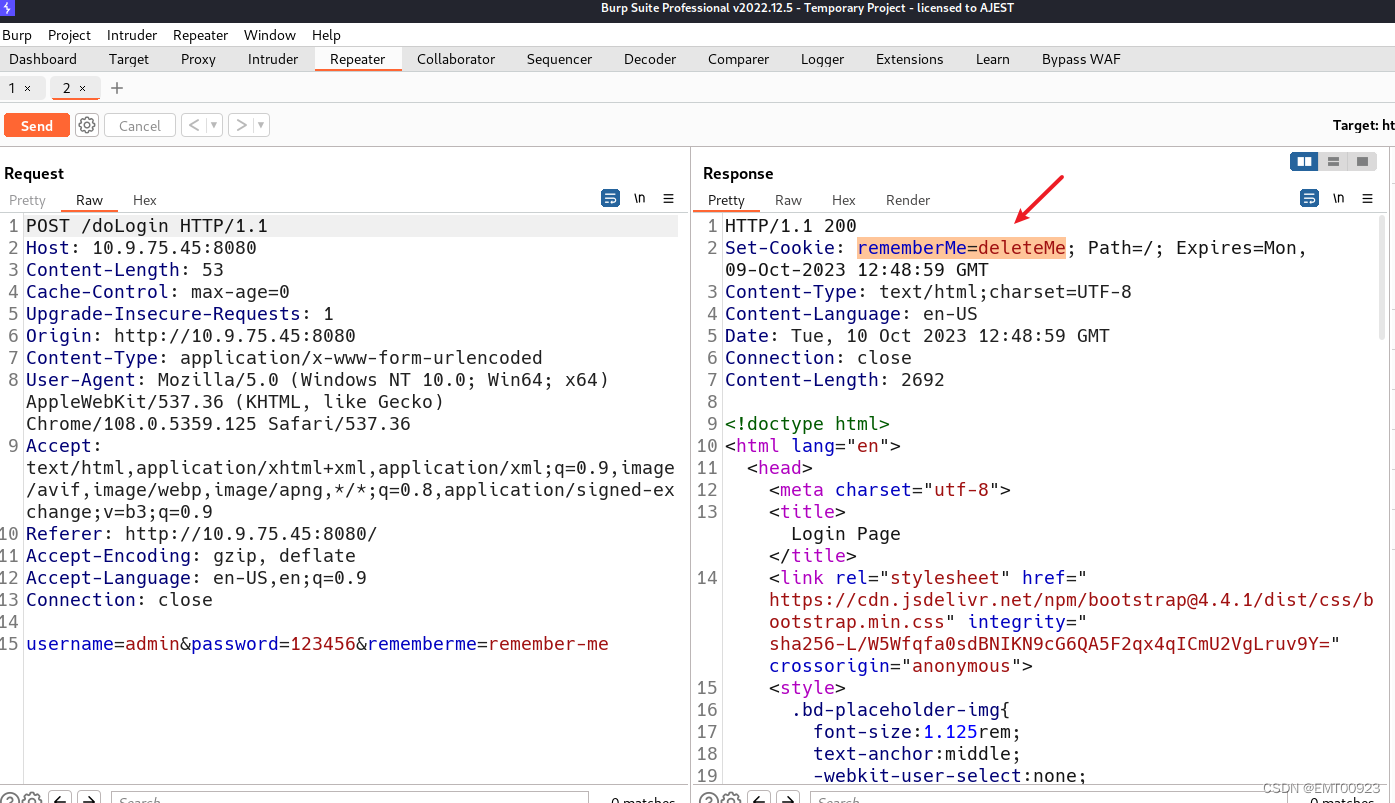
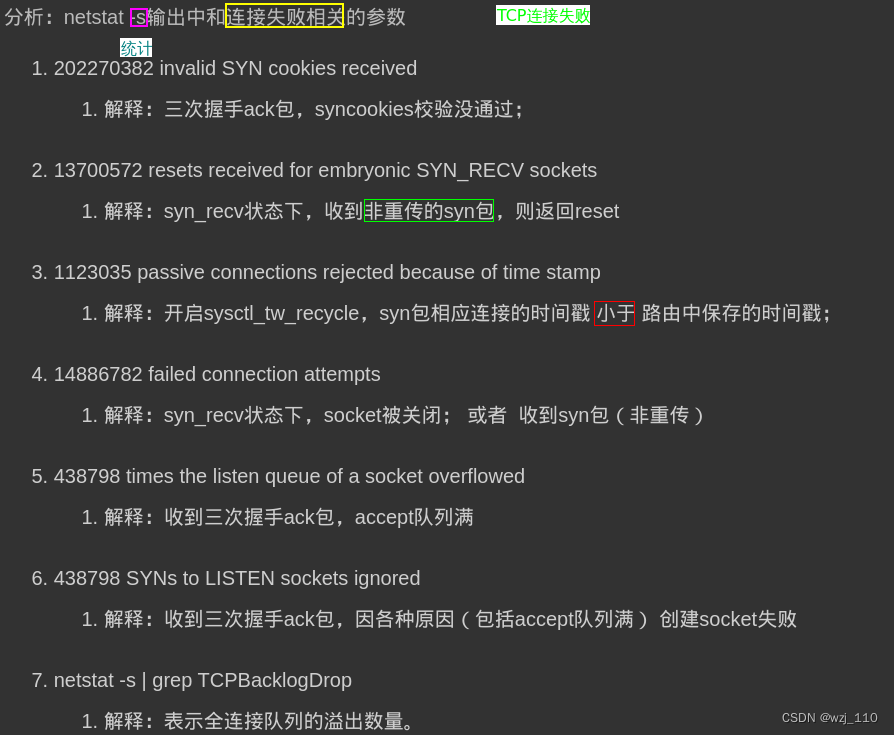
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的动态,一起学习,共同进步。
PySpark 是 Apache Spark 的 Python API。它使您能够使用Python在分布式环境中执行实时、大规模的数据处理。它还提供了一个 PySpark shell,用于交互式分析您的数据。
PySpark 将 Python 的易学性和易用性与 Apache Spark 的强大功能相结合,让熟悉 Python 的每个人都能处理和分析任何规模的数据。
PySpark 支持 Spark 的所有功能,例如 Spark SQL、DataFrames、结构化流、机器学习 (MLlib) 和 Spark Core。
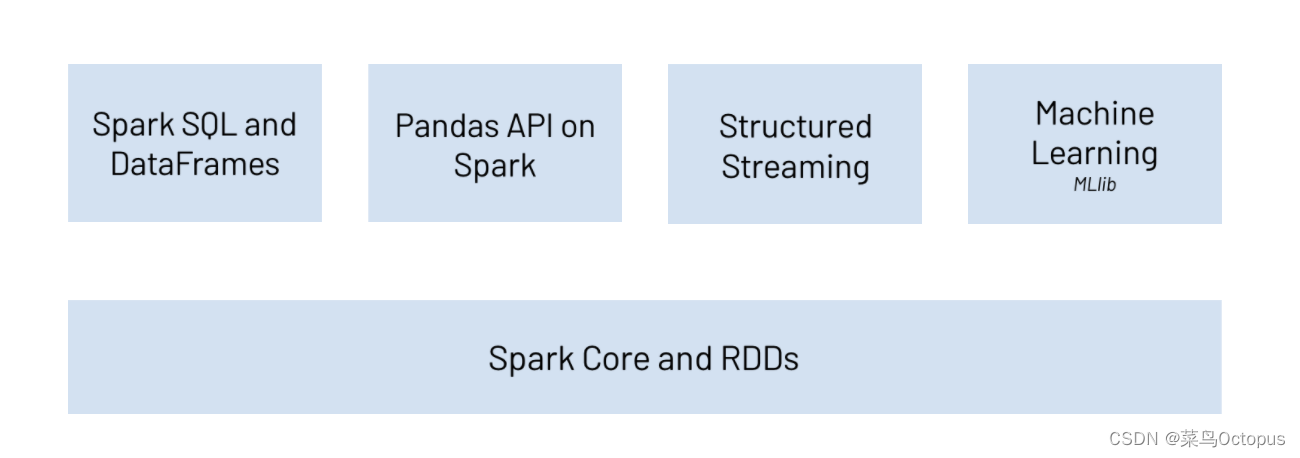
Spark SQL 和 DataFrame
Spark SQL 是 Apache Spark 用于处理结构化数据的模块。它允许您将 SQL 查询与 Spark 程序无缝混合。借助 PySpark DataFrames,您可以使用 Python 和 SQL 高效地读取、写入、转换和分析数据。无论您使用 Python 还是 SQL,都使用相同的底层执行引擎,因此您将始终充分利用 Spark 的全部功能。
-
快速入门:DataFrame
-
实时笔记本:DataFrame
-
Spark SQL API 参考
Spark 上的 Pandas API
Spark 上的 Pandas API 允许您通过跨多个节点分布式运行来将 pandas 工作负载扩展到任意大小。如果您已经熟悉 pandas 并希望利用 Spark 处理大数据,Spark 上的 pandas API 可以让您立即提高工作效率,并让您无需修改代码即可迁移应用程序。您可以拥有一个既适用于 pandas(测试、较小的数据集)又适用于 Spark(生产、分布式数据集)的代码库,并且可以轻松地在 pandas API 和 Spark 上的 Pandas API 之间切换,而无需任何开销。
Spark 上的 Pandas API 旨在使从 pandas 到 Spark 的过渡变得容易,但如果您是 Spark 新手或决定使用哪个 API,我们建议使用 PySpark(请参阅Spark SQL 和 DataFrames)。
-
快速入门:Spark 上的 Pandas API
-
实时笔记本:Spark 上的 pandas API
-
Spark 上的 Pandas API 参考
结构化流媒体
Structured Streaming 是一个基于 Spark SQL 引擎构建的可扩展且容错的流处理引擎。您可以像表达静态数据的批量计算一样表达流计算。Spark SQL 引擎将负责增量且持续地运行它,并随着流数据不断到达而更新最终结果。
-
结构化流编程指南
-
结构化流 API 参考
机器学习(MLlib)
MLlib 构建于 Spark 之上,是一个可扩展的机器学习库,它提供了一组统一的高级 API,可帮助用户创建和调整实用的机器学习管道。
-
机器学习库 (MLlib) 编程指南
-
机器学习 (MLlib) API 参考
Spark 核心和 RDD
Spark Core 是 Spark 平台的底层通用执行引擎,所有其他功能都构建在其之上。它提供RDD(弹性分布式数据集)和内存计算能力。
请注意,RDD API 是一个低级 API,可能难以使用,并且您无法从 Spark 的自动查询优化功能中受益。我们建议使用 DataFrame(请参阅上面的Spark SQL 和 DataFrame)而不是 RDD,因为它可以让您更轻松地表达您想要的内容,并让 Spark 自动为您构建最高效的查询。
-
Spark 核心 API 参考
Spark 流(旧版)
Spark Streaming 是核心 Spark API 的扩展,可实现实时数据流的可扩展、高吞吐量、容错流处理。
请注意,Spark Streaming 是上一代 Spark 流引擎。这是一个遗留项目,不再更新。Spark 中有一个更新且更易于使用的流引擎,称为 “结构化流”,您应该将其用于流应用程序和管道。
-
Spark Streaming 编程指南(旧版)
-
Spark Streaming API 参考(旧版)