萌新:
在接触一款硬件时我会:基础硬件结构,线程结构,内存布局,数据吞吐量,等方面进行学习
首先GPU的特点:
-
并行性能:GPU 是专门设计用于并行计算的硬件,通常具有大量的处理单元(CUDA核心或流处理器)。这使得 GPU 能够同时处理大量的数据和任务,适用于高度并行化的工作负载,如深度学习、科学计算和图形渲染。
-
浮点性能:GPU 在浮点运算性能上通常非常强大,可以执行大规模的浮点计算,适用于科学计算、仿真和数据分析等需要高精度计算的任务。
-
高内存带宽:GPU 具有高带宽的内存,可以快速读写大量数据。这对于需要大规模数据处理和存储的应用非常有帮助,如大规模数据分析和图像处理。
-
通用性:现代 GPU 具有通用计算能力,不仅可以用于图形渲染,还可以用于通用计算任务。CUDA 和 OpenCL 等编程模型使开发人员能够在 GPU 上执行各种应用程序,包括科学计算、深度学习、密码学等。
-
能效:GPU 在相对低功耗下提供了强大的计算能力,这使得它们在能效方面比传统的 CPU 更具优势。这对于大规模数据中心和移动设备非常重要。
-
大规模数据并行性:GPU 在处理大规模数据集时表现出色,能够加速数据密集型任务,如机器学习、数据挖掘和图像处理。
-
深度学习加速:GPU 对深度学习任务非常有利,因为深度神经网络的训练和推理通常涉及大量矩阵运算,而 GPU 具有出色的并行计算性能。
-
可编程性:现代 GPU 具有高度可编程性,允许开发人员使用编程语言(如CUDA、OpenCL、Vulkan等)编写自定义的计算核心和着色器,以适应各种应用需求。
尽管 GPU 具有这些优势,但并不是所有应用都适合在GPU 上执行。在选择硬件时,需要根据具体应用的需求和特性来考虑是否使用GPU,或者是否将CPU、FPGA等其他硬件与GPU结合使用。
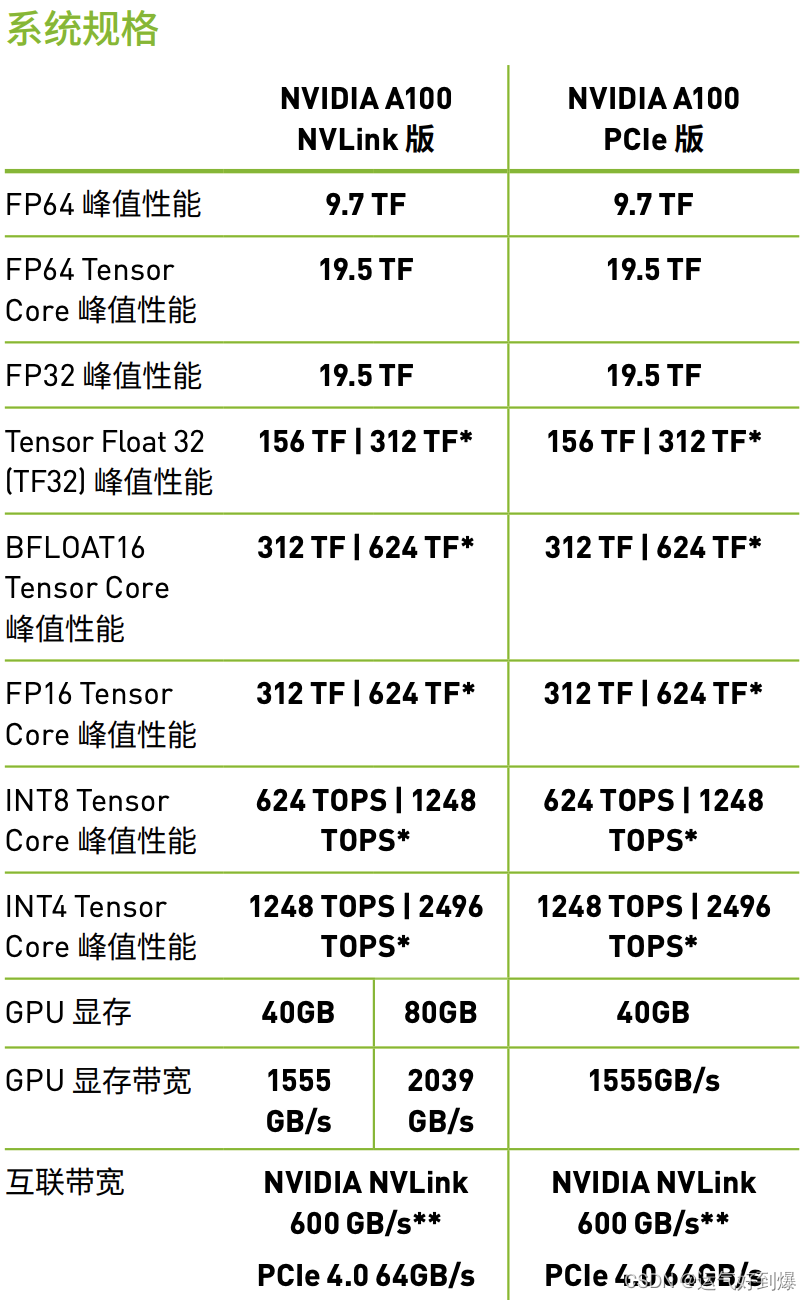
并行性能是通过众多的Cuda core 和Tensor core实现的, Tensor cores是从volta之后开始有的,个人理解是V100, Vxx等。今天刚学习了A100的硬件特性,这里做一下总结:
硬件图片:

这绿色的小点就是排列的SM,SM是GPU的流处理器用来执行调度的【block 调度线程】,A100中有128个SM
每个SM 有可以放大如下图:

每个SM一共有4个Tensor core, 64个 FP32 cuda core可以划分为4个部分,每个部分中有:
1. warp scheduler 这个是GPU的最小调度单元,32个线程为一个warp,warp内的线程执行相同指令
2. L0 指令缓存区
3. 寄存器文件(看官网的介绍中新增了异步拷贝:A100 GPU 包含了一个新的异步复制指令,该指令将数据直接从全局内存加载到 SM 共享内存中,从而消除了使用中间寄存器文件( RF )的需要。异步复制减少了寄存器文件带宽,更有效地使用内存带宽,并减少了功耗。顾名思义,异步复制可以在 SM 执行其他计算时在后台完成。)每个线程不能使用超过16384/(4个warp*32每个warp执行的线程数量)个寄存器,如果超过了就会使用本地内存:
4,LD/ST 是数据加载和存储队列, IO的地儿
一个SM中的线程共享L1 instruction/ L1 数据缓存/ 纹理缓存
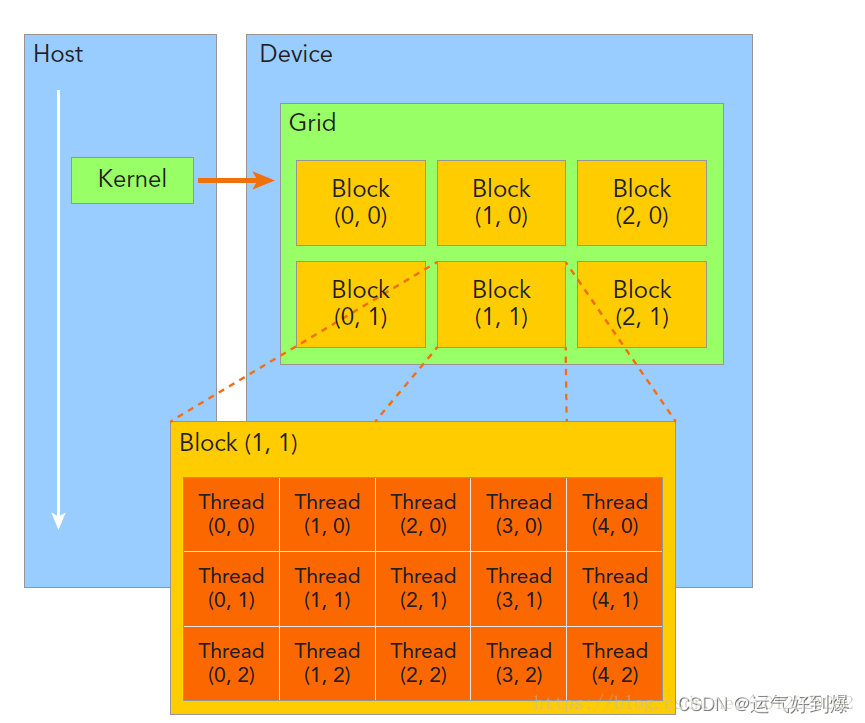
线程结构:原文链接:https://blog.csdn.net/u012229282/article/details/79972014
Grid:由一个kernel启动所产生的所有线程统称为一个线程网格(Grid)。
同一线程网格中的所有线程共享同全局内存空间。一个网格有多个线程块(Block)构成,一个线程块包含一组线程,同一线程块内的线程协同可以通过“同步”和“共享内存”的方式来实现。不同线程块内的线程不能协作。
在一个网格中,我们通过以下两个坐标变量来定位一个线程,
(1)blockIdx:线程块在线程网格中ID号
(2)threadIdx:线程在线程块内的ID号
这些坐标变量是kernel函数中需要预初始化的内置变量。
当执行有一个核函数时,CUDA Runtime 为每个线程分配坐标变量blockIdx和threadIdx。基于这些坐标,我们将数据分配到不同的GPU线程上,然后并行处理所有的数据。
坐标变量blocIdx和threadIdx都是基于unit3定义的CUDA内置的向量类型,分别包含3个无符号的整数结构,可以通过x,y,z三个元素来进行索引。
grid->block->thread
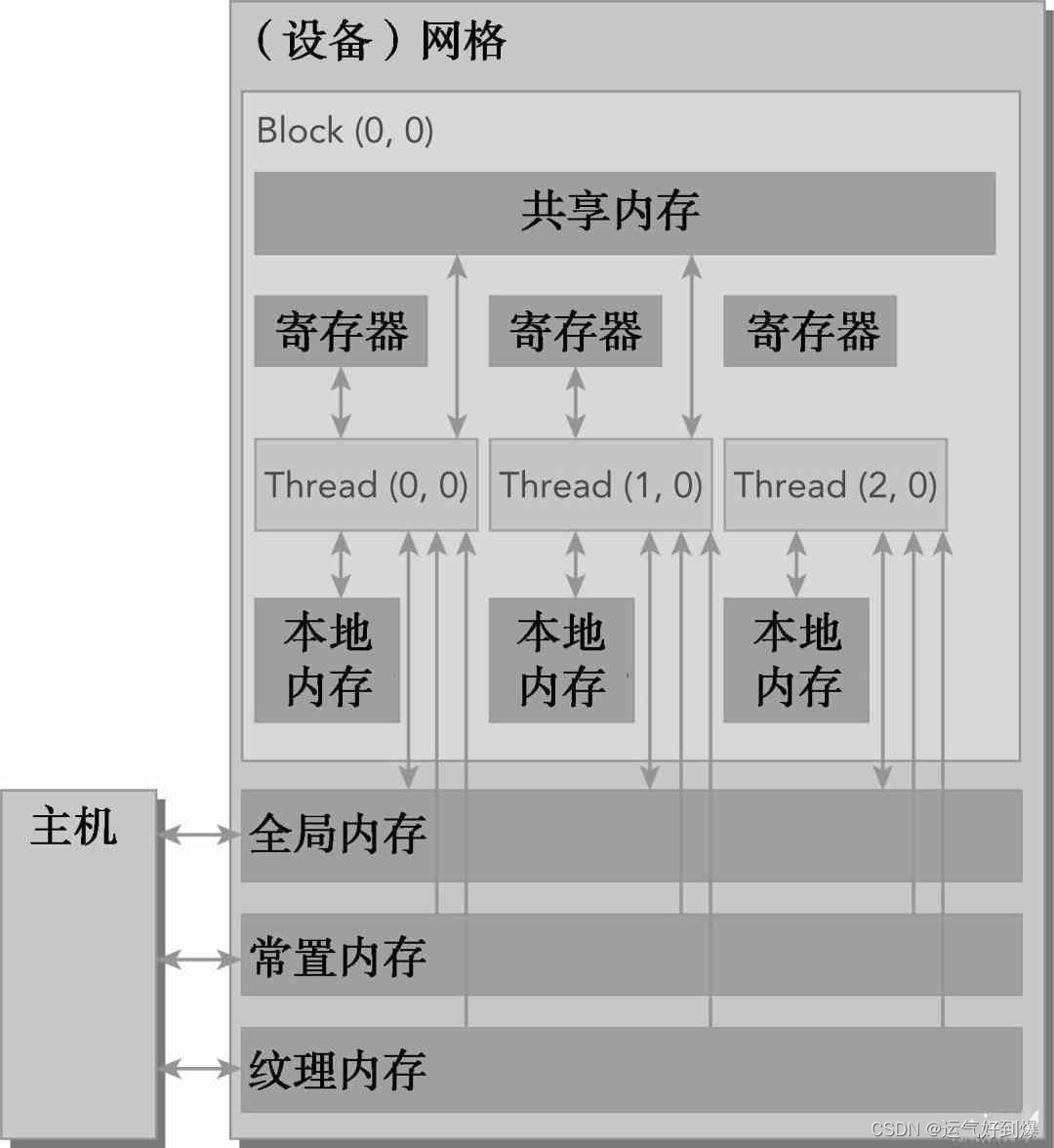
内存结构:
CUDA内存模型 引用:CUDA内存模型详解:锁页内存、统一寻址、CPU/GPU交互 - Hurray's InfoShare
对于程序员来说,一般有两种类型的存储器:
- 可编程的:你需要显式地控制哪些数据存放在可编程内存中
- 不可编程的:你不能决定数据的存放位置,程序将自动生成存放位置以获得良好的性能
在CPU内存层次结构中,一级缓存和二级缓存都是不可编程的存储器。另一方面,CUDA内存模型提出了多种可编程内存的类型:
- 寄存器
- 共享内存
- 本地内存:GPU内存(显存)的理解与基本使用 - 知乎
- 常量内存
- 纹理内存
- 全局内存CUDA内存模型详解:锁页内存、统一寻址、CPU/GPU交互 - Hurray's InfoShare
- 下图为这些内存空间的层次结构,每种都有不同的作用域、生命周期和缓存行为。一个Kernel核函数中的Thread线程都有自己私有的
本地内存。一个Block线程块有自己的共享内存,对同一线程块中所有Thread线程都可见,其内容持续Block的整个生命周期。所有Thread都可以访问全局内存。 - 所有Thread都能访问的只读内存空间有:
常量内存空间和纹理内存空间。全局内存、常量内存和纹理内存空间有不同的用途。纹理内存为各种数据布局提供了不同的寻址模式和滤波模式。对于一个应用程序来说,全局内存、常量内存和纹理内存中的内容具有相同的生命周期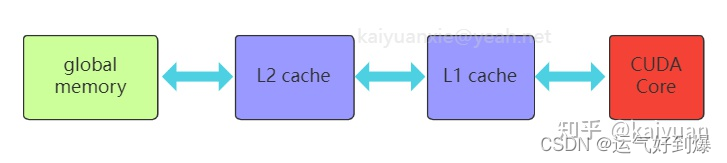
-
高内存带宽: