目录
BM(Boyer-Moore)
坏字符
好后缀
什么情况用哪个规则?
LeetCode之路——151. 反转字符串中的单词
分析:

字符串匹配中除了简单的BF(Brute Force)、RK(Rabin-Karp)算法,还有更高效、较难理解的
BM(Boyer-Moore)和KMP(Knuth Morris Pratt)算法。先了解下BM算法。
BM(Boyer-Moore)
在主串和模式串匹配的过程中,我们知道BF和RK算法都是去逐个字符比较,像下面这样:
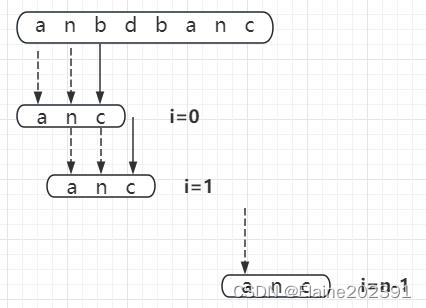
而现在,因为主串中的b不在模式串中,第二次我们就直接把模式串移到b后面,问题来了,下一次移动是往后移动2位和a对齐呢?还是继续移动一位?
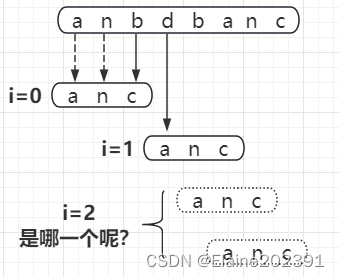
下面就要重点介绍BM算法的两个重要规则了:坏字符和好后缀。
坏字符
不同于常规思维,BM算法是根据模式串从后往前比较的。
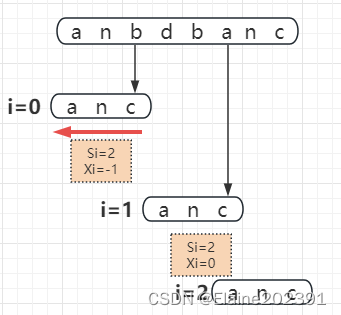
坏字符的定义:从模式串的末尾开始匹配,第一个没法匹配的字符(主串中的字符)叫做坏字符。
-
坏字符在模式串中对应的位置记住Si。比如b对应c的位置,就是Si=2。
-
坏字符在模式串中相同字符的位置记作Xi。不存在时记作-1。比如坏字符b对应的Xi=-1.
重点来了,模式串下次移动的长度就是Si-Xi。所以i=2的时候,模式串在i=1的基础上移动了2个字符的长度。(如果模式串中存在多个Xi的时候,选择最靠后的那个,因为这样不会让模式串滑动过多,导致本来可能匹配的情况被滑动略过。)
好后缀
和坏字符的思想有些类似。

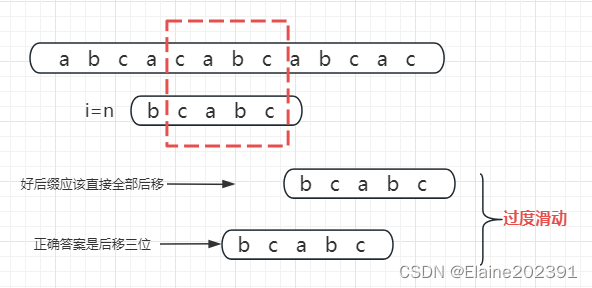
在i=1的时候,这种情况下就符合好后缀的原则了。从后往前匹配的过程中,出现坏字符前的字符串就是好后缀。好后缀的工作原理:
-
当模式串中坏字符前存在与好后缀相同的{u'},那我们就将模式串滑动到子串{u‘}与主串中{u}对齐的位置。
-
当模式串中坏字符前不存在与好后缀相同的{u'},那么就直接将模式串滑动到主串中{u}的后面。
好后缀的场景下也会有特殊情况的:
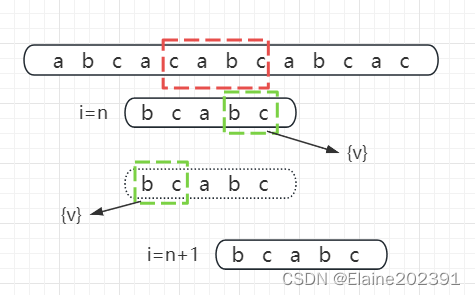
在这种情况的基础上,好后缀的原则做了优化和改善:
-
如果好后缀的后缀子串和模式串的前缀子串匹配,找一个最长的并且能跟模式串的前缀子串匹配的,假设是{v},然后将模式串滑动到如图所示的位置。
什么情况用哪个规则?
我们可以分别计算好后缀和坏字符往后滑动的位数,然后取两个数中最大的,作为模式串往后滑动的位数。这种处理方法还可以避免我们前面提到的,根据坏字符规则,计算得到的往后滑动的位数,有可能是负数的情况。
LeetCode之路——151. 反转字符串中的单词
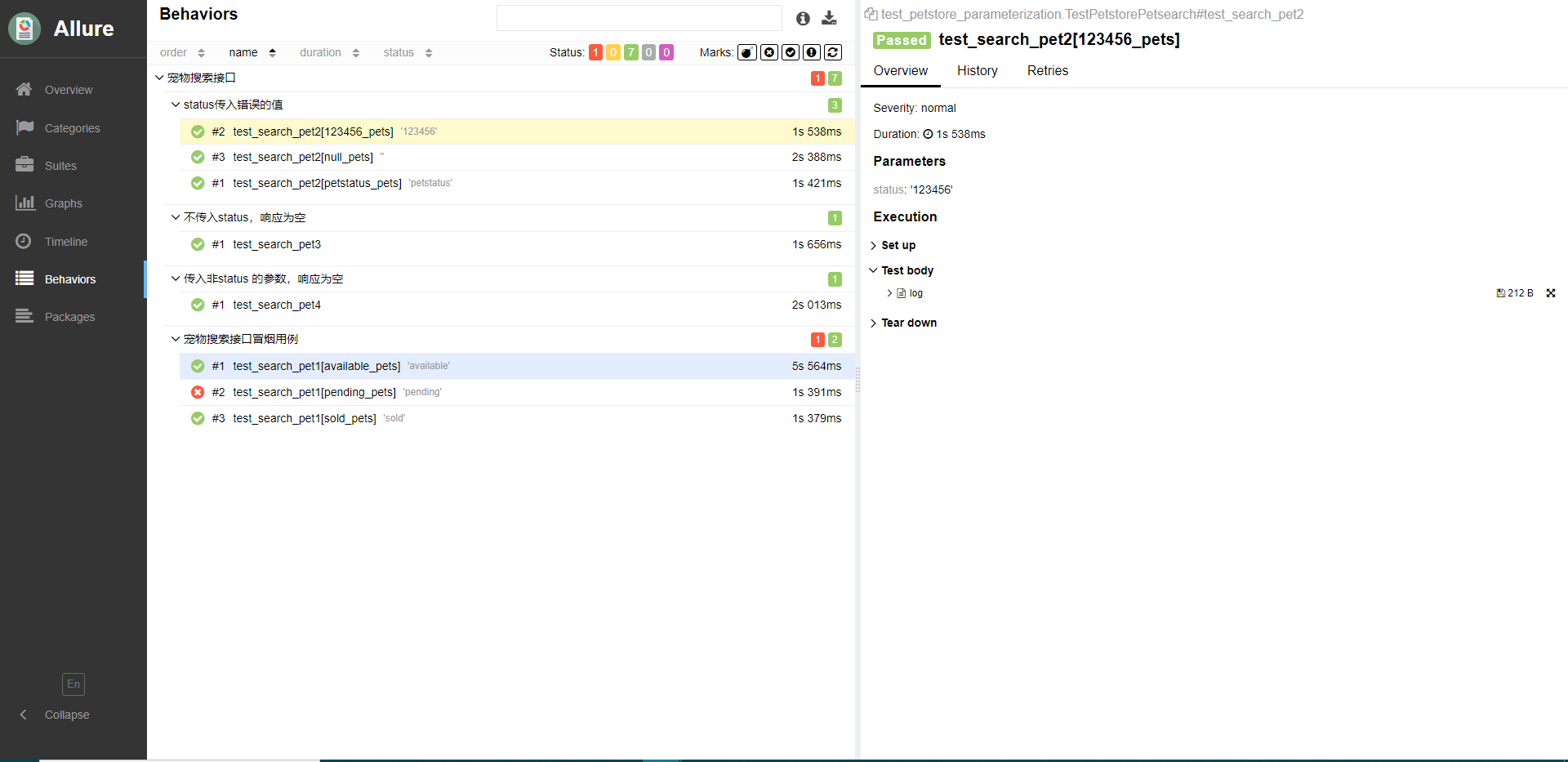
给你一个字符串 s ,请你反转字符串中 单词 的顺序。
单词 是由非空格字符组成的字符串。s 中使用至少一个空格将字符串中的 单词 分隔开。
返回 单词 顺序颠倒且 单词 之间用单个空格连接的结果字符串。
注意:输入字符串 s中可能会存在前导空格、尾随空格或者单词间的多个空格。返回的结果字符串中,单词间应当仅用单个空格分隔,且不包含任何额外的空格。
示例 1:
输入:s = "the sky is blue" 输出:"blue is sky the"
示例 2:
输入:s = " hello world " 输出:"world hello" 解释:反转后的字符串中不能存在前导空格和尾随空格。
示例 3:
输入:s = "a good example" 输出:"example good a" 解释:如果两个单词间有多余的空格,反转后的字符串需要将单词间的空格减少到仅有一个。
提示:
-
1 <= s.length <= 104 -
s包含英文大小写字母、数字和空格' ' -
s中 至少存在一个 单词
分析:
-
把首尾空格移除了。——>trim()
-
留下单词。——>split()
-
数组反转。——>reverse()
-
拼接字符串。——>join()
class Solution {public String reverseWords(String s) {s = s.trim(); // 除去开头和末尾的空白字符// 正则匹配连续的空白字符作为分隔符分割List<String> list = Arrays.asList(s.split("\\s+"));Collections.reverse(list);return String.join(" ", list);}
}
-
时间复杂度:O(n),其中 nnn 为输入字符串的长度。
-
空间复杂度:O(n),用来存储字符串分割之后的结果。