目录
- 问题描述及配置
- 网上资料查找
- 1.tqdm问题
- 2.dataloader问题
- 3.model(input)写法问题
- 4.环境变量问题
- 我的卡死问题解决方法
问题描述及配置
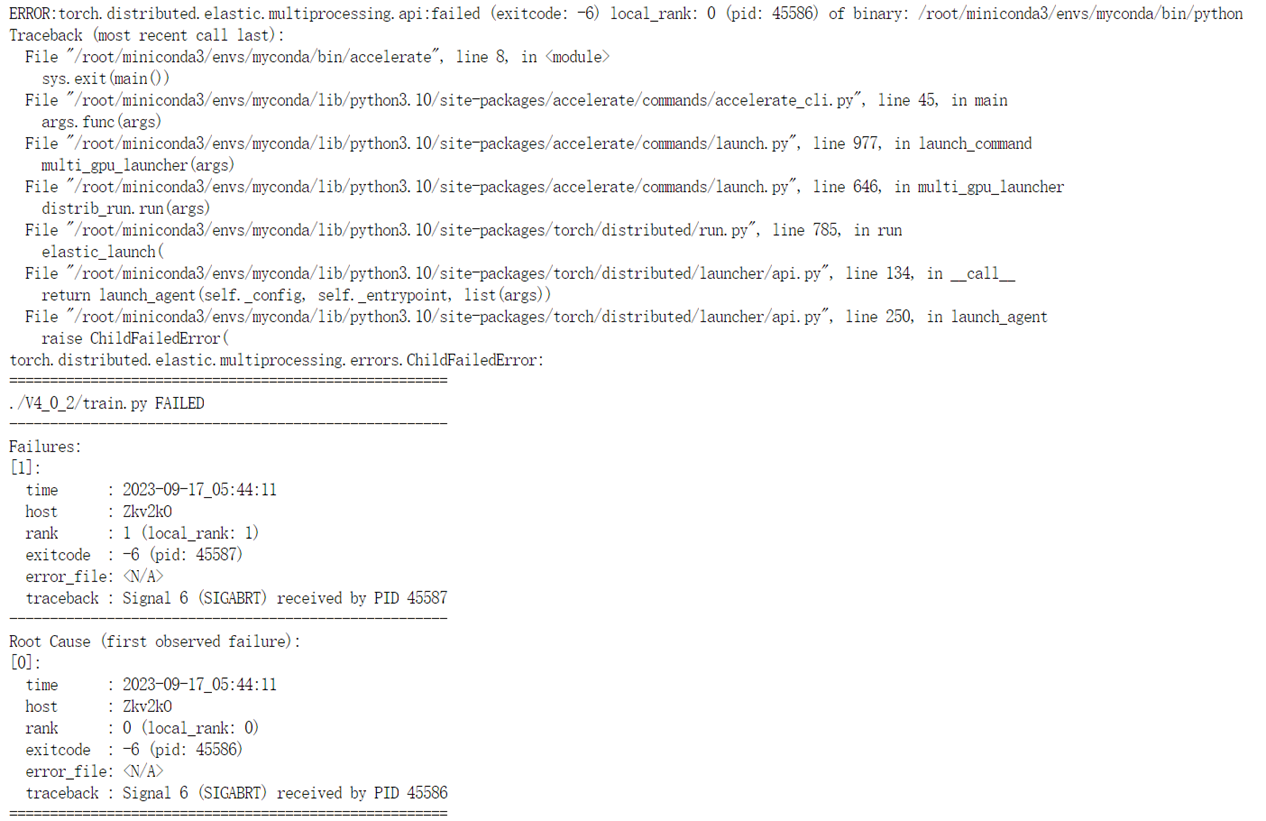
在使用hugging face开源库accelerate进行多GPU训练(单机多卡)的时候,经常出现如下报错
[E ProcessGroupNCCL.cpp:828] [Rank 1] Watchdog caught collective operation timeout: WorkNCCL(OpType=BROADCAST, Timeout(ms)=1800000) ran for 1808499 milliseconds before timing out.
[E ProcessGroupNCCL.cpp:587] [Rank 0] Watchdog caught collective operation timeout: WorkNCCL(OpType=ALLREDUCE, Timeout(ms)=1800000) ran for 1808493 milliseconds before timing out.
而且,程序能正常运行几十个epoch,然后在运行中间卡死。卡死的位置永远是出现在测试集进行eval结束之后,而不是出现在对训练集的训练过程中。
例如,我每40个epoch进行一次测试(eval),那么卡死经常会出现在第80个epoch,或者第120个epoch的位置,有时候还会出现在第400个epoch。
完整报错如下图所示


网上资料查找
我查阅网上资料,有很多种方法解决如下问题,虽然网上所查阅到的方法都没有解决我的问题,但是在这里都记录一下,或许对大家有用:
1.tqdm问题
有说在训练过程中,如果使用了tqdm打印进度条会出现卡死的问题,需要将所有tqdm代码都删除
2.dataloader问题
dataloader分为两种问题:
- 有的博客说使用pytorch中的dataloader对dataset进行封装的时候,在多GPU训练的情况下会卡死,所以需要去除dataloader的封装,直接使用dataset进行训练(但是我认为这种说法不可靠)
- 有的博客说使用dataloader的时候,如果设置了drop_last=False,或者是设置了shuffle=True,会导致开始(我认为这种说法也不可靠)
3.model(input)写法问题
在给予模型输入,进行正向传播的时候,我们通常写法是
output=model(input)
一些说法说这种写法在多GPU训练的时候,在模型进行eval的时候需要改一下:
output=model.module(input)
这样即可解决问题
4.环境变量问题
环境变量问题应该是最主要的一个解决方案,即更改环境变量。更改环境变量有很多方法,这里说一下在bash中临时更改环境变量的方法:
即在bash中输入
export NCCL_P2P_LEVEL=NVL
或者输入
export NCCL_P2P_DISABLE=1
然后再运行多GPU训练的代码
我的卡死问题解决方法
我经过长时间调试,发现我的问题出在这里:
我每次在eval的时候,都会判断这次测试集的loss是否和以往的相比是否是最小的,如果是最小的,那么获取这一个epoch的模型参数,问题就出现在获取模型参数这里(红框画出来的)
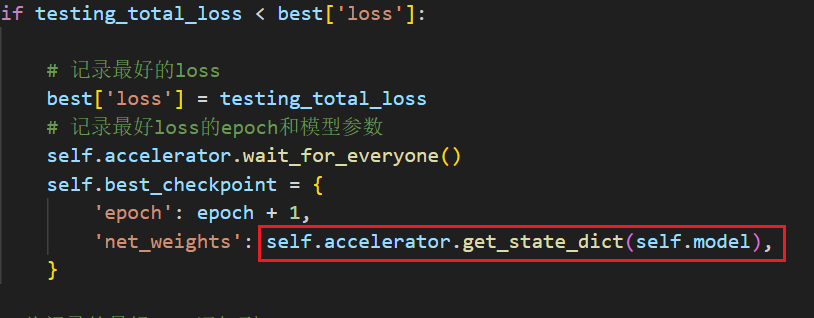
或者如果不加self.accelerator.wait_for_everyone()也是一样的,会出现同样的问题
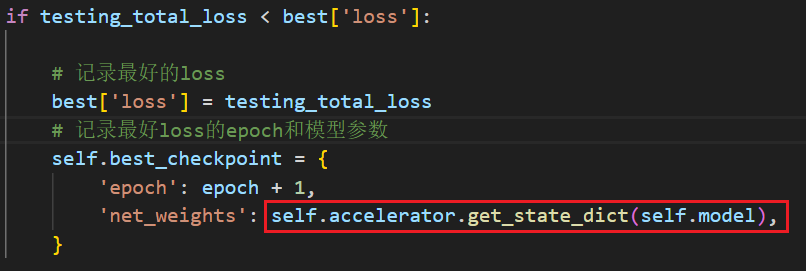
卡死就在获取模型参数的部分,这里就是“有概率”出现卡死,因为运行一次可能没问题,但是如果我每40个epoch就运行一次eval,那么在第80个,第120个epoch就会卡死。
我猜测这是由于accelerate是通过多进程来控制多个GPU进行训练的,这里多个进程都去获取模型参数,所以才会出现卡死的情况。
因此,解决方法如下:
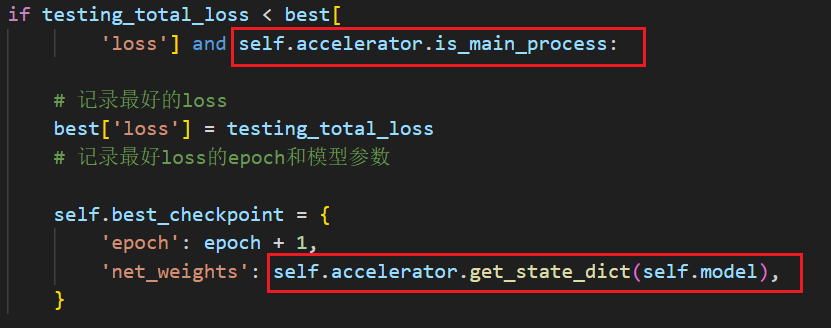
在判断条件中要加上判断是否在主进程中,然后去掉self.accelerator.wait_for_everyone()
这样就解决了卡死的问题。


![[elasticsearch]使用postman来查询数据](https://img-blog.csdnimg.cn/3b1ff48126d54057ae31ccc61ceaea39.png)