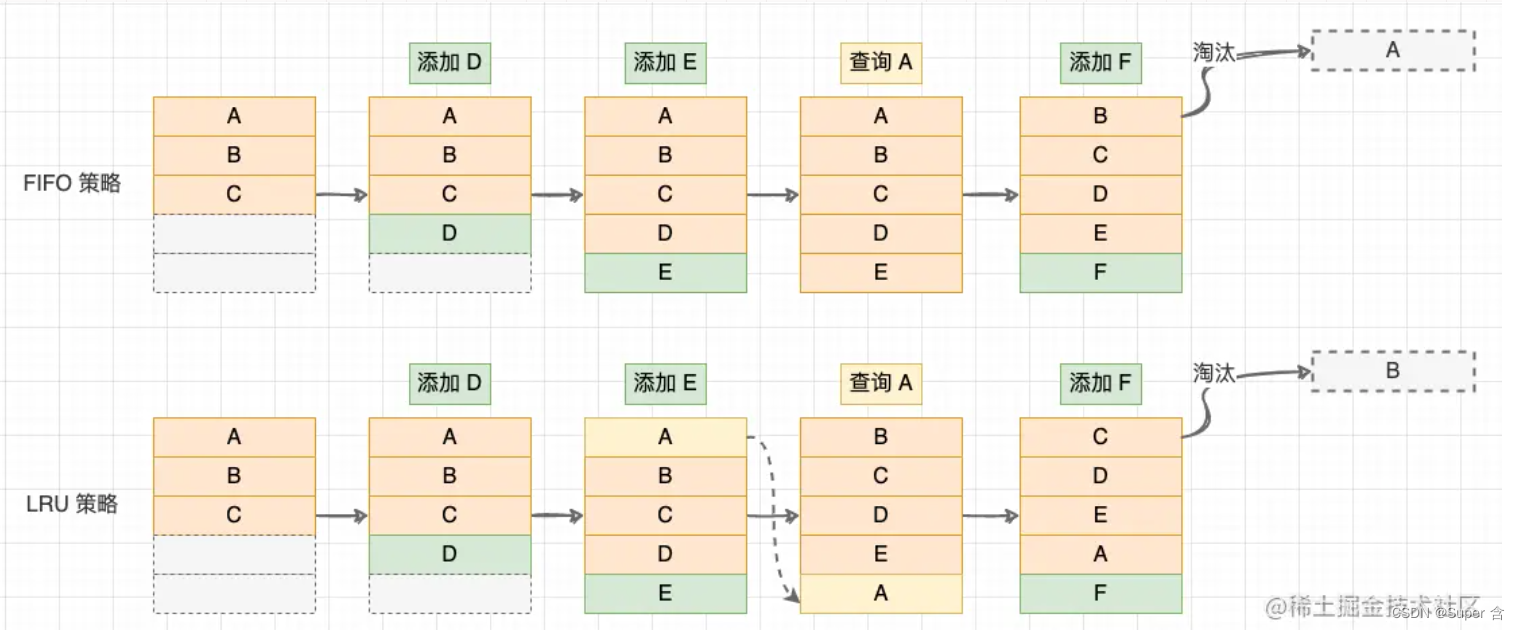
Overview
- LLaVA-1.5
- 总览
- 摘要
- 1.引言
- 2.背景
- 3.LLaVA的改进
- 4.讨论
- 附录
LLaVA-1.5
总览
题目: Improved Baselines with Visual Instruction Tuning
机构:威斯康星大学麦迪逊分校,微软
论文: https://arxiv.org/pdf/2310.03744.pdf
代码: https://llava-vl.github.io/
任务: 多模态大模型
特点: 预训练与指令微调只用非常少的数据(8张A100训练一天),就可以超过InstructBLIP和千问-VL。
- LLaVA-1.5(预训练:558K,指令微调:665K,分辨率336,LLM:Vicuna 13B,projector:两层全连接)
- InstructBLIP(预训练:129M,指令微调:1.2M,分辨率:224,LLM:Vicuna 13B,projecter:Q-former)
- 千问-VL(预训练:1.4B,指令微调:50M,分辨率:448,LLM:千问-7B,projecter:VL-Adapter)等模型
方法: 研究数据、模型和图像输入分辨率的规模影响;
- 数据上(1)使用了InstructBLIP的VQA子集(2)VQA指令格式优化(3)ShareGPT多语言纯文本数据
- 模型上(1)双层全连接层充当adapter(2)LLM Vicuna 7B -> Vicuna 13B
- 分辨率上 224 -> 336
前置相关工作:LLaVA,千问-VL,InstructBLIP
历史博客:多模态大模型综述: LLaVA, MiniGPT4
摘要
近期,大型多模态模型(LMM)在视觉指令调优方面展示出了鼓舞人心的进步。在这篇简报中,我们证明了LLaVA中全连接的视觉语言跨模态连接器的强大力量和高效的数据效率。通过对LLaVA进行简单的修改,即使用带有MLP(多层感知器)映射的CLIP-ViT-L-336px,并添加以学术任务为导向,带有简单响应格式提示的视觉问答数据,我们成功建立了在11个基准测试中达到最先进水平的更强基线。我们最终的13B checkpoint仅使用了1.2M公开可用的数据,在单个8-A100节点上完成了全程训练,仅需大约1天的时间。我们希望这能让最先进的LMM研究更易于接触。代码和模型将公开发布。
1.引言
大型多模态模型(LMMs)已在研究社区中愈发受到欢迎,因为它们是通向通用助理的关键基础模块[1, 22, 35]。近期对LMMs的研究逐渐聚焦于被称为视觉指令调优[28]的核心概念上。结果十分令人鼓舞,例如,LLaVA[28]和MiniGPT-4[49]在自然指令跟随和视觉推理能力上展示出了卓越的成果。为了更好地了解LMMs的能力,已有多个基准测试[MME 11, Seed bench 20, 26, MM bench 29, 43]被提出。最近的研究进一步通过扩大预训练数据[千问-VL 2, InsctructBLIP 9],指令跟随数据[9, Otter 21, Llavar 45, Svit 46],视觉编码器[2]或语言模型[31]来展示改进的性能。LLaVA架构也被用于不同的下游任务和域,包括区域级别[Shikra 6, GPT2ROI 44]和像素级别[LISA 19]的理解,生物医学助手[23],图像生成[3],对抗性研究[4, 47]。
本文在LLaVA框架的基础上建立了更强,更可行的基线。我们报道了两个简单的改进,也就是,一个MLP跨模态连接器和结合如VQA这样的学术任务相关数据,它们与LLaVA的框架是正交的,而且当它们和LLaVA一起使用的时候,这会带来更好的多模态理解能力。与InstructBLIP [9]或Qwen-VL [2]相反,后两者在几亿,几十亿甚至更多的图像-文本配对数据上训练专门设计的视觉重新采样器,LLaVA仅使用最简单的LMMs架构设计,并且只需要在仅有的600K图像-文本配对上训练一个简单的全连接投影层。我们的最终模型可以在一台单个的8-A100机器上在1天内完成训练,而且在一系列基准测试上实现了最先进的结果。此外,与Qwen-VL [2]不同,后者在训练中包含了内部数据,LLaVA仅利用公开可用的数据。我们希望这些改进并易于复制的基线将为未来的开源LMM研究提供参考。
2.背景
指令跟随的LMM。常见的架构包括一个预训练的视觉主干来编码视觉特征,一个预训练的大型语言模型(LLM)来理解用户指令并产生响应,以及一个视觉-语言跨模态连接器来将视觉编码器的输出与语言模型对齐。如图1所示,LLaVA [28]可能是LMMs的最简单架构。视觉重采样器(例如 Qformer [24])被用来减少视觉补丁的数量[2, 9, 49]。训练一个指令跟随的LMM通常遵循两阶段协议。首先,视觉-语言对齐的预训练阶段利用图像-文本对来将视觉特征与语言模型的单词嵌入空间对齐。早先的工作使用相对较少的图像-文本对(例如~600K [LLaVA 28]或~6M [MiniGPT4 49]),而一些最近的工作在大量的图像-文本对上(例如129M [InstructBLIP 9]和1.4B [千问-VL 2])预训练视觉-语言连接器以用于特定的语言模型,从而最大化LMM的性能。第二,视觉指令调整阶段将模型调整到视觉指令上,使模型能够跟随用户对涉及视觉内容的指令的多样化请求。

多模态指令跟随数据。在自然语言处理(NLP)中,研究表明,指令跟随数据的质量在很大程度上影响了最终指令跟随模型的能力[48]。对于视觉指令微调,LLaVA [28]是第一个利用文本独立的GPT-4来扩展现有的COCO [27]bbox和caption数据集到一个包含三种类型指令跟随数据的多模态指令跟随数据集的先驱:对话式问答,详细描述和复杂推理。LLaVA的流程已被用来扩展到文本理解[45],百万级别[46],以及区域级别的对话[6]。InstructBLIP [9] incorporates学术任务定向的VQA数据集以进一步增强模型的视觉能力。相反,[5]认定这样简单的数据合并可以导致模型倾向于过度拟合VQA数据集,因此无法参与自然对话。作者进一步提出利用LLaVA流程将VQA数据集转换为对话风格。虽然这对训练有效,但它在数据扩展中引入了额外的复杂性。
3.LLaVA的改进
概述。作为视觉指令调整的初始工作,LLaVA已经在视觉推理能力上展示出了令人称赞的熟练技能,甚至在多样化的现实生活视觉指令跟随任务的多样化基准测试中超越了更多近期的模型,只是在通常需要短形答案(例如单个单词)的学术基准上稍显不足。后者归因于LLaVA没有像其他方法一样在大规模数据上进行预训练。在这篇短文中,我们首先研究了数据、模型和图像输入分辨率的规模影响,并在三个选择的数据集上进行验证,结果如表1所示。然后在表2中用最终模型与现有的LMMs在多样化的12组基准测试上进行比较。我们展示了LLaVA的架构对于视觉指令调整是强大且数据高效的,并且比所有其他方法使用显著更少的计算和训练数据就能达到最好的性能。

响应格式提示:我们发现像InstructBLIP[9]这样的方法无法在短篇和长篇视觉问答(VQA)之间达到平衡,主要原因如下。首先,关于响应格式的提示模棱两可。例如,问题:{问题} 回答:{回答}。这样的提示并没有清晰地指出期望的输出格式,甚至可能导致LLM在自然的视觉会话中甚至过度适应短形式的答案。其次,没有对LLM进行微调。InstructBLIP仅对Qformer进行指令调整的微调,使得第一个问题更加严重。它要求Qformer的视觉输出令牌来控制LLM的输出长度是长格式还是短格式,就像prefix tuning[25]一样,但是由于其与像LLaMA这样的LLM相比,只有有限容量,因此Qformer可能没有适当地做这件事的能力。请参见表6以了解一个定性的示例。

为了解决这个问题,我们建议使用一个单一的响应格式提示,清楚地指示输出格式,该提示将在推动简短回答时追加到VQA问题的末尾:“使用一个单词或短语来回答问题”。我们通过实证表明,当用这样的提示进行LLM微调时,LLaVA能够根据用户的指令适当地调整输出格式,并且不需要用chatgpt额外处理VQA数据。这进一步使其能够扩展至各种数据来源。如表1所示,仅通过在训练中包含VQAv2[12],LLaVA在MME上的表现显著提高(1323.8 vs 502.8),并且比InstructBLIP高出111点。
视觉语言连接器的MLP。 受到由线性投影改为MLP[7,8]在自监督学习中改善性能的启发,我们发现,通过将视觉语言连接器的表示能力改进为双层MLP,可以提高LLaVA的多模式能力,相比于原有的线性投影设计。
面向学术任务的数据。我们进一步包括了针对VQA,OCR和区域级感知的附加学术任务导向VQA数据集,如表1所示,以多种方式提升模型的能力。我们首先包括了InstructBLIP使用的四个附加数据集:开放知识VQA(OKVQA[33],A-OKVQA[37])和OCR(OCRVQA[34],TextCaps[39])。A-OKVQA被转化为多选题,使用了特定的响应格式提示:直接使用给定选项的字母来回答。仅使用InstructBLIP使用的数据集的一个子集,LLaVA就已经在表1的所有三项任务中超越了它,这表明LLaVA的有效设计。此外,我们发现,进一步添加区域级别的VQA数据集(Visual Genome[18],RefCOCO[17,32])可以提高模型定位细粒度视觉细节的能力。
额外的扩展。我们进一步放大输入图像分辨率,让LLM能清晰地“看到”图像的细节,并添加GQA数据集作为额外的视觉知识来源。我们还结合ShareGPT[38]数据,并根据[2,6,31]将LLM扩展到13B。在MM-Vet上的结果显示,当将LLM扩展到13B时,它的提升最为显著,这表明了基础LLM在视觉对话中的重要性。我们将所有这些修改后的最终模型称为LLaVA-1.5(在表的最后两行中)。其取得了令人印象深刻的表现,显著超过了原始的LLaVA [28]。
4.讨论
与SoTA的比较。我们在广泛的学术VQA基准测试和最近专门为遵循指令的LMM提出的基准测试上对LLaVA-1.5进行了评估,总共有12项基准测试。我们展示了它在12个基准测试中的11个基准测试上都取得了最佳性能,尽管与其他方法[2,9]相比,它使用的预训练和指令调整数据量小得多。令人鼓舞的是,LLaVA-1.5在最简单的架构,学术计算和公共数据集方面取得了最佳性能,并产生了一个完全可复制和负担得起的未来研究的基线。结果还表明,视觉指令调整在提高LMM能力上更重要,比预训练更为重要,并对普遍的观点产生了疑问,即“LMM需要大量的视觉-语言对齐预训练”[2,9,24],尽管视觉编码器(如CLIP[36],OpenCLIP[16],EVA-CLIP[10]等)已经在网络规模的图像-文本配对数据集上预训练过。LLaVA-1.5(甚至是7B模型)优于80B的IDEFICS[15],一个具有数十亿可训练参数的Flamingo-like LMM。这也使我们在多模态指令跟随能力方面,重新思考了视觉采样器的好处和额外大规模预训练的必要性。

zero-shot格式指令泛化。尽管LLaVA-1.5只使用了有限数量的格式指令进行训练,但它可以泛化到其他指令。首先,VizWiz[13]要求模型在提供的内容不足以回答问题时输出“无法回答”,我们的响应格式提示(表8)有效地指导模型这样做(在无法回答的问题上从11.1%提高到67.8%)。我们还提供了在指导LLaVA-1.5验证棘手问题(图3)和以约束性的JSON格式响应(图4)的定性例子。


zero-shot多语言能力。尽管LLaVA-1.5并未针对多语言多模态指令进行微调,但我们发现,它能够遵循多语言的指令,这部分可能得益于ShareGPT [38]中的多语言语言指令。我们在MMBench-CN [29]上定量评估模型对中文的泛化能力,其中MMBench的问题被转换成中文。值得注意的是,尽管Qwen对中文多模态指令进行了微调,而LLaVA-1.5没有,但LLaVA-1.5的表现仍然超过了Qwen-VL-Chat 7.3%(63.6% vs 56.7%)。
计算成本。对于LLaVA-1.5,我们使用的预训练数据集是LCS-558K1(来自LAION-CC-SBU的约558K图像-文本对的子集,用BLIP打标,这在LLaVA-Lightning系列中被使用。),训练迭代次数和批次大小大致与LLaVA [28]保持一致。由于图像输入分辨率提高到336px,LLaVA-1.5的训练时间大约是LLaVA的2倍:预训练大约需要6小时,视觉指令调整大约需要20小时,使用的是8个A100s。
限制。尽管LLaVA-1.5展示出了有希望的结果,但仍需承认它存在几个限制。首先,LLaVA使用的是全图像块,可能将每次训练迭代拖长。尽管视觉重采样器 [2,9,24] 减少了LLM的视觉块数,但它们当前在相同训练数据量下,无法像LLaVA一样高效地达到收敛,这可能是由于重采样器中的可训练参数更多。有效样本的视觉重采样器的开发可能会为未来指令遵循的多模态模型的扩展铺平道路。
其次,由于缺乏此类指令跟随数据和上下文长度的限制,LLaVA-1.5还无法处理多张图片。第三,尽管LLaVA-1.5显示出了遵循复杂指令的熟练性,但其在某些领域的问题解决能力仍然有限,通过更强大的语言模型和高质量的,针对性的视觉指令调整数据可以得到改进。最后,尽管其产生错觉的倾向显著降低,但LLaVA并非完全不会产生错觉,偶尔还会传播错误信息,在关键应用(如医疗)中应慎重使用。
附录
数据。我们的最终训练数据混合包含了各种数据集:VQA [12, 14, 33, 37], OCR [34, 39], 区域级别的 VQA [17, 18, 32], 视觉对话 [28] 和语言对话 [38] 数据。我们采用了多种策略来降低训练成本和提高效率,详述如下:
- 对于所有的VQA数据集,来自同一训练图片的QA对被合并为一次对话。
- 对于ShareGPT [38],我们过滤掉了无效的对话,就像[41]所做的那样。与Vicuna [41]不同,超过2048个令牌的长对话被截断,而不是分成多个对话。这导致了大约有40K的对话。
- 在A-OKVQA [37]中,每一对QA都被扩充k次,其中k是每个问题的选项数量,以对抗缺乏多选数据的情况。
- 从OCRVQA [34]中抽取了80K的对话。
- 对于VisualGenome,我们为有附加注释的图像抽取了10个注释。
- 对于RefCOCO,对话被分解成片段,每个片段包含少于10个对话。
- 我们观察到语言对话通常比视觉对话长。对于每个批次,我们只从单一模态中抽取对话,这加快了训练速度25%,并且不影响最后的结果。
所有的数据切片都被一起连接,并且以相同的概率进行采样。我们在表7中展示了最终的指令跟踪数据混合的响应格式提示,以及在表8中用于每个评估基准的响应格式提示。

超参数。LLaVA-1.5使用的超参数集合与原始的LLaVA相同,唯一的不同是在预训练中我们将学习率减半,因为我们使用的是MLP投影层而不是原来的线性投影层设计。我们在表5中展示了第一阶段视觉语言对齐预训练和第二阶段视觉指令调整的训练超参数。