目录
1、环境设置
方式1:在Maven工程中添加pom依赖
方式2:在 sql-client.sh 中添加 jar包依赖
2、读取Kafka
2.1 创建 kafka表
2.2 读取 kafka消息体(Value)
使用 'format' = 'json' 解析json格式的消息
使用 'format' = 'csv' 解析csv格式的消息
使用 'format' = 'raw' 解析kafka消息为单个字符串字段
2.3 读取 kafka消息键(Key)
2.4 读取 kafka元数据(Metadata)
2.5 如何指定起始消费位点
从指定的timestamp开始消费:
从指定的timestamp开始消费:
2.6 创建 kafka表时,添加水位线生成策略
3、写入Kafka
3.1 写入 kafka时,可以指定的元数据
1、环境设置
Kafka 连接器提供从 Kafka topic 中消费和写入数据的能力。
官网链接:官网
方式1:在Maven工程中添加pom依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>1.17.1</version>
</dependency>
方式2:在 sql-client.sh 中添加 jar包依赖
将 flink-sql-connector-kafka-1.17.1.jar 上传到flink的lib目录下 (可以去官网下载jar包)
或者 启动 sql-client.sh 时,指定jar依赖
bin/sql-client.sh -j lib/flink-sql-connector-kafka-1.17.1.jar2、读取Kafka
2.1 创建 kafka表
CREATE TABLE SourceKafkaTable (指定物理字段,指定元数据字段,指定水位线生成策略
) WITH ('connector' = 'kafka', --【必选】指定 连接器类型,kafka用'kafka''properties.bootstrap.servers' = 'localhost:9092', --【必选】指定 Kafka broker列表,用逗号分隔'topic' = 'user_behavior', --【必选】指定 topic列表,用逗号分隔'topic-pattern' = '.*log_kafka.*', --【必选】指定 匹配读取 topic 名称的正则表达式, 和 topic 配置一个即可'properties.group.id' = 'testGroup', --【可选】指定 消费者组id,不指定时会自定生成 KafkaSource-{tableIdentifier}'scan.startup.mode' = 'earliest-offset', --【可选】指定起始消费位点,默认值 earliest-offset'format' = 'csv' --【必选】指定 消息的格式类型, 和 value.format 是等价的(配置一个即可)
);2.2 读取 kafka消息体(Value)
在FlinkSQL读取kafka时,可以根据kafka存储的消息的格式,通过 'value.format' = 'csv|raw|json...'
来指定使用哪种格式来对kafka消息进行解析,并将解析的结果映射到表中的字段中去。

使用 'format' = 'json' 解析json格式的消息
当 kafka消息为json格式,可以使用 'format' = 'json' 在创建表时对json串进行解析,并将解析后的结果映射到表中的字段中去
注意:这种方式只能解析单层级的json格式,多层级时无法解析
如果为多层级json格式时,可以使用raw格式 + udf函数来对json进行解析
导入Maven的pom依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>1.17.1</version>
</dependency>
创建FlinkTable
-- TODO 创建用于读取kafka消息的flink表(消息格式为json)
-- kafka消息示例:{"ID":0,"NAME":"大王0"}
CREATE TABLE kafka_table_source_json (`ID` STRING,`NAME` STRING
) WITH ('connector' = 'kafka','topic' = '20231009','properties.bootstrap.servers' = 'worker01:9092','properties.group.id' = 'FlinkConsumer','scan.startup.mode' = 'earliest-offset','format' = 'json','json.fail-on-missing-field' = 'false','json.ignore-parse-errors' = 'true'
);-- TODO 解析json串时,容错性设置
'json.fail-on-missing-field' = 'false' -- 当解析字段缺失时,是跳过当前字段或行,还是抛出错误失败(默认为 false,即抛出错误失败)
'json.ignore-parse-errors' = 'true' -- 当解析异常时,是跳过当前字段或行,还是抛出错误失败(默认为 false,即抛出错误失败)。如果忽略字段的解析异常,则会将该字段值设置为null。-- 触发读取kafka操作
select * from kafka_table_source_json;运行结果:

使用 'format' = 'csv' 解析csv格式的消息
当 kafka消息为csv格式,可以使用 'format' = 'csv' 在创建表时对csv进行解析,并将解析后的结果映射到表中的字段中去
导入Maven的pom依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>1.17.1</version>
</dependency>创建FlinkTable
-- TODO 创建用于读取kafka消息的flink表(消息格式为csv)
-- kafka消息示例:2,3.1
CREATE TABLE kafka_table_source_csv (`order_id` BIGINT,`price` DOUBLE
) WITH ('connector' = 'kafka','topic' = 'csv_format','properties.bootstrap.servers' = 'worker01:9092','properties.group.id' = 'FlinkConsumer','scan.startup.mode' = 'earliest-offset','value.format' = 'csv'
);-- 触发读取kafka操作
select * from kafka_table_source_csv;运行结果:

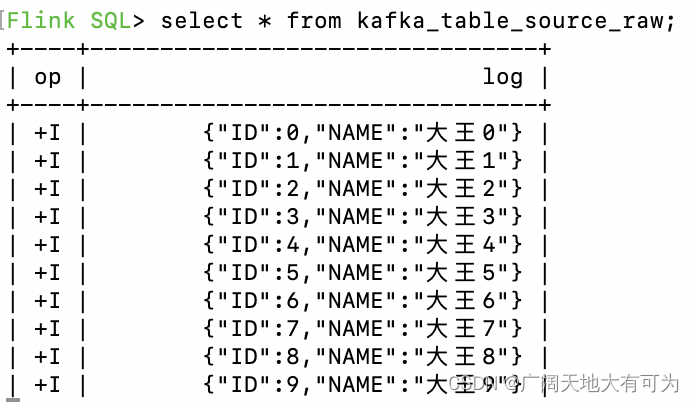
使用 'format' = 'raw' 解析kafka消息为单个字符串字段
可以使用 'format' = 'raw' 将kafka消息以原始格式映射到flink表中的string类型的字段中
创建FlinkTable
-- TODO 创建用于读取kafka消息的flink表(消息格式为json)
-- kafka消息示例:{"ID":0,"NAME":"大王0"}
CREATE TABLE kafka_table_source_raw (`log` STRING
) WITH ('connector' = 'kafka','topic' = '20231009','properties.bootstrap.servers' = 'worker01:9092','properties.group.id' = 'FlinkConsumer','scan.startup.mode' = 'earliest-offset','format' = 'raw'
);-- 触发读取kafka操作
select * from kafka_table_source_raw;运行结果:
2.3 读取 kafka消息键(Key)
kafka消息信息:
{"key":{"ID_1":0,"NAME_1":"大王0"},"value":{"ID":0,"NAME":"大王0"},"metadata":{"offset":0,"topic":"readKey","partition":0}
}创建FlinkTable
-- 读取kafka消息中的key部分
CREATE TABLE kafka_table_source_read_key (`ID` STRING,`NAME` STRING,`ID_1` STRING,`NAME_1` STRING
) WITH ('connector' = 'kafka','topic' = 'readKey','properties.bootstrap.servers' = 'worker01:9092','properties.group.id' = 'FlinkConsumer','scan.startup.mode' = 'earliest-offset','key.format' = 'json','key.json.ignore-parse-errors' = 'true','key.fields' = 'ID_1;NAME_1','value.format' = 'json'
);2.4 读取 kafka元数据(Metadata)
创建FlinkTable
-- TODO 创建读取kafka表时,同时读取kafka元数据字段
CREATE TABLE kafka_table_source_read_metadata (`log` STRING,`topic` STRING METADATA VIRTUAL, -- 消息所属的 topic`partition` BIGINT METADATA VIRTUAL, -- 消息所属的 partition ID`offset` BIGINT METADATA VIRTUAL, -- 消息在partition中的 offset`timestamp` TIMESTAMP(3) METADATA FROM 'timestamp' -- 消息的时间戳
) WITH ('connector' = 'kafka','topic' = 'readKey','properties.bootstrap.servers' = 'worker01:9092','properties.group.id' = 'FlinkConsumer','scan.startup.mode' = 'earliest-offset','format' = 'raw'
);select * from kafka_table_source_read_metadata;
2.5 如何指定起始消费位点
scan.startup.mode 配置项决定了 Kafka consumer 的启动模式。有效值为:
group-offsets:从 Zookeeper/Kafka 中某个指定的消费组已提交的偏移量开始。earliest-offset:从可能的最早偏移量开始。latest-offset:从最末尾偏移量开始。timestamp:从用户为每个 partition 指定的时间戳开始。- 如果使用了
timestamp,必须使用另外一个配置项scan.startup.timestamp-millis=时间戳(毫秒值)
- 如果使用了
specific-offsets:从用户为每个 partition 指定的偏移量开始。- 如果使用了
specific-offsets,必须使用另外一个配置项scan.startup.specific-offsets来为每个 partition 指定起始偏移量, 例如,选项值partition:0,offset:42;partition:1,offset:300表示 partition0从偏移量42开始,partition1从偏移量300开始
- 如果使用了
默认值 group-offsets 表示从 Zookeeper/Kafka 中最近一次已提交的偏移量开始消费。

从指定的timestamp开始消费:
// --------------------------------------------------------------------------------------------
// TODO 从指定的timestamp开始消费
// --------------------------------------------------------------------------------------------
drop table kafka_table_source_test_startup_timestamp;
CREATE TABLE kafka_table_source_test_startup_timestamp (`log` STRING,`ts` TIMESTAMP(3) METADATA FROM 'timestamp',`offset` BIGINT METADATA VIRTUAL
) WITH ('connector' = 'kafka','topic' = '20231009','properties.bootstrap.servers' = 'worker01:9092','properties.group.id' = 'FlinkConsumer','scan.startup.mode' = 'timestamp', -- 从用户为每个 partition 指定的时间戳开始'scan.startup.timestamp-millis' = '1697008386973', -- 从 指定的timestamp开始(包括)消费'value.format' = 'raw'
);select *
,cast(UNIX_TIMESTAMP(cast(ts as string), 'yyyy-MM-dd HH:mm:ss.SSS') as string) || SPLIT_INDEX(cast(ts as string),'.',1) as timestamp_hmz
from kafka_table_source_test_startup_timestamp;运行结果:

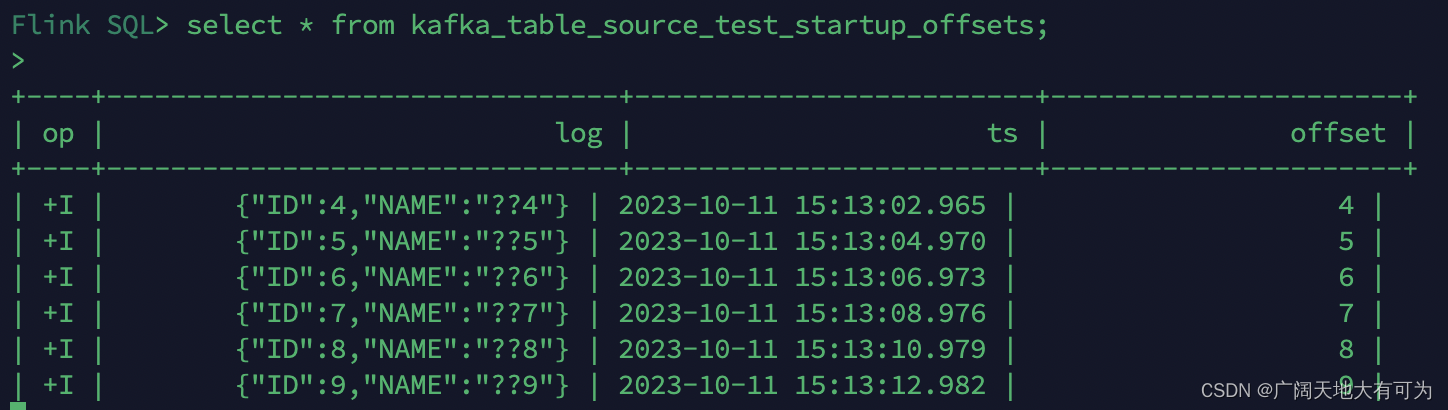
从指定的timestamp开始消费:
// --------------------------------------------------------------------------------------------
// TODO 从指定的offset开始消费
// --------------------------------------------------------------------------------------------
drop table kafka_table_source_test_startup_offsets;
CREATE TABLE kafka_table_source_test_startup_offsets (`log` STRING,`ts` TIMESTAMP(3) METADATA FROM 'timestamp',`offset` BIGINT METADATA VIRTUAL
) WITH ('connector' = 'kafka','topic' = '20231009','properties.bootstrap.servers' = 'worker01:9092','properties.group.id' = 'FlinkConsumer','scan.startup.mode' = 'specific-offsets', -- 从用户为每个 partition 指定的偏移量开始'scan.startup.specific-offsets' = 'partition:0,offset:4', -- 为每个 partition 指定起始偏移量'value.format' = 'raw'
);select * from kafka_table_source_test_startup_offsets;运行结果:
2.6 创建 kafka表时,添加水位线生成策略
// --------------------------------------------------------------------------------------------
// TODO 创建 kafka表时,添加水位线生成策略
// --------------------------------------------------------------------------------------------
drop table kafka_table_source_test_watermark;
CREATE TABLE kafka_table_source_test_watermark (`log` STRING,`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',`offset` BIGINT METADATA VIRTUAL,WATERMARK FOR event_time AS event_time -- 根据kafka的timestamp,生成水位线,使用 严格递增时间戳水位线生成策略
) WITH ('connector' = 'kafka','topic' = '20231009','properties.bootstrap.servers' = 'worker01:9092','properties.group.id' = 'FlinkConsumer','scan.startup.mode' = 'specific-offsets', -- 从用户为每个 partition 指定的偏移量开始'scan.startup.specific-offsets' = 'partition:0,offset:4', -- 为每个 partition 指定起始偏移量'value.format' = 'raw'
);select * from kafka_table_source_test_watermark;3、写入Kafka
3.1 写入 kafka时,可以指定的元数据
// --------------------------------------------------------------------------------------------
// TODO 通过flinksql向kafka写入数据(写入时指定 timestamp)
// --------------------------------------------------------------------------------------------
drop table kafka_table_source_test_startup_mode;
CREATE TABLE kafka_table_source_test_startup_mode (`order_id` BIGINT,`price` DOUBLE,`ts` TIMESTAMP(3) METADATA FROM 'timestamp',`offset` BIGINT METADATA VIRTUAL
) WITH ('connector' = 'kafka','topic' = '20231011','properties.bootstrap.servers' = 'worker01:9092','properties.group.id' = 'FlinkConsumer','scan.startup.mode' = 'earliest-offset','value.format' = 'csv'
);insert into kafka_table_source_test_startup_mode(order_id, price,ts)
SELECT * FROM (VALUES(1, 2.0,TO_TIMESTAMP_LTZ(1000, 3))
, (2, 4.0,TO_TIMESTAMP_LTZ(2000, 3))
, (3, 6.0,TO_TIMESTAMP_LTZ(3000, 3))
, (4, 7.0,TO_TIMESTAMP_LTZ(4000, 3))
, (5, 8.0,TO_TIMESTAMP_LTZ(5000, 3))
, (6, 10.0,TO_TIMESTAMP_LTZ(6000, 3))
, (7, 12.0,TO_TIMESTAMP_LTZ(7000, 3))
) AS book (order_id, price,ts);-- 触发读取kafka操作
select * from kafka_table_source_test_startup_mode;