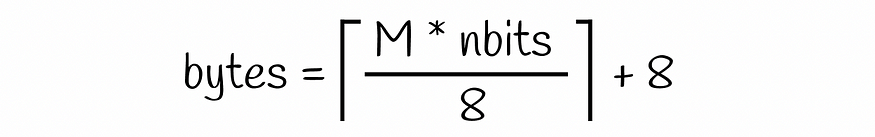正则表达式
当处理文本数据时,正则表达式是一种强大的工具,它允许我们根据特定的模式来匹配、搜索和处理字符串。
正则表达式由一系列字符和特殊字符组成,用于描述文本模式。这些模式可以包含普通字符(如字母、数字和标点符号)以及特殊字符,用于表示匹配特定模式的规则。
1.普通字符
字母、数字、汉字、下划线、以及没有特殊定义的标点符号,都是"普通字符"。表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的一个字符。
2.转义字符
| 表达式 | 可匹配 |
|---|---|
| \n | 换行符 |
| \t | 制表符 |
| \ | \符号 |
| ^ | ^符号 |
| $ | $符号 |
| . | .符号 |
| ? | ?符号 |
| * | *符号 |
| + | +符号 |
| { | 大括号 |
| [ | 中括号 |
| ( | 小括号 |
3.能够与 ‘多种字符’ 匹配的表达式
| 表达式 | 可匹配 |
|---|---|
| \d | 0~9中任意一个数字 |
| \w | 任意一个字母或数字或下划线 |
| \s | 包括空格、制表符、换页符等空白字符的其中任意一个 |
| . | 小数点可以匹配除了换行符(\n)以外的任何一个字符 |
4.自定义能够匹配 ‘多种字符’ 的表达式
| 表达式 | 可匹配 |
|---|---|
| [ab5@] | 匹配“a”或“b”或“5”或“@” |
| [^abc] | 匹配“a”,“b”,“c”之外的任意一个字符 |
| [f-k] | 匹配“f”~“k”之间的任意一个字符 |
5.修饰匹配次数的特殊符号
| 表达式 | 可匹配 |
|---|---|
| {n} | 表达式重复n次,“\w{2}”相当于“\w\w” |
| {m,n} | 表达式至少重复m次,最多重复n次,“ba{1,3}”可以匹配“ba”,“baa”,“baaa” |
| {m,} | 表达式至少重复m次 |
| ? | 匹配表达式0次或者1次,相当于{0,1} |
| + | 表达式至少出现1次,相当于{1,} |
| * | 表达式不出现或者出现任意次,相当于{0,} |
6.一些代表抽象意义的特殊符号
| 表达式 | 可匹配 |
|---|---|
| ^ | 与字符串开始的地方匹配,不匹配任何字符 |
| $ | 与字符串结束的地方匹配,不匹配任何字符 |
| | | 左右两边表达式之间“或”关系,匹配左边或右边,和括号配合使用 |
| () | 在被修饰匹配次数时,括号中的表达式可以作为整体被修饰; 取匹配结果时,括号中的表达式匹配到的内容可以被单独取到 |
import re
re 模块使 Python 语言拥有全部的正则表达式功能。它提供了一种强大的工具来在文本中进行模式匹配和搜索操作。当正则表达式包含转义符时,建议使用raw string。
在Python中,原始字符串(raw string)是指字符串字面值(literal)的一种表示形式,它通过在字符串前面添加前缀 r 或 R 来表示。原始字符串的特点是,它会将转义字符(如反斜杠 \)视为普通字符,而不会对其进行转义。正常的字符串字面值中,反斜杠 \ 可以用于表示特殊字符序列,例如 \n 表示换行符、\t 表示制表符等。但有时候,我们希望将字符串中的反斜杠作为普通字符处理,而不是转义字符。这时就可以使用原始字符串。举个列子:
normal_string = "Hello\nWorld"
raw_string = r"Hello\nWorld"print(normal_string) # 输出:Hello
# World (换行)
print(raw_string) # 输出:Hello\nWorld
re函数
| 函数 | 说明 |
|---|---|
| re.compile | 用于编译正则表达式,生成一个正则表达式( Pattern )对象 |
| re.match | 从字符串的起始位置匹配一个模式 |
| re.search | 扫描整个字符串并返回第一个成功的匹配 |
| re.findall | 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表 |
| re.sub | 用于替换字符串中的匹配项 |
| re.split | 按照能够匹配的子串将字符串分割后返回列表 |
字符串匹配
import re# 编译正则表达式
pattern = re.compile(r'hello')# 匹配字符串
match = pattern.match('hello world')
if match:print('Match found:', match.group())
else:print('No match')# 搜索字符串
search = pattern.search('hello world')
if search:print('Search found:', search.group())
else:print('No search')# 查找所有匹配项
matches = pattern.findall('hello world, hello python')
print('All matches:', matches)# 替换匹配项
replace = pattern.sub('hi', 'hello world, hello python')
print('After replacement:', replace)# 分割字符串
split = pattern.split('hello world, hello python')
print('Split result:', split)
从文本文件中提取指定特征
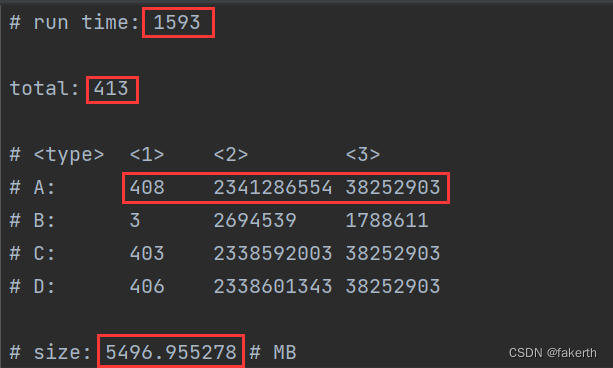
我们要从如下文本提取指定的如下特征:
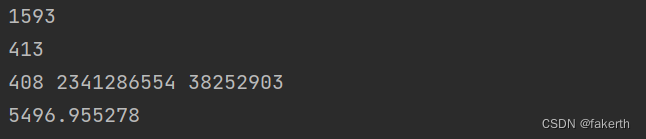
# run time: 1593total: 413# <type> <1> <2> <3>
# A: 408 2341286554 38252903
# B: 3 2694539 1788611
# C: 403 2338592003 38252903
# D: 406 2338601343 38252903# size: 5496.955278 # MB
import redef extracting(path):Runtime_PATTERN = '(#\s+run\s+time:\s+)(\d+)'ds_runtime_pattern = re.compile(Runtime_PATTERN)Total_PATTERN = '(total:\s+)(\d+)'ds_total_pattern = re.compile(Total_PATTERN)A_PATTERN = '(#\sA:\s+)(\d+)\s+(\d+)\s+(\d+)'ds_a_pattern = re.compile(A_PATTERN)Size_PATTERN = '(#\s+size:\s+)(\d+\.\d+)(\s+#+\s)(\S+)'ds_size_pattern = re.compile(Size_PATTERN)with open(path) as infile:for line in infile:runtime_match = ds_runtime_pattern.match(line)if runtime_match is not None:runtime = int(runtime_match.group(2))print(runtime)continuetotal_match = ds_total_pattern.match(line)if total_match is not None:total = int(total_match.group(2))print(total)continuea_match = ds_a_pattern.match(line)if a_match is not None:a_col1 = int(a_match.group(2))a_col2 = int(a_match.group(3))a_col3 = int(a_match.group(4))print(a_col1, end=' ')print(a_col2, end=' ')print(a_col3)continuesize_match = ds_size_pattern.match(line)if size_match is not None:size = float(size_match.group(2))print(size)continueif __name__ == "__main__":extracting('test.txt')运行结果: