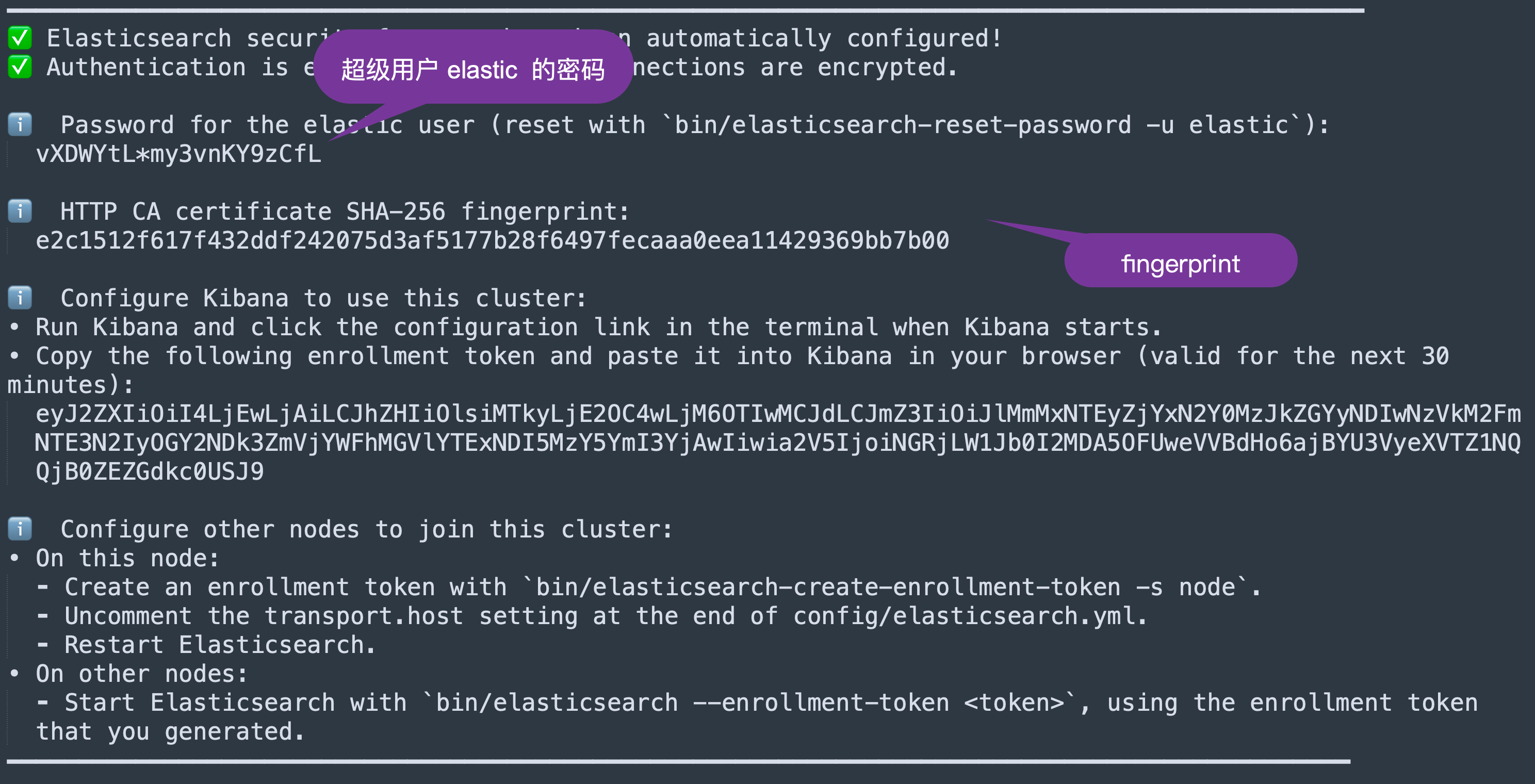
原创不易,注重版权。转载请注明原作者和原文链接
文章目录
- HBase特性
- Hadoop的限制
- 基本概念
- NameSpace
- Table
- RowKey
- Column
- TimeStamp
- Cell
- 存储结构
- HBase 数据访问形式
- 架构体系
- HBase组件
- HBase读写流程
- 读流程
- 写流程
- MemStore Flush
- 参数说明
- StoreFile Compaction
- 参数说明
- 触发过程
- Region Split
- 预分区
- HBase优化
- 查询优化
- 设置Scan缓存
- 显示指定列
- 禁用块缓存
- 写入优化
- 设置AutoFlush
- 参数优化
- Zookeeper 会话超时时间
- 设置 RPC 监听数量
- 手动控制 Major Compaction
- 优化 HStore 文件大小
- 优化 HBase 客户端缓存
- 指定 scan.next 扫描 HBase 所获取的行数
- SpringBoot中使用HBase
- Scan
- Phoenix
HBase是一个开源的非关系型分布式数据库,设计初衷是为了解决大量结构化数据存储与处理的需求。
它的核心理念、特性以及应用领域在当今的大数据环境中都发挥着至关重要的作用,这也是我们需要深入理解HBase的原因。在这篇文章中,我们将探讨HBase的基础概念,通过这些知识,读者将能够理解HBase的基本工作原理以及如何利用它处理数据问题。
HBase特性
以下是HBase的一些关键特性和概念:
- 分布式架构:HBase是一个分布式数据库,它可以在一个集群中运行在多个机器上。数据以水平分片的方式分布在不同的机器上,这样可以实现数据的高可用性和横向扩展性。
- 列存储: HBase是面向列的数据库,它将数据存储在表中的列族中。每个列族可以包含多个列,这样可以方便地存储和检索具有不同结构的数据。HBase的列存储特性使得可以高效地读取和写入大量数据。
- 强一致性:HBase提供强一致性的读写操作。当数据被写入或读取时,HBase会确保所有相关的副本都是最新的。这使得HBase非常适合需要强一致性的应用场景,如金融、电信等领域。
- 高可扩展性:HBase可以轻松地扩展到大规模的数据集和集群。通过添加更多的机器和分片数据,可以线性地扩展存储容量和吞吐量。
- 快速读写:HBase是为了高性能而设计的。它使用了内存和硬盘的组合来存储数据,可以实现快速的读写操作。此外,HBase还支持批量写入和异步写入,进一步提高了写入性能。
- 灵活的数据模型:HBase提供了灵活的数据模型,可以根据应用程序的需求设计表结构。它支持动态添加列,并且可以高效地执行范围查询和单行读写操作。
- 集成Hadoop生态系统:HBase与Hadoop生态系统紧密集成,可以与Hadoop分布式文件系统(HDFS)和Hadoop的计算框架(如MapReduce)无缝配合使用。这使得HBase能够处理大规模的数据存储和分析任务。
Hadoop的限制
尽管Hadoop是一个强大的分布式计算框架,但它也存在一些不足之处,与HBase相比,以下是Hadoop的一些限制:
- 实时性:Hadoop主要用于批处理任务,对于实时性要求较高的应用场景,如实时数据分析和流式处理,Hadoop的延迟可能会比较高。Hadoop的MapReduce模型通常不适合处理需要即时响应的数据处理任务。
- 存储效率:Hadoop在存储效率方面存在一些问题。为了提供容错性和可靠性,Hadoop将数据复制多次存储在不同的节点上,这会导致存储开销增加。相对于HBase的列存储模型,Hadoop的存储效率可能较低。
- 复杂性:Hadoop的配置和管理相对复杂,需要专业知识和经验。搭建和维护一个Hadoop集群需要处理许多参数和组件,对于初学者来说可能存在一定的学习曲线。
- 扩展性限制:虽然Hadoop具有良好的可扩展性,可以通过添加更多的节点来扩展集群的存储和计算能力,但在某些情况下,随着集群规模的增加,管理和调度节点可能变得更加困难。
- 处理复杂查询的限制:Hadoop的主要计算模型是MapReduce,它适合处理简单的计算任务,但对于复杂的查询和数据分析,如复杂聚合、连接和实时查询等,Hadoop的性能可能不如专门设计的分析数据库。
基本概念
NameSpace
命名空间,类似于关系型数据库的Database概念,每个命名空间下有多个表。
HBase自带两个命名空间,分别是hbase和default,hbase 中存放的是HBase内置的表,default表是用户默认使用的命名空间,这两个命名空间默认是不展示的。
Table
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。因为数据存储是稀疏的,空(null)列不占用存储空间,所以往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
RowKey
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
Column
HBase中的每个列都由**Colunn Family (列族)和Column Qualifier (列限定符)**进行限定,例如info: name, info: age。
建表时,只需指明列族,而列限定符无需预先定义。
TimeStamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间。
Cell
由 {rowkey, column Family :column Qualifier, timestamp} 唯一确定的单元,Cell 中的数据全部是字节码形式存贮。
一条数据有多个版本,每个版本都是一个Cell。
存储结构
HBase存储结构如下:
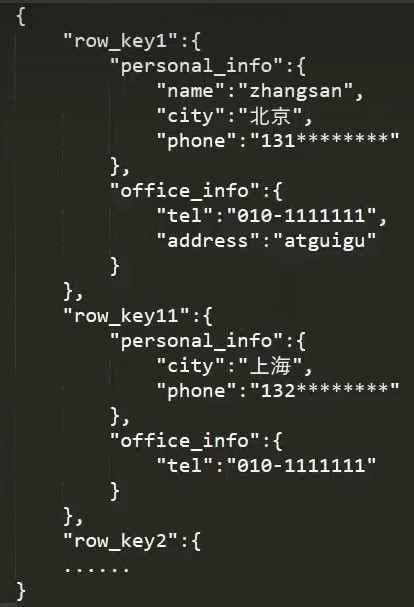
上面的数据会存储为下面这样:
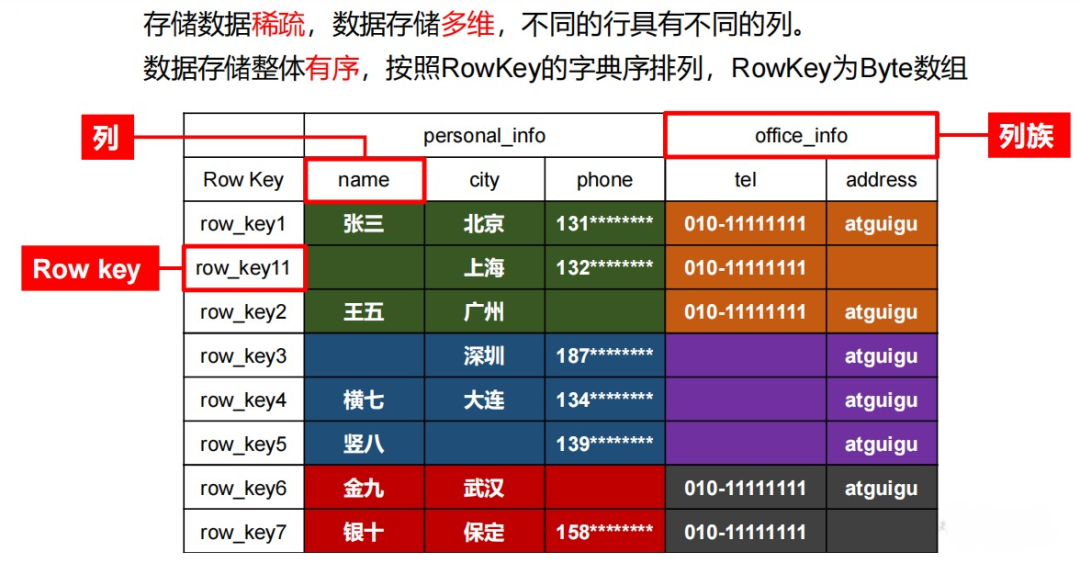

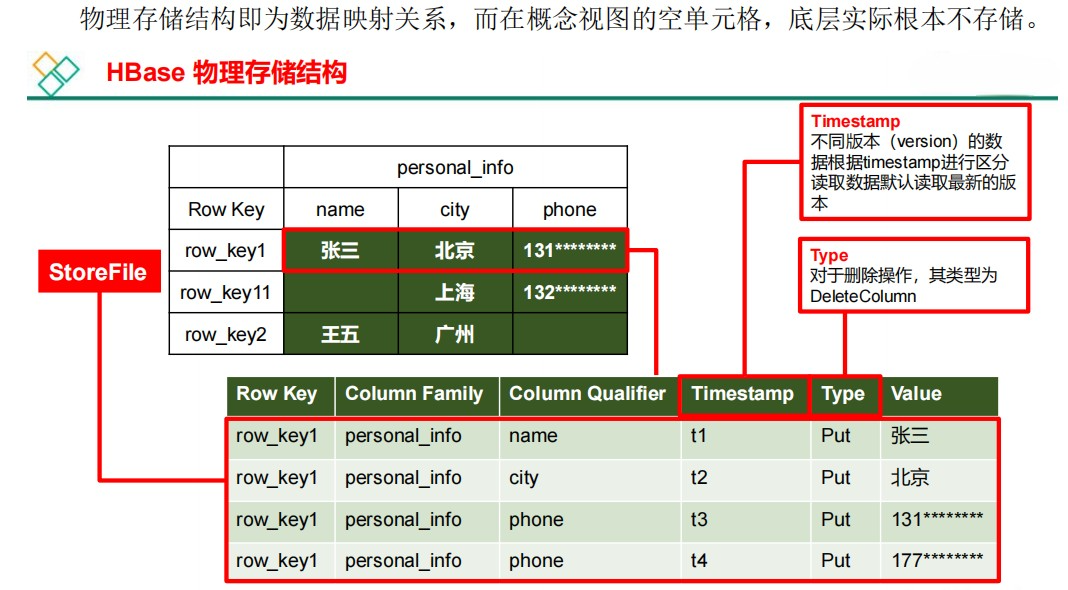
行切分为Region,列切分为Store,Region可以存放在其他机器上。
HBase是基于HDFS的,而HDFS是不能够修改数据的,所以HBase也是不能修改数据的。HBase使用时间戳实现修改功能。取数据的时候取最新时间戳的数据,取出来的就是最新的数据。
HBase 数据访问形式
HBase数据访问可以通过以下几种形式进行:
- 单行读写(Get和Put):使用HBase提供的API,可以通过指定行键(Row Key)来读取和写入单行数据。Get操作可以根据行键从表中获取特定行的数据,而Put操作可以将数据写入表的指定行。
- 批量读写(Scan和Batch Put):HBase支持批量读写操作,可以一次性读取或写入多行数据。Scan操作可以按照一定的条件扫描表中的多行数据,而Batch Put操作可以一次性写入多行数据。
- 全表扫描(Scan):通过Scan操作,可以遍历整个表的数据,按照指定的条件进行过滤和筛选。可以设置起始行键和结束行键,还可以使用过滤器(Filter)进行更精确的数据查询。
- 列族范围扫描(Scan):HBase中的数据以列族(Column Family)为单位进行存储,可以通过Scan操作对指定列族的数据进行范围扫描。这种方式可以提高数据查询的效率,只获取所需列族的数据,而不必读取整个表的数据。
- 过滤器(Filter):HBase支持多种过滤器来进行数据的精确查询和过滤。可以使用行键过滤器(Row Filter)按照行键的条件进行数据过滤,还可以使用列族过滤器(Family Filter)、列限定符过滤器(Qualifier Filter)和值过滤器(Value Filter)等进行更细粒度的数据过滤。
- 原子性操作(Check-and-Put和Check-and-Delete):HBase支持原子性操作,例如Check-and-Put和Check-and-Delete。这些操作允许在写入数据之前进行检查,只有在满足指定条件的情况下才执行写入操作。
以上形式提供了不同的数据访问方式,可以根据具体的需求和查询条件选择适合的方式来访问和操作HBase中的数据。
架构体系
HBase的架构体系是基于分布式存储和处理的设计。它包含了以下几个重要的组成部分:
- HMaster:HMaster是HBase集群的主节点,负责管理整个集群的元数据和协调各个RegionServer的工作。它维护了表的结构信息、分片规则、RegionServer的负载均衡等,并协调分布式操作,如Region的分裂和合并。
- RegionServer:RegionServer是HBase集群中的工作节点,负责存储和处理数据。每个RegionServer管理多个Region,每个Region负责存储表中的一部分数据。RegionServer处理客户端的读写请求,负责数据的存储、读取和写入操作。
- ZooKeeper:ZooKeeper是一个分布式协调服务,被HBase用于管理集群的元数据和协调分布式操作。HBase使用ZooKeeper来进行主节点的选举、故障检测、集群配置的同步等任务。
- HDFS(Hadoop Distributed File System):HBase使用HDFS作为底层的分布式文件系统,用于存储数据。HDFS将数据分割成块并分布在不同的节点上,提供高可靠性和可扩展性的存储。
- HBase客户端:HBase客户端是与HBase交互的应用程序或工具,用于发送读写请求和接收查询结果。客户端可以通过HBase的Java API或者命令行工具(如HBase shell)来访问和操作HBase表。
- 表和列族:HBase数据模型是基于表的,表由一个或多个列族(Column Family)组成。每个列族可以包含多个列(Column),列存储着实际的数据。表被分割成多个Region存储在不同的RegionServer上,每个Region负责存储一部分行数据。
这些组成部分共同构成了HBase的架构体系,实现了分布式存储和处理大规模数据集的能力。
HMaster负责管理元数据和协调工作,RegionServer存储和处理数据,ZooKeeper提供分布式协调服务,HDFS提供底层的分布式文件存储,而HBase客户端用于与HBase进行交互。表和列族的概念提供了数据的组织和存储方式。
HBase组件
- MemStore:每个RegionServer都有一个MemStore,它是位于内存中的临时数据存储区域。当客户端写入数据时,数据首先被写入到MemStore中,以提供快速的写入性能。
- WAL(Write-Ahead-Log):WAL是HBase的日志文件,用于记录所有的写操作。当数据被写入到MemStore时,相应的写操作也会被写入WAL中,以保证数据的持久性和故障恢复能力。
- StoreFile:当MemStore中的数据达到一定大小阈值后,会被刷新到磁盘上的StoreFile中。StoreFile是HBase中实际持久化存储数据的文件形式,它包含了已经写入的数据和相应的索引。
- HFile:HFile是StoreFile的底层存储格式,采用了块索引和时间范围索引的方式,提供了高效的数据查找和扫描能力。HFile使用块(Block)来组织数据,并采用压缩和编码技术来减小存储空间。
MemStore提供了临时的内存存储,StoreFile提供了持久化的磁盘存储,WAL用于保证数据的持久性。这种架构设计使得HBase能够提供高可用性、高性能和可扩展性的分布式存储和处理能力。
HBase读写流程
读流程
- 客户端发送读取请求:客户端向HBase集群发送读取请求,包括所需的表名、行键(Row Key)以及其他可选的参数(如列族、列限定符等)。
- 定位RegionServer和Region:HBase的客户端会与ZooKeeper进行通信,获取到存储有所需数据的Region所在的RegionServer的信息。
- RegionServer处理请求:客户端发送的读取请求到达对应的RegionServer,RegionServer会根据请求的行键定位到包含所需数据的Region。
- 数据读取:RegionServer首先会从MemStore中查找数据,如果数据在MemStore中找到,则直接返回给客户端。如果数据不在MemStore中,RegionServer会在磁盘上的StoreFile中进行查找,根据索引定位到所需的数据块,并将数据块读取到内存中进行处理。
- 数据返回给客户端:RegionServer将读取到的数据返回给客户端,客户端可以根据需要对数据进行进一步的处理和分析。
写流程
- 客户端发送写入请求:客户端向HBase集群发送写入请求,包括表名、行键、列族、列限定符和对应的值等信息。
- 定位RegionServer和Region:客户端与ZooKeeper通信,获取存储目标数据的Region所在的RegionServer的信息。
- RegionServer处理请求:客户端发送的写入请求到达对应的RegionServer,RegionServer根据行键定位到目标Region。
- 写入到MemStore:RegionServer将写入请求中的数据写入到目标Region对应的内存中的MemStore。写入到MemStore是一个追加操作,将数据追加到内存中的MemStore中,并不直接写入磁盘。
- WAL日志记录:同时,RegionServer将写入请求中的操作写入WAL(Write-Ahead-Log)日志文件,确保数据的持久性和故障恢复能力。
- MemStore刷新到磁盘:当MemStore中的数据达到一定的大小阈值时,RegionServer会将MemStore中的数据刷新到磁盘上的StoreFile中。刷新过程将内存中的数据写入到磁盘上的StoreFile,并生成相应的索引。
- 数据返回给客户端:写入完成后,RegionServer向客户端发送写入成功的响应,表示数据已成功写入。
MemStore Flush
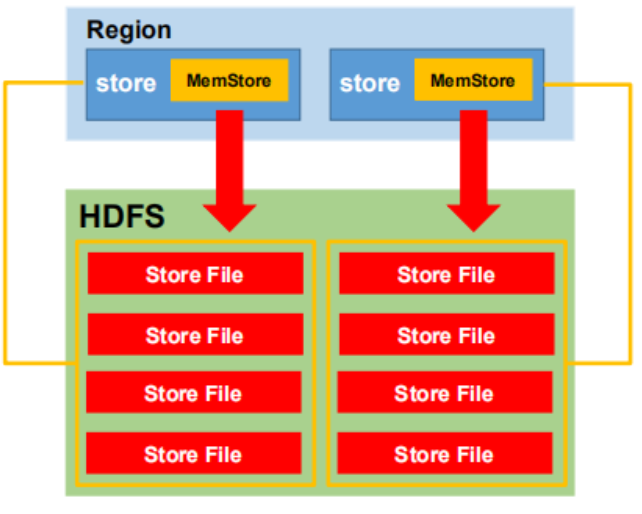
在HBase中,MemStore Flush是将内存中的数据刷新到磁盘上的StoreFile的过程。当MemStore中的数据达到一定大小阈值时,或者达到了一定的时间限制,HBase会触发MemStore Flush操作,以将数据持久化到磁盘,确保数据的持久性和可靠性。
下面是MemStore Flush的基本过程:
- MemStore Flush触发:当MemStore中的数据量达到一定的阈值(由配置参数控制)或者达到了一定的时间限制时,HBase会触发MemStore Flush操作。这个阈值和时间限制可以根据需求进行配置,以平衡写入性能和数据持久性的要求。
- 写入内存快照:在触发Flush操作时,HBase会先将MemStore中的数据做一个内存快照(Snapshot),以保证在Flush期间继续接收新的写入请求。
- 刷写到磁盘:内存快照完成后,HBase会将内存中的数据按照列族的维度划分为多个KeyValue,然后将这些KeyValue写入磁盘上的StoreFile。StoreFile采用HFile格式,用于持久化存储数据。
- 更新Region元数据:完成刷写到磁盘后,HBase会更新Region的元数据,包括最新的StoreFile列表和相应的时间戳等信息。
- MemStore清空:一旦数据刷写到磁盘上的StoreFile,HBase会清空相应的MemStore,以释放内存空间用于接收新的写入请求。
通过MemStore Flush操作,HBase可以将内存中的数据持久化到磁盘,以确保数据的持久性和可靠性。Flush操作的频率和成本可以通过配置参数进行调整,以适应不同的应用场景和性能需求。频繁的Flush操作可能会影响写入性能,而较长的Flush间隔可能会增加数据丢失的风险。因此,根据实际情况,需要合理设置Flush操作的参数,以平衡数据的持久性和写入性能的要求。
参数说明
MemStore Flush在HBase中由以下几个参数进行控制,它们的含义如下:
- hbase.hregion.memstore.flush.size:该参数指定了MemStore的大小阈值。当MemStore中的数据量达到或超过这个阈值时,将触发MemStore Flush操作。该参数的默认值为 128MB。这个参数在HBase 0.98版本及更高版本中生效。在旧版本中,类似的参数名为 hbase.hregion.memstore.flush.size.upper,但其含义和作用相同。
- hbase.hregion.memstore.block.multiplier:该参数是用来设置MemStore大小阈值的倍数。当MemStore的大小超过 hbase.hregion.memstore.flush.size 乘以 hbase.hregion.memstore.block.multiplier 时,将触发MemStore Flush操作。默认值为2。这个参数在HBase 0.98版本及更高版本中生效。
- hbase.hregion.memstore.flush.size.lower.limit:该参数定义了MemStore大小的下限限制。当MemStore中的数据量小于此下限时,不会触发MemStore Flush操作。该参数的默认值为0。在HBase 2.0版本及更高版本中生效。
- hbase.hregion.memstore.flush.size.upper.limit:该参数定义了MemStore大小的上限限制。当MemStore中的数据量超过此上限时,将强制触发MemStore Flush操作。该参数的默认值为Long.MAX_VALUE。在HBase 2.0版本及更高版本中生效。
上述的1和2,满足任一条件都会触发MemStore Flush操作。
这些参数需要根据具体的应用场景和性能要求进行合理的设置。较小的Flush阈值可以提高数据的持久性,但可能会增加Flush的频率和写入的开销;较大的Flush阈值可以减少Flush的频率和开销,但可能会增加数据丢失的风险。
因此,需要根据应用的读写特征和数据的重要性,选择合适的参数值。
StoreFile Compaction
StoreFile Compaction(文件合并)是 HBase 中的一个重要操作,它用于合并和优化存储在磁盘上的数据文件(StoreFile)。StoreFile Compaction 可以帮助减少磁盘空间占用、提高读取性能,并且在某些情况下可以提高写入性能。
StoreFile Compaction 的基本过程如下:
- Compact Selection(选择合并):在进行 Compaction 之前,HBase 首先进行选择性合并。它会根据一定的策略,如大小、时间戳等,选择一组需要合并的 StoreFile。这样可以限制合并的数据量,避免一次合并过多数据。
- Minor Compaction(小规模合并):Minor Compaction 主要合并较少数量的 StoreFile。它通过创建一个新的 StoreFile,并从多个旧的 StoreFile 中选择合并的数据,将其合并到新的文件中。这个过程中,旧的 StoreFile 不会被删除,新的 StoreFile 会被创建并写入新的数据。
- Major Compaction(大规模合并):Major Compaction 是一种更为综合和耗时的合并操作。它会合并一个或多个 HBase 表的所有 StoreFile。Major Compaction 将会创建一个新的 StoreFile,并将所有旧的 StoreFile 中的数据合并到新的文件中。与 Minor Compaction 不同,Major Compaction 还会删除旧的 StoreFile,从而释放磁盘空间。
- Compaction Policy(合并策略):HBase 提供了不同的合并策略,可以根据数据特点和应用需求进行选择。常见的合并策略包括 SizeTieredCompactionPolicy(按大小合并)和 DateTieredCompactionPolicy(按时间戳合并)等。
通过 StoreFile Compaction,HBase 可以减少磁盘上的存储空间占用,提高读取性能,同时合并操作还可以优化数据布局,加速数据的访问。合适的合并策略的选择可以根据数据的访问模式和应用需求,以达到最佳的性能和存储效率。
参数说明
StoreFile Compaction 过程中涉及到的一些相关参数及其含义如下:
- hbase.hstore.compaction.min:指定了进行 Minor Compaction 的最小文件数。当 StoreFile 的数量达到或超过该值时,才会触发 Minor Compaction。默认值为 3。
- hbase.hstore.compaction.max:指定了进行 Major Compaction 的最大文件数。当 StoreFile 的数量超过该值时,将触发 Major Compaction。默认值为 10。
- hbase.hstore.compaction.ratio:指定了触发 Major Compaction 的比率。当一个 Region 中的 StoreFile 的总大小超过其最大文件大小的比率时,将触发 Major Compaction。默认值为 1.2。
- hbase.hstore.compaction.min.size:指定了进行 Compaction 的最小文件大小。当一个 StoreFile 的大小小于该值时,将不会参与 Compaction。默认值为 1 KB。
- hbase.hstore.compaction.max.size:指定了进行 Compaction 的最大文件大小。当一个 StoreFile 的大小超过该值时,将不会参与 Compaction。默认值为 Long.MAX_VALUE,即无限制。
- hbase.hstore.compaction.enabled:指定了是否启用 Compaction。如果设置为 false,则不会触发任何 Compaction 操作。默认值为 true。
- hbase.hstore.compaction.checker.interval.multiplier:指定了进行 Compaction 检查的时间间隔。实际检查的时间间隔为 hbase.hstore.compaction.checker.interval.multiplier 乘以 StoreFile 的平均大小。默认值为 1.0。
这些参数可以在 HBase 的配置文件(hbase-site.xml)中进行设置。通过调整这些参数的值,可以根据数据量、存储需求和性能要求来优化 Compaction 操作的触发条件和行为。
触发过程
以下是判断是否触发 Compaction 的过程:
-
判断是否满足进行 Minor Compaction 的条件:
- 检查 StoreFile 的数量是否达到或超过 hbase.hstore.compaction.min。如果是,则满足触发 Minor Compaction 的条件。
-
判断是否满足进行 Major Compaction 的条件:
- 检查 StoreFile 的数量是否超过 hbase.hstore.compaction.max。如果是,则满足触发 Major Compaction 的条件。
或者
- 计算 StoreFile 的总大小与最大文件大小之间的比率。如果超过 hbase.hstore.compaction.ratio,即 StoreFile 的总大小超过最大文件大小的比率,那么满足触发 Major Compaction 的条件。
-
对于即将进行 Compaction 的 StoreFile:
- 检查 StoreFile 的大小是否在 hbase.hstore.compaction.min.size 和 hbase.hstore.compaction.max.size 之间。如果不在这个范围内,则该文件将不会参与 Compaction。
-
检查是否启用 Compaction:
- 检查 hbase.hstore.compaction.enabled 的值是否为 true。如果为 false,则不会触发任何 Compaction 操作。
-
判断触发 Compaction 的时间间隔:
- 根据 hbase.hstore.compaction.checker.interval.multiplier 乘以 StoreFile 的平均大小,得出实际的检查时间间隔。
根据以上判断过程,HBase 在每个 RegionServer 上的每个 Store(列族)会根据配置参数进行定期的 Compaction 检查。一旦满足触发 Compaction 的条件,相应的 Minor Compaction 或 Major Compaction 将被触发,合并和优化存储的数据文件。这样可以提高读取性能、节省磁盘空间,并且在某些情况下可以提高写入性能。
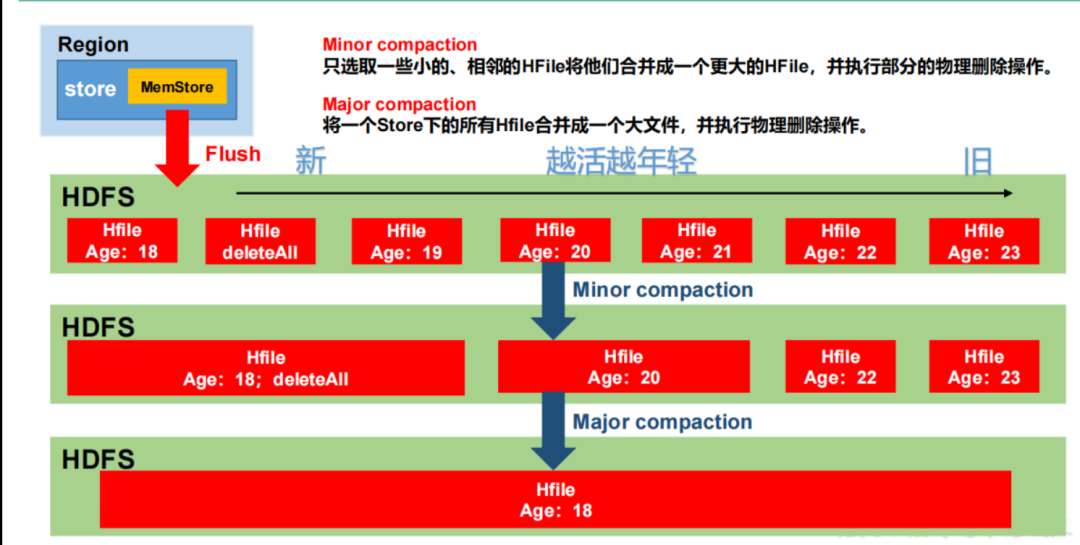
Region Split
Region Split(区域分割)是 HBase 中的一个重要操作,它用于在数据增长过程中,将一个较大的 HBase 表的 Region(区域)划分成更小的子区域,以提高读写性能和负载均衡。
当一个 Region 的大小达到了预先配置的阈值时,HBase 将触发 Region Split 操作。Region Split 的基本过程如下:
- Split Policy(分割策略):HBase 提供了多种分割策略,用于决定何时触发 Region Split。常见的分割策略包括按大小分割(Size-based Split)和按行数分割(Row-count-based Split)。这些策略可以根据数据特点和应用需求进行选择。
- Split Selection(选择分割点):在触发分割之前,HBase 首先选择一个适当的分割点。分割点是指一个 RowKey,它将成为分割后的两个子区域的边界。选择分割点的策略可以是根据大小、行数或其他自定义逻辑进行选择。
- Region Split(区域分割):一旦选择了分割点,HBase 将通过创建两个新的子区域来执行分割操作。原始的 Region 将被拆分成两个子区域,每个子区域负责存储分割点两侧的数据。同时,HBase 会为新的子区域生成新的 Region ID,并更新元数据信息。
常见的区域分割方式包括:
- 均匀分割(Even Split):将一个 Region 均匀地划分为两个子区域。分割点根据数据大小或行数进行选择,以保持两个子区域的大小相近。
- 预分区(Pre-splitting):在创建表时,可以提前定义多个分割点,将表划分为多个初始的子区域。这样可以在表创建之初就实现数据的均衡分布,避免后续的动态分割。
- 自定义分割(Custom Split):根据具体的业务需求和数据特点,可以通过自定义逻辑来选择分割点,实现更灵活的分割方式。
通过合理地使用区域分割,可以充分利用集群资源,提高读写性能和负载均衡能力。不同的分割策略和分割方式可以根据数据规模、访问模式和应用需求进行选择,以满足不同场景下的需求。
预分区
在 HBase 中进行预分区可以通过 HBase Shell 或 HBase API 进行操作。以下是使用 HBase Shell 进行预分区的示例:
-
打开 HBase Shell:
$ hbase shell -
创建表并指定分区:
hbase(main):001:0> create 'my_table', 'cf', {SPLITS => ['a', 'b', 'c']}上述命令创建了一个名为
my_table的表,并指定了三个分区点:‘a’、‘b’ 和 ‘c’。这将创建四个初始的子区域。 -
查看表的分区情况:
hbase(main):002:0> describe 'my_table'这将显示表的详细信息,包括分区信息。
通过上述步骤,你可以在创建表时预先定义分区点,从而实现预分区。每个分区点将成为一个子区域的边界,确保数据在表创建时就能分布在多个子区域中,从而实现负载均衡和性能优化。
请注意,上述示例是使用 HBase Shell 进行预分区的简单示例。如果需要在编程中进行预分区,可以使用 HBase API,例如 Java API,通过在创建表时设置 SPLITS 参数来指定分区点。
以下是使用 HBase Java API 进行预分区的示例代码:
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.util.Bytes;import java.io.IOException;public class PreSplitExample {public static void main(String[] args) throws IOException {// 创建 HBase 配置org.apache.hadoop.conf.Configuration config = HBaseConfiguration.create();// 创建 HBase 连接try (Connection connection = ConnectionFactory.createConnection(config)) {// 创建 HBase 管理器try (Admin admin = connection.getAdmin()) {// 定义表名TableName tableName = TableName.valueOf("my_table");// 定义分区点byte[][] splitKeys = {Bytes.toBytes("a"),Bytes.toBytes("b"),Bytes.toBytes("c")};// 创建表并指定分区admin.createTable(TableDescriptorBuilder.newBuilder(tableName).addColumnFamily(ColumnFamilyDescriptorBuilder.of("cf")).setSplitKeys(splitKeys).build());}}}
}
上述代码通过 HBase Java API 创建了一个名为 my_table 的表,并指定了三个分区点:‘a’、‘b’ 和 ‘c’。这将创建四个初始的子区域。
请注意,在使用 Java API 进行预分区时,需要先建立与 HBase 的连接,并通过 HBase 管理器(Admin)执行表的创建操作,并设置 setSplitKeys(splitKeys) 方法来指定分区点。
通过上述示例代码,你可以在编程中使用 HBase Java API 实现预分区功能。
HBase优化
查询优化
设置Scan缓存
在HBase中,可以通过设置Scan对象的setCaching()方法来调整Scan缓存的大小。Scan缓存用于指定每次扫描操作从RegionServer返回给客户端的行数。通过调整缓存大小,可以在一定程度上控制数据的读取性能和网络传输的开销。
以下是设置Scan缓存的示例代码:
Scan scan = new Scan();
scan.setCaching(500); // 设置缓存大小为500行ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {// 处理扫描结果
}
scanner.close();
在上述示例中,setCaching()方法将缓存大小设置为500行。可以根据实际需求调整这个值,需要根据数据大小、网络带宽和性能要求进行权衡。较大的缓存大小可以减少客户端与RegionServer之间的通信次数,提高读取性能,但同时也会增加内存消耗。较小的缓存大小可以减少内存消耗,但可能会增加通信次数和网络传输开销。
需要注意的是,setCaching()方法设置的是每次扫描的缓存大小,并不是全局的设置。如果需要对整个表的扫描操作生效,需要在每次扫描时都设置缓存大小。
此外,还可以通过调整HBase的配置参数来全局设置缓存大小。在hbase-site.xml配置文件中添加以下参数可以设置默认的缓存大小:
<property><name>hbase.client.scanner.caching</name><value>500</value> <!-- 设置默认的缓存大小为500行 -->
</property>
以上是通过代码和配置文件来设置Scan缓存大小的方法,根据具体的应用场景和需求,可以选择适当的方式进行设置。
显示指定列
当使用Scan或者GET获取大量的行时,最好指定所需要的列,因为服务端通过网络传输到客户端,数据量太大可能是瓶颈。如果能有效过滤部分数据,能很大程度的减少网络I/O的花费。
在HBase中,可以使用Scan或Get操作来显示指定的列。下面分别介绍两种方式的用法:
- 使用
Scan操作显示指定列:
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("col1")); // 指定列族(cf)和列(col1)ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {byte[] value = result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("col1"));// 处理列(col1)的值
}
scanner.close();
在上述示例中,使用scan.addColumn()方法来指定要显示的列族和列。在for循环中,通过result.getValue()方法获取指定列的值。
- 使用
Get操作显示指定列:
Get get = new Get(Bytes.toBytes("row1")); // 指定行键(row1)
get.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("col1")); // 指定列族(cf)和列(col1)Result result = table.get(get);
byte[] value = result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("col1"));
// 处理列(col1)的值
在上述示例中,使用get.addColumn()方法来指定要显示的列族和列。通过table.get()方法获取行数据,并通过result.getValue()方法获取指定列的值。
无论是使用Scan还是Get,都可以通过addColumn()方法来指定要显示的列族和列。可以根据具体的需求,多次调用addColumn()方法来显示多个列。
需要注意的是,HBase中的列是以字节数组(byte[])形式表示的,因此在使用addColumn()和getValue()方法时,需要将列族和列名转换为字节数组。
禁用块缓存
如果批量进行全表扫描,默认是有缓存的,如果此时有缓存,会降低扫描的效率。
在HBase中,可以通过设置Scan对象的setCacheBlocks()方法来禁用块缓存。块缓存是HBase中的一种缓存机制,用于加快数据的读取操作。然而,在某些情况下,禁用块缓存可能是有益的,例如对于某些热点数据或者需要立即获取最新数据的场景。
以下是禁用Scan块缓存的示例代码:
Scan scan = new Scan();
scan.setCacheBlocks(false); // 禁用块缓存ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {// 处理扫描结果
}
scanner.close();
在上述示例中,setCacheBlocks(false)方法将禁用Scan操作的块缓存。
需要注意的是,禁用块缓存可能会增加对HBase存储的实际磁盘读取次数,并且在一些场景下可能导致性能下降。因此,在禁用块缓存之前,建议仔细评估应用需求和场景,确保禁用块缓存的决策是合理的。
对于经常读到的数据,建议使用默认值,开启块缓存。
写入优化
设置AutoFlush
Htable有一个属性是AutoFlush,该属性用于支持客户端的批量更新,默认是true,当客户端每收到一条数据,立刻发送到服务端,如果设置为false,当客户端提交put请求时候,先将该请求在客户端缓存,到达阈值的时候或者执行hbase.flushcommits(),才向RegionServer提交请求。
在HBase中,可以通过设置Table对象的setAutoFlush()方法来控制自动刷新(AutoFlush)行为。AutoFlush决定了在何时将数据从客户端发送到RegionServer并写入到存储中。
以下是设置AutoFlush的示例代码:
// 创建HBase配置对象
Configuration conf = HBaseConfiguration.create();// 创建HBase连接
Connection connection = ConnectionFactory.createConnection(conf);// 获取表对象
TableName tableName = TableName.valueOf("your_table_name");
Table table = connection.getTable(tableName);// 设置AutoFlush
table.setAutoFlush(false); // 关闭AutoFlush// 执行写入操作
Put put = new Put(Bytes.toBytes("row1"));
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("col1"), Bytes.toBytes("value1"));
table.put(put);// 手动刷新数据
table.flushCommits(); // 手动刷新数据到RegionServer// 关闭表和连接
table.close();
connection.close();
在上述示例中,table.setAutoFlush(false)方法将关闭AutoFlush。这意味着在执行写操作时,数据不会立即被刷新到RegionServer和存储中,而是先缓存在客户端的内存中。只有当调用table.flushCommits()方法时,数据才会被手动刷新到RegionServer。
需要注意的是,关闭AutoFlush可以提高写入性能,尤其是在批量写入或者频繁写入的场景中。但是,关闭AutoFlush也会增加数据在客户端内存中的暂存时间,并增加了数据丢失的风险。因此,在关闭AutoFlush时,需要在适当的时机手动调用flushCommits()方法来确保数据的持久性。
同时,还可以通过设置table.setWriteBufferSize()方法来指定客户端写缓冲区的大小。这可以帮助在缓存中存储更多的数据,减少刷新到RegionServer的次数,提高写入性能。例如:
table.setWriteBufferSize(1024 * 1024); // 设置写缓冲区大小为1MB
在上述示例中,将写缓冲区大小设置为1MB。
总之,通过设置table.setAutoFlush(false)和table.setWriteBufferSize()方法,可以控制AutoFlush行为和客户端写缓冲区大小,以优化写入性能和数据刷新的策略。根据具体的应用需求和场景,可以进行适当的配置调整。
参数优化
Zookeeper 会话超时时间
属性:zookeeper.session.timeout
解释:默认值为 90000 毫秒(90s)。当某个 RegionServer 挂掉,90s 之后 Master 才能察觉到。可适当减小此值,尽可能快地检测 regionserver 故障,可调整至 20-30s,同时可以调整重试时间和重试次数
hbase.client.pause(默认值 100ms)
hbase.client.retries.number(默认 15 次)
设置 RPC 监听数量
属性:hbase.regionserver.handler.count
解释:默认值为 30,用于指定 RPC 监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。
手动控制 Major Compaction
属性:hbase.hregion.majorcompaction
解释:默认值:604800000 秒(7 天), Major Compaction 的周期,若关闭自动 Major Compaction,可将其设为 0。如果关闭一定记得自己手动合并,因为大合并非常有意义。
优化 HStore 文件大小
属性:hbase.hregion.max.filesize
解释:默认值 10737418240(10GB),如果需要运行 HBase 的 MR 任务,可以减小此值,因为一个 region 对应一个 map 任务,如果单个 region 过大,会导致 map 任务执行时间。过长。该值的意思就是,如果 HFile 的大小达到这个数值,则这个 region 会被切分为两个 Hfile。
优化 HBase 客户端缓存
属性:hbase.client.write.buffer
解释:默认值 2097152bytes(2M)用于指定 HBase 客户端缓存,增大该值可以减少 RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少 RPC 次数的目的。
指定 scan.next 扫描 HBase 所获取的行数
属性:hbase.client.scanner.caching
解释:用于指定 scan.next 方法获取的默认行数,值越大,消耗内存越大。
SpringBoot中使用HBase
添加 Maven 依赖:
<!-- HBase 2.4.3 依赖 -->
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>2.4.3</version>
</dependency>
配置 HBase 连接:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;@Configuration
public class HBaseConfig {@Beanpublic Connection hbaseConnection() throws IOException {Configuration config = HBaseConfiguration.create();config.set("hbase.zookeeper.quorum", "localhost"); // HBase ZooKeeper 地址config.set("hbase.zookeeper.property.clientPort", "2181"); // HBase ZooKeeper 端口return ConnectionFactory.createConnection(config);}
}
编写增删改查代码:
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;@Service
public class HBaseService {@Autowiredprivate Connection hbaseConnection;//添加数据public void putData(String tableName, String rowKey, String columnFamily, String column, String value) throws IOException {Table table = hbaseConnection.getTable(TableName.valueOf(tableName));Put put = new Put(Bytes.toBytes(rowKey));put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));table.put(put);table.close();}//删除数据public void deleteData(String tableName, String rowKey) throws IOException {Table table = hbaseConnection.getTable(TableName.valueOf(tableName));Delete delete = new Delete(Bytes.toBytes(rowKey));table.delete(delete);table.close();}//获取数据public String getData(String tableName, String rowKey, String columnFamily, String column) throws IOException {Table table = hbaseConnection.getTable(TableName.valueOf(tableName));Get get = new Get(Bytes.toBytes(rowKey));Result result = table.get(get);byte[] valueBytes = result.getValue(Bytes.toBytes(columnFamily), Bytes.toBytes(column));table.close();return Bytes.toString(valueBytes);}
}
在上述代码中,HBaseConfig 类配置了 HBase 连接,通过 hbaseConnection() 方法创建 HBase 连接。HBaseService 类提供了 putData()、deleteData() 和 getData() 方法,分别用于插入数据、删除数据和获取数据。
Scan
以下是使用Scan 操作的示例代码:
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;import java.io.IOException;public class HBaseScanExample {public static void main(String[] args) throws IOException {// 创建 HBase 配置对象Configuration conf = HBaseConfiguration.create();// 创建 HBase 连接Connection connection = ConnectionFactory.createConnection(conf);// 获取表对象TableName tableName = TableName.valueOf("your_table_name");Table table = connection.getTable(tableName);// 创建 Scan 对象Scan scan = new Scan();scan.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("col1")); // 指定要查询的列族和列// 执行 Scan 操作ResultScanner scanner = table.getScanner(scan);for (Result result : scanner) {// 处理每一行数据byte[] row = result.getRow();byte[] value = result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("col1"));System.out.println("Row key: " + Bytes.toString(row) + ", Value: " + Bytes.toString(value));}// 关闭资源scanner.close();table.close();connection.close();}
}
在上述代码中,首先创建 HBase 配置对象 Configuration,然后通过 ConnectionFactory 创建 HBase 连接 Connection。接下来,通过连接获取表对象 Table,指定要进行 Scan 操作的表名。然后创建 Scan 对象,并使用 addColumn 方法指定要查询的列族和列。最后,使用 getScanner 方法执行 Scan 操作,并遍历 ResultScanner 获取每一行的数据,并进行处理。
Phoenix
Phoenix是一个开源的基于Apache HBase的关系型数据库引擎,它提供了SQL接口来访问HBase中存储的数据。它在HBase的基础上添加了SQL查询和事务功能,使得使用HBase的开发者可以使用熟悉的SQL语言进行数据操作和查询。
Phoenix在HBase中的主要用途包括:
- SQL查询:Phoenix允许开发者使用标准的SQL语句来查询和操作HBase中的数据,无需编写复杂的HBase API代码。这简化了开发过程,降低了使用HBase进行数据访问的门槛。
- 索引支持:Phoenix提供了对HBase数据的二级索引支持,开发者可以使用SQL语句创建索引,从而加快查询速度。索引在数据查询和过滤中起到重要的作用,提高了数据的检索效率。
- 事务支持:Phoenix引入了基于MVCC(多版本并发控制)的事务机制,使得在HBase中进行复杂的事务操作成为可能。开发者可以通过Phoenix的事务功能来保证数据的一致性和可靠性。
- SQL函数和聚合:Phoenix支持各种内置的SQL函数和聚合函数,如SUM、COUNT、MAX、MIN等,使得在HBase上进行数据统计和分析变得更加方便。
要在HBase中使用Phoenix,需要先安装并配置好Phoenix。以下是一个在HBase中使用Phoenix的示例代码:
添加 Maven 依赖: 在 Maven 项目的 pom.xml 文件中添加以下依赖:
<!-- Phoenix 依赖 -->
<dependency><groupId>org.apache.phoenix</groupId><artifactId>phoenix-core</artifactId><version>4.16.0-HBase-2.4</version>
</dependency>
创建 Phoenix 表: 在 HBase 中创建 Phoenix 表。可以使用 Phoenix 提供的 SQL 语法创建表和定义模式。例如,创建一个名为 users 的表:
CREATE TABLE users (id BIGINT PRIMARY KEY,name VARCHAR,age INTEGER
);
使用 Phoenix 进行操作: 在 Java 代码中,可以使用 Phoenix 提供的 PhoenixConnection 和 PhoenixStatement 来执行 SQL 操作。
import java.sql.*;public class PhoenixExample {public static void main(String[] args) throws SQLException {// 创建 Phoenix 连接String url = "jdbc:phoenix:<HBase ZooKeeper Quorum>:<HBase ZooKeeper Port>";Connection connection = DriverManager.getConnection(url);// 执行 SQL 查询String query = "SELECT * FROM users";Statement statement = connection.createStatement();ResultSet resultSet = statement.executeQuery(query);// 处理查询结果while (resultSet.next()) {long id = resultSet.getLong("ID");String name = resultSet.getString("NAME");int age = resultSet.getInt("AGE");System.out.println("ID: " + id + ", Name: " + name + ", Age: " + age);}// 关闭资源resultSet.close();statement.close();connection.close();}
}
在上述代码中,需要将 <HBase ZooKeeper Quorum> 和 <HBase ZooKeeper Port> 替换为你的 HBase ZooKeeper 地址和端口。
通过创建 PhoenixConnection 并传递正确的 JDBC URL,可以获得连接对象。接下来,可以使用 createStatement() 方法创建 PhoenixStatement 对象,并使用 executeQuery() 方法执行 SQL 查询。
然后,可以使用 ResultSet 对象遍历查询结果,并提取所需的字段。在此示例中,遍历了 users 表的结果,并打印了每行的 ID、Name 和 Age。
最后,在总结HBase的基础概念时,我们应该强调其作为一个分布式、可扩展、大数据存储系统的关键特性。
它允许我们进行实时随机读写访问,以及在数十亿行和数百万列上进行高效操作。HBase的设计理念源于Google’s Bigtable,并且与Hadoop生态系统紧密集成。通过使用HBase,开发者和数据科学家可以更好地处理极大规模的数据并提供稳定、高性能的服务。总的来说,HBase是解决当前大数据问题的一种强大工具。