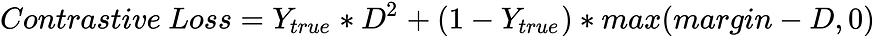学习率
学习率,控制着模型的学习进度。模型训练过程中,如果学习率的值设置得比较大,训练速度会提升,但训练结果的精度不够,损失值容易爆炸;如果学习率的值设置得比较小,精度得到了提升,但训练过程会耗费太多的时间,收敛速度慢,同时也容易出现过拟合的情况。
退化学习率
退化学习率又叫学习率衰减或学习率更新。更新学习率是希望训练过程中,在精度和速度之间找到一个平衡,兼得学习率大核学习率小的优点。即当训练刚开始时使用大的学习率加快速度,训练到一定程度后使用小的学习率来提高精度。
TensorFlow中常用的退化学习率方法
①指数衰减方法
指数衰减是较为常用的衰减方法,学习率是跟当前的训练轮次指数相关的。
tf.train.exponential_decay(learning_rate,global_step,decay_steps,decay_rate,staircase = False,name = None)
参数learning_rate为初始学习率;global_step为当前训练轮次,即epoch;decay_steps用于定义衰减周期,跟参数staircese配合,可以在decay_step个训练轮次内保持学习率不变;decay_rate为衰减率系数;staircase用于定义是阶梯型衰减,还是连续衰减,默认是False,即连续衰减(标准的指数型衰减)。
指数衰减方法中学习率的具体计算公式如下:
decayed_learning_rate = learning_rate*decay_rate^(global_step/decay_steps)
指数衰减方法中学习率的衰减轨迹如下图:

红色的是阶梯型指数衰减,在一定轮次内学习率保持一致
绿色的是标准的指数衰减,即连续型指数衰减
②自然指数衰减方法
指数衰减的一种特殊情况,学习率也是跟当前的训练轮次指数相关,只不过是以e为底数。函数中的参数意义与指数衰减方法中的参数相同。
tf.train.natural_exp_decay(learning_rate,global_step,decay_steps,decay_rate,staircase = False,name = None)
自然指数衰减方法中的学习率的具体计算公式如下:
decayed_learning_rate = learning_rate*exp(-decay_rate*global_step)
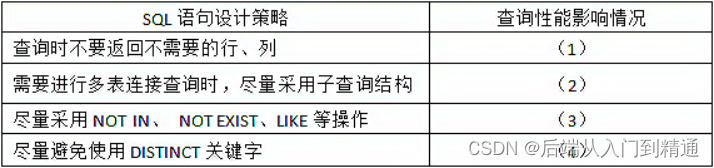
自然指数衰减方法中学习率的衰减轨迹如下图:
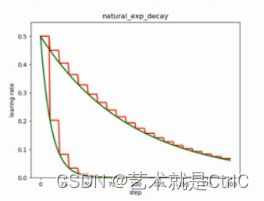
左下部分的两条曲线是自然指数衰减,右上部分的两条曲线是指数衰减。可以明显看到,自然指数衰减对学习率的衰减程度要远大于一般的指数衰减,它一般用于可以较快收敛的网络,或者是训练数据集比较大的场合。
③倒数衰减方法
训练过程中,倒数衰减方法不固定最小学习率,迭代次数越多,学习率越小。学习率的大小跟训练次数有一定的反比关系。
tf.train.inverse_time_decay(learning_rate,global_step,decay_steps,decay_rate,staircase = False,name = None)
参数global_step为用于衰减计算的全局步数,decay_steps为衰减步数,decay_rate为衰减率,staircase用于定义是应用离散阶梯型衰减,还是连续衰减。
倒数衰减方法中学习率的具体计算公式如下:
decayed_learning_rate = learning_rate/(1+decay_rate*global_step/decay_step)
倒数衰减方法中学习率的衰减轨迹如下图:

绿色的是离散阶梯型衰减,红色的是连续型衰减
④分段常数衰减方法
分段常数衰减可以针对不同任务设置不同的学习率,从而进行精细调参。
tf.train.piecewise_constant(x,boundaries,values,name = None)
参数x是标量,指的是global_step,即训练次数;boundaries为学习率参数应用区间列表,即迭代次数所在的区间;values为学习率列表,存放在不同区间该使用的学习率的值。需要注意 : values的长度比boundaries的长度多1,因为两个数可以制定出三个区间,有三个区间要用3个学习率。
分段常数衰减方法中学习率的衰减轨迹如下图:

每个区间内,学习率的值是不一样的
⑤多项式衰减方法
多项式衰减方法的原理为 : 定义一个初始的学习率和一个最低的学习率,然后按照设置的衰减规则,学习率从初始学习率逐渐降低到最低的学习率,并且可以定义学习率降低到最低的值之后,是一直保持使用这个最低的学习率,还是再升高到一定的值,然后再降低到最低的学习率,循环反复这个过程。
tf.train.polynomial_decay(learning_rate,global_step,decay_steps,end_learning_rate = 0.0001,power = 1.0,cycle = False,name = None)
参数global_step为当前训练轮次,即epoch;decay_steps为定义衰减周期;end_learning_rate是最小的学习率,默认值是0.0001;power是多项式的幂,默认值是1,即线性的。cycle用于定义学习率是否到达最低学习率后升高,然后再降低,默认False,保持最低的学习率。
一般情况下多项式衰减方法中学习率的具体计算公式如下:
global_step = min(global_step,decay_steps)
decayed_learning_rate = (learning_rate - end_learning_rate) * (1 - global_step / decay_steps)^(power) + end_learning_rate
如果定义cycle为True,学习率在到达最低学习率后反复升高降低,学习率计算公式如下:
decay_steps = decay_steps * ceil(global_step / decay_steps)
decayed_learning_rate = (learning_rate - end_learning_rate) * (1 - global_step / decay_steps)^(power) + end_learning_rate
多项式衰减方法中学习率的衰减轨迹如下图:

红色的为cycle = False时的情况,下降后不再上升,保持不变;绿色的为cycle = True时的情况,下降后反复升降。
多项式衰减中设置学习率反复升降的目的是为了防止神经网络后期训练的学习率过小,导致网络参数陷入某个局部,找不到最优解;设置学习率升高机制,有可能使网络找出局部最优解。
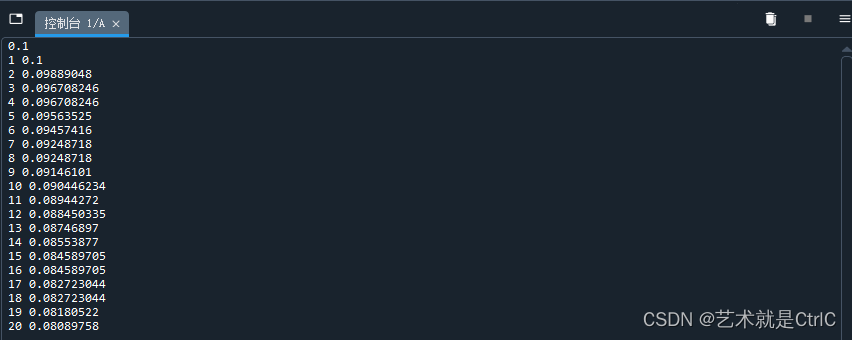
指数衰减示例代码如下:
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_v2_behavior()global_step = tf.Variable(0,trainable=False)
#定义初始学习率
initial_learning_rate = 0.1
#使用指数衰减方法
learning_rate = tf.train.exponential_decay(initial_learning_rate,global_step,decay_steps = 20,decay_rate = 0.8)#定义一个操作,global_step每次加1后完成计步
opt = tf.train.GradientDescentOptimizer(learning_rate)
add_global = global_step.assign_add(1)init = tf.global_variables_initializer()
with tf.Session() as sess:sess.run(init)print(sess.run(learning_rate))#循环20次,将每次的学习率打印出来for i in range(20):g,rate = sess.run([add_global,learning_rate])print(g,rate)