑ l = 1 L l o g P θ ( x ( i ) , g ϕ ( ϵ ( l ) , x ( i ) ) ) − l o g Q ϕ ( g ϕ ( ϵ ( l ) , x ( i ) ) ∣ x ( i ) ) 其中 ϵ i 采样于 p ( ϵ ) = \frac{1}{L}\sum_{l=1}^L logP_\theta(x^{(i)},g_\phi(\epsilon^{(l)},x^{(i)})) - logQ_\phi(g_\phi(\epsilon^{(l)},x^{(i)})|x^{(i)})\\其中\epsilon_i 采样于p(\epsilon) =L1l=1∑LlogPθ(x(i),gϕ(ϵ(l),x(i)))−logQϕ(gϕ(ϵ(l),x(i))∣x(i))其中ϵi采样于p(ϵ)
由于KL散度经常可以直接被计算出来,所以我们也可以写成如下的式子:
= − K L ( Q ϕ ( z ∣ x ( i ) ) ∣ ∣ P θ ( z ) ) + 1 L ∑ l = 1 L l o g P θ ( x ( i ) ∣ g ϕ ( ϵ ( l ) , x ( i ) ) ) 其中 ϵ i 采样于 p ( ϵ ) = -KL(Q_\phi(z|x^{(i)})||P_\theta(z))+\frac{1}{L}\sum_{l=1}^L logP_\theta(x^{(i)}|g_\phi(\epsilon^{(l)},x^{(i)}))\\其中\epsilon_i 采样于p(\epsilon) =−KL(Qϕ(z∣x(i))∣∣Pθ(z))+L1l=1∑LlogPθ(x(i)∣gϕ(ϵ(l),x(i)))其中ϵi采样于p(ϵ)
此时上述的式子就是近似可微的了,这个结果可以直接通过SGD求解。
VAE+神经网络
我们来举一个VAE+神经网络的例子,我们具体化上述抽象的分布和函数:
- g ϕ ( x ( i ) , ϵ ( l ) ) = μ ( i ) + σ ( i ) ⊙ ϵ ( l ) g_\phi(x^{(i)}, \epsilon^{(l)})=\mu^{(i)} + \sigma^{(i)}\odot \epsilon^{(l)} gϕ(x(i),ϵ(l))=μ(i)+σ(i)⊙ϵ(l)
- ϵ ∼ N ( 0 , I ) \epsilon\sim N(0,I) ϵ∼N(0,I)
- z ∼ N ( 0 , I ) z\sim N(0,I) z∼N(0,I)
- Q ϕ ( z ∣ x ( i ) ) = N ( Z ; μ ( i ) , σ 2 ( i ) I ) Q_\phi(z|x^{(i)})=N(Z;\mu^{(i)}, \sigma^{2(i)}I) Qϕ(z∣x(i))=N(Z;μ(i),σ2(i)I)
上述的 μ ( i ) \mu^{(i)} μ(i)和 σ 2 ( i ) \sigma^{2(i)} σ2(i)都是由x得到的,也就是说我们需要训练一个encoder,来输入x获得上述两个部分:
e n c o d e r ( x ( i ) ) = ( μ ( i ) , σ 2 ( i ) ) encoder(x^{(i)})=(\mu^{(i)}, \sigma^{2(i)}) encoder(x(i))=(μ(i),σ2(i))
其中这个encoder就是一个神经网络。
然后我们用另一个神经网络来拟合概率分布 p θ ( x ∣ z ) p_{\theta}(x|z) pθ(x∣z)
于是就有了decoder。
接下来我么们来计算损失函数:
L ( θ , ϕ ; x ( i ) ) = − K L ( Q ϕ ( z ∣ x ( i ) ) ∣ ∣ P θ ( z ) ) + 1 L ∑ l = 1 L l o g P θ ( x ( i ) ∣ g ϕ ( ϵ ( l ) , x ( i ) ) ) 其中 ϵ i 采样于 p ( ϵ ) L(\theta, \phi; x^{(i)})= -KL(Q_\phi(z|x^{(i)})||P_\theta(z))+\frac{1}{L}\sum_{l=1}^L logP_\theta(x^{(i)}|g_\phi(\epsilon^{(l)},x^{(i)}))\\其中\epsilon_i 采样于p(\epsilon) L(θ,ϕ;x(i))=−KL(Qϕ(z∣x(i))∣∣Pθ(z))+L1l=1∑LlogPθ(x(i)∣gϕ(ϵ(l),x(i)))其中ϵi采样于p(ϵ)
第二项变成:
1 L ∑ l = 1 L l o g P θ ( x ( i ) , g ϕ ( ϵ ( l ) , x ( i ) ) ) = 1 L ∑ l = 1 L l o g P θ ( x ( i ) ∣ μ ( i ) + σ ( i ) ⊙ ϵ ( l ) ) \frac{1}{L}\sum_{l=1}^L logP_\theta(x^{(i)},g_\phi(\epsilon^{(l)},x^{(i)}))=\frac{1}{L}\sum_{l=1}^L logP_\theta(x^{(i)}|\mu^{(i)} + \sigma^{(i)}\odot \epsilon^{(l)}) L1l=1∑LlogPθ(x(i),gϕ(ϵ(l),x(i)))=L1l=1∑LlogPθ(x(i)∣μ(i)+σ(i)⊙ϵ(l))
而第一项KL散度通过积分可以得到:
(这里的具体推导可以看下面另一个视角的VAE那里)

其中J是 σ \sigma σ的维度。
然后就是decoder损失函数的选择:
如果是二值数据,那么此时可以使用n重伯努利分布:
P θ ( x ∣ z ) = ∏ k = 1 D p ( z ) k x k ( 1 − p ( z ) k ) ( 1 − x k ) P_\theta(x|z)=\prod\limits_{k=1}^D p(z)_k^{x_k}(1-p(z)_k)^{(1-x_k)} Pθ(x∣z)=k=1∏Dp(z)kxk(1−p(z)k)(1−xk)
− l o g P θ ( x ∣ z ) = ∑ k = 1 D − x k l o g p ( z ) k − ( 1 − x k ) l o g ( 1 − p ( z ) k ) -logP_\theta(x|z)=\sum\limits_{k=1}^D -x_klogp(z)_k-(1-x_k)log(1-p(z)_k) −logPθ(x∣z)=k=1∑D−xklogp(z)k−(1−xk)log(1−p(z)k)
可以看到这其实就是cross entropy。也就是交叉熵作为损失函数。
如果是一般的数据可以使用正态分布作为损失函数:
我们固定正态分布的sigma,就得到:
P θ ( x ∣ z ) = 1 C 1 e x p − C 2 ∣ ∣ x − μ ( z ) ∣ ∣ 2 P_\theta(x|z)=\frac{1}{C_1}exp^{-C_2||x-\mu(z)||^2} Pθ(x∣z)=C11exp−C2∣∣x−μ(z)∣∣2
当方差固定时,正态分布的一些参数可以用两个常数 C 1 , C 2 C_1,C_2 C1,C2代替,如上图。然后取对数
− l o g P θ ( x ∣ z ) = − l o g ( 1 C 1 ) + C 2 ∣ ∣ x − μ ( z ) ∣ ∣ 2 ≈ ∣ ∣ x − μ ( z ) ∣ ∣ 2 -logP_\theta(x|z)=-log(\frac{1}{C_1}) + C_2||x-\mu(z)||^2 \approx||x-\mu(z)||^2 −logPθ(x∣z)=−log(C11)+C2∣∣x−μ(z)∣∣2≈∣∣x−μ(z)∣∣2
也就是说是MSE损失函数,其中 μ ( z ) \mu(z) μ(z)可以看作是decoder的输出。
然后是采样,由于有多个epoch,所以每次采样一个就够了。
接下来上代码:
我们用交叉熵做损失函数,同时使用Minist作为数据集训练
from torch import nn
import torchclass VAE(nn.Module):def __init__(self, image_size=28, z_dim=100) -> None:super().__init__()self.encoder = nn.Sequential( #由若干卷积和一个全连接构成encodernn.Conv2d(in_channels=1, out_channels=20, kernel_size=3),nn.ReLU(),nn.Conv2d(in_channels=20, out_channels=20, kernel_size=3),nn.ReLU(),nn.Flatten(start_dim=1),nn.Linear(in_features=11520, out_features=800),nn.ReLU())self.sigma = nn.Linear(800, z_dim)self.mu = nn.Linear(800, z_dim)self.sigmoid = nn.Sigmoid()self.decoder = nn.Sequential( # 两个全连接构成decodernn.Linear(in_features=z_dim, out_features=2000),nn.ReLU(),nn.Linear(in_features=2000, out_features=image_size * image_size))def reparameterize(self, sigma, mu): # 冲参数计算,计算zsigma = torch.exp(sigma / 2) # 这里sigma可能非正,所以加了exp,然后开根号eps = torch.rand_like(sigma) # 抽样得到epsilonreturn mu + eps * sigmadef encode(self, x):hidden = self.encoder(x)sigma, mu = self.sigma(hidden), self.mu(hidden)return sigma, mudef decode(self, z):return self.decoder(z)def forward(self, x):sigma, mu = self.encode(x)z = self.reparameterize(sigma, mu)return sigma, mu, self.sigmoid(self.decode(z)) # 这里的sigmoid是为了计算交叉熵损失def loss_function(sigma, mu, x, reconstruct):BCE_loss = nn.BCELoss(reduction='sum')kl_divergece = -0.5 * torch.sum(1 + sigma - torch.exp(sigma) - mu ** 2) # 这里的sigma本来应该是正的,所以用exp来代替了x = torch.flatten(x, start_dim=1)cross = BCE_loss(reconstruct, x) # 交叉熵部分return kl_divergece + cross
下面是训练的部分
from model import VAE, loss_function
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision.utils import save_imageif __name__ == '__main__':BATCH_SIZE = 150LR = 0.001EPOCH = 100model = VAE().cuda()optim = torch.optim.Adam(lr=LR, params=model.parameters())data = torchvision.datasets.MNIST('./data', train=True, transform=torchvision.transforms.ToTensor(), download=True)dataloader = DataLoader(dataset=data, batch_size=BATCH_SIZE, shuffle=True)for epoch in range(EPOCH):for i, (imgs, labels) in enumerate(dataloader):imgs = imgs.cuda()sigma, mu, recon = model(imgs)loss = loss_function(sigma, mu, imgs, recon)optim.zero_grad()loss.backward()optim.step()if i % 50 == 0:print('loss', loss.item())fake_images = recon.view(-1, 1, 28, 28)[:5]x_concat = torch.cat([imgs.view(-1, 1, 28, 28)[:5, :], fake_images], dim=3)save_image(x_concat, 'generate_images/generate_images-{}-{}.png'.format(epoch + 1, i))torch.save(model.state_dict(), './model.pkl')





图中是数字对,每一对左边是原图,右边是VAE重建后的图片。
到此,VAE结束
另一个视角的VAE
思想
上述是从贝叶斯视角来看VAE的,全部都是公式,非常的不直接,让扔一头雾水,下来来从更intuitive的角度来看VAE:
先来看,高斯混合模型,相当于是把若干个高斯模型迭代并分别乘以一个离散的概率分布的概率作为权重:

其中P(m)就是这个概率,也是上面所说的隐变量z。
然后直观地来看,我们把这个高斯混合模型给一般化,把P(m)编程高维分布,也变成连续的分布,就得到了VAE:

如图,此时的z就是个标准的高维的正态分布。
其中我们有一项 P ( x ∣ z ) P(x|z) P(x∣z)这个我们用神经网络去模拟:

输入一个z,输出均值和方差,他们都是z的函数。
理论上来说到这里看似很完美了,P(z)是标准正态分布是已知的,而且 P ( x ∣ z ) P(x|z) P(x∣z)可以通过神经网络训练得来。似乎所有问题都解决了。
为什么引入encoder
但是问题在于这没法实现,首先,我们的目标是最大化似然函数 P ( X ∣ θ ) P(X|\theta) P(X∣θ),然后似然可以被拆做:
P θ ( X ) = ∫ z P θ ( Z ) P θ ( X ∣ Z ) d z P_\theta(X)=\int_z P_\theta(Z)P_\theta(X|Z) dz Pθ(X)=∫zPθ(Z)Pθ(X∣Z)dz
这个积分是无法积出来的,因为后项 P θ ( X ∣ Z ) P_\theta(X|Z) Pθ(X∣Z)是个神经网络。这样我们得不到损失函数。
另一个问题在于,P(z)与x是没有对应关系的,同一个P(z)抽出来的样本,可以对应相同的x。这可能会造成一系列麻烦:
于是VAE引入了另一个分布 Q ( z ∣ x ) Q(z|x) Q(z∣x)来取代原来的 P ( z ) P(z) P(z),这样解决了z没有指向性的问题。当然这个 Q ( z ∣ x ) Q(z|x) Q(z∣x)也是正态分布,我们也用一个神经网络去模拟:

输入一个x,同样的输出两个参数作为输出结果。
这样似乎我们的问题就解决了,但仍然存在问题:

如上图(来自于苏剑林的博客),是我们的步骤,这里有一个大问题那就是我们希望采样得到的z是的不确定性是由神经网络自己生成的(也就是方差sigma)。
也就是说神经网络完全可以偷懒,让这个方差直接为0,然后我们希望引入的采样的随机性就没了。于是我们引入了正则项,来要求 Q ( z ∣ x ) Q(z|x) Q(z∣x)朝着标准正态分布的方向逼近,也就是我们之前假设的先验分布P(z):
下面 z k z_k zk表示z的第k个纬度, x ( i ) x^{(i)} x(i)表示第i个样本
也就是 min K L ( N ( μ ( x ( i ) ) , σ ( x ( i ) ) ) ∣ ∣ N ( 0 , I ) ) = ∫ z N ( μ ( x ( i ) ) , σ ( x ( i ) ) ) l n N ( μ ( x ( i ) ) , σ ( x ( i ) ) ) N ( 0 , I ) d z \min KL(N(\mu(x^{(i)}), \sigma(x^{(i)}))||N(0,I))=\int_zN(\mu(x^{(i)}), \sigma(x^{(i)}))ln\frac{N(\mu(x^{(i)}), \sigma(x^{(i)}))}{N(0,I)}dz minKL(N(μ(x(i)),σ(x(i)))∣∣N(0,I))=∫zN(μ(x(i)),σ(x(i)))lnN(0,I)N(μ(x(i)),σ(x(i)))dz
我们假设各个分量之间是独立的,于是我们只用计算出第k维度即可
∫ − ∞ + ∞ 1 2 π σ k 2 ( x ( i ) ) e − ( z k − μ k ( x ( i ) ) ) 2 2 σ k ( x ( i ) ) 2 l n 1 2 π σ k 2 ( x ( i ) ) e − ( z k − μ k ( x ( i ) ) ) 2 2 σ k ( x ( i ) ) 2 1 2 π e − z k 2 2 d z k \int_{-\infin} ^{+\infin} \frac{1}{\sqrt{2\pi \sigma^2_k(x^{(i)})}}e^{-\frac{(z_k - \mu_k(x^{(i)}))^2}{2\sigma_k(x^{(i)})^2}} ln\frac{\frac{1}{\sqrt{2\pi \sigma^2_k(x^{(i)})}}e^{-\frac{(z_k - \mu_k(x^{(i)}))^2}{2\sigma_k(x^{(i)})^2}}}{\frac{1}{\sqrt{2\pi }}e^{-\frac{z_k^2}{2}}}dz_k ∫−∞+∞2πσk2(x(i))1e−2σk(x(i))2(zk−μk(x(i)))2ln2π1e−2zk22πσk2(x(i))1e−2σk(x(i))2(zk−μk(x(i)))2dzk
我们把后项进行化简:
= 1 2 ∫ − ∞ + ∞ 1 2 π σ k 2 ( x ( i ) ) e − ( z k − μ k ( x ( i ) ) ) 2 2 σ k ( x ( i ) ) 2 ( − l n σ k 2 ( x ( i ) ) ) + z k 2 − ( z k − μ k ( x ( i ) ) ) 2 σ k ( x ( i ) ) 2 ) d z k =\frac{1}{2}\int_{-\infin} ^{+\infin} \frac{1}{\sqrt{2\pi \sigma^2_k(x^{(i)})}}e^{-\frac{(z_k - \mu_k(x^{(i)}))^2}{2\sigma_k(x^{(i)})^2}}(-ln\sigma^2_k(x^{(i)}))+z_k^2 -\frac{(z_k - \mu_k(x^{(i)}))^2}{\sigma_k(x^{(i)})^2})dz_k =21∫−∞+∞2πσk2(x(i))1e−2σk(x(i))2(zk−μk(x(i)))2(−lnσk2(x(i)))+zk2−σk(x(i))2(zk−μk(x(i)))2)dzk
可以看到后面有三项需要分别和第一项相乘然后积分:
首先是:
− 1 2 ∫ − ∞ + ∞ 1 2 π σ k 2 ( x ( i ) ) e − ( z k − μ k ( x ( i ) ) ) 2 2 σ k ( x ( i ) ) 2 l n σ k 2 ( x ( i ) ) ) d z k = − 1 2 l n σ k 2 ( x ( i ) ) -\frac{1}{2}\int_{-\infin} ^{+\infin} \frac{1}{\sqrt{2\pi \sigma^2_k(x^{(i)})}}e^{-\frac{(z_k - \mu_k(x^{(i)}))^2}{2\sigma_k(x^{(i)})^2}}ln\sigma^2_k(x^{(i)}))dz_k =-\frac{1}{2}ln\sigma^2_k(x^{(i)}) −21∫−∞+∞2πσk2(x(i))1e−2σk(x(i))2(zk−μk(x(i)))2lnσk2(x(i)))dzk=−21lnσk2(x(i))
因为上述的积分就是个概率分布的积分,最后结果为1, − 1 2 l n σ k 2 ( x ( i ) ) -\frac{1}{2}ln\sigma^2_k(x^{(i)}) −21lnσk2(x(i))与x无关
1 2 ∫ − ∞ + ∞ 1 2 π σ k 2 ( x ( i ) ) e − ( z k − μ k ( x ( i ) ) ) 2 2 σ k ( x ( i ) ) 2 z k 2 d z k \frac{1}{2}\int_{-\infin} ^{+\infin} \frac{1}{\sqrt{2\pi \sigma^2_k(x^{(i)})}}e^{-\frac{(z_k - \mu_k(x^{(i)}))^2}{2\sigma_k(x^{(i)})^2}}z_k^2 dz_k 21∫−∞+∞2πσk2(x(i))1e−2σk(x(i))2(zk−μk(x(i)))2zk2dzk
这就是二阶中心距:
μ k ( x ( i ) ) 2 + σ k ( x ( i ) ) 2 \mu_k(x^{(i)})^2+\sigma_k(x^{(i)})^2 μk(x(i))2+σk(x(i))2
最后一项,展开之后得到:
( z k − μ k ( x ( i ) ) ) 2 σ k ( x ( i ) ) 2 = ( z k 2 − 2 z k μ k ( x ( i ) ) + μ k ( x ( i ) ) ) σ k ( x ( i ) ) 2 \frac{(z_k - \mu_k(x^{(i)}))^2}{\sigma_k(x^{(i)})^2}=\frac{(z_k^2 -2z_k\mu_k(x^{(i)}) + \mu_k(x^{(i)}))}{\sigma_k(x^{(i)})^2} σk(x(i))2(zk−μk(x(i)))2=σk(x(i))2(zk2−2zkμk(x(i))+μk(x(i)))
中间和前面相乘后积分直接为0,前面和后面也可以用二阶中心距和概率分布的定义直接计算
最后得到结果为-1
于是
∫ − ∞ + ∞ 1 2 π σ k 2 ( x ( i ) ) e − ( z k − μ k ( x ( i ) ) ) 2 2 σ k ( x ( i ) ) 2 l n 1 2 π σ k 2 ( x ( i ) ) e − ( z k − μ k ( x ( i ) ) ) 2 2 σ k ( x ( i ) ) 2 1 2 π e − z k 2 2 d z k = 1 2 ( − l n σ k 2 ( x ( i ) ) + μ k ( x ( i ) ) 2 + σ k ( x ( i ) ) 2 − 1 ) \int_{-\infin} ^{+\infin} \frac{1}{\sqrt{2\pi \sigma^2_k(x^{(i)})}}e^{-\frac{(z_k - \mu_k(x^{(i)}))^2}{2\sigma_k(x^{(i)})^2}} ln\frac{\frac{1}{\sqrt{2\pi \sigma^2_k(x^{(i)})}}e^{-\frac{(z_k - \mu_k(x^{(i)}))^2}{2\sigma_k(x^{(i)})^2}}}{\frac{1}{\sqrt{2\pi }}e^{-\frac{z_k^2}{2}}}dz_k=\frac{1}{2}(-ln\sigma^2_k(x^{(i)})+\mu_k(x^{(i)})^2+\sigma_k(x^{(i)})^2-1) ∫−∞+∞2πσk2(x(i))1e−2σk(x(i))2(zk−μk(x(i)))2ln2π1e−2zk22πσk2(x(i))1e−2σk(x(i))2(zk−μk(x(i)))2dzk=21(−lnσk2(x(i))+μk(x(i))2+σk(x(i))2−1)

为什么要重参数
然后是采样操作,实际上采样操作是不可行的,因为采样出来的值没法后续用X来进行优化(因为前半部分的encoder只有一个KL损失在约束,不受到后面的decoder的梯度传播)
所以必须要引入一个新变量来把采样过程的随机性独立出来,这就是重参数技巧
P ( z ∣ x ) = 1 σ ( x ( i ) ) 2 π e − ( x − μ ( x ( i ) ) ) 2 2 σ ( x ( i ) ) 2 ∼ N ( μ ( x ( i ) ) , σ ( x ( i ) ) 2 ) P(z|x)=\frac{1}{\sigma(x^{(i)})\sqrt{2\pi}}e^{-\frac{(x-\mu(x^{(i)}))^2}{2\sigma(x^{(i)})^2}}\sim N(\mu(x^{(i)}), \sigma(x^{(i)})^2) P(z∣x)=σ(x(i))2π1e−2σ(x(i))2(x−μ(x(i)))2∼N(μ(x(i)),σ(x(i))2)
我们引入另一个标准正态分布
ϵ ∼ N ( 0 , I ) \epsilon \sim N(0,I) ϵ∼N(0,I)
可知
ϵ ∗ μ ( x ( i ) ) + σ ( x ( i ) ) ∼ N ( μ ( x ( i ) ) , σ ( x ( i ) ) 2 ) \epsilon * \mu(x^{(i)}) + \sigma(x^{(i)}) \sim N(\mu(x^{(i)}), \sigma(x^{(i)})^2) ϵ∗μ(x(i))+σ(x(i))∼N(μ(x(i)),σ(x(i))2)
也就是说我们可以用这个 ϵ \epsilon ϵ对一个与神经网络无关的标准正态分布采样,然后通过如下公式在转换为z
ϵ ∗ μ ( x ( i ) ) + σ ( x ( i ) ) = z \epsilon * \mu(x^{(i)}) + \sigma(x^{(i)}) =z ϵ∗μ(x(i))+σ(x(i))=z
这就是重参数技巧的实质。
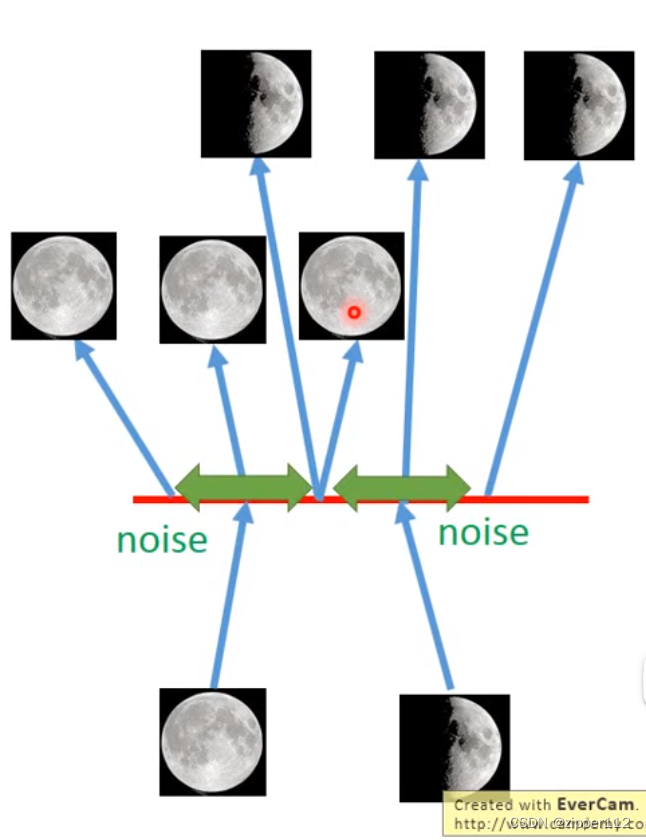
噪声与重建
VAE的KL损失及部分实际上是一个正则化部分,它让模型尽可能的保持一定的噪声。而VAE的重建损失(Reconstruct Loss)则是尽可能的去在有噪声的情况下回复原图。这实际上是一个对抗的过程。

从另一个角度来看,VAE其实也是在希望模型能够不在一个点上学到会付出这个输出,而是在一个范围之类(噪声的影响范围)之内恢复出一个数据
Discrete VAE
以后再写吧