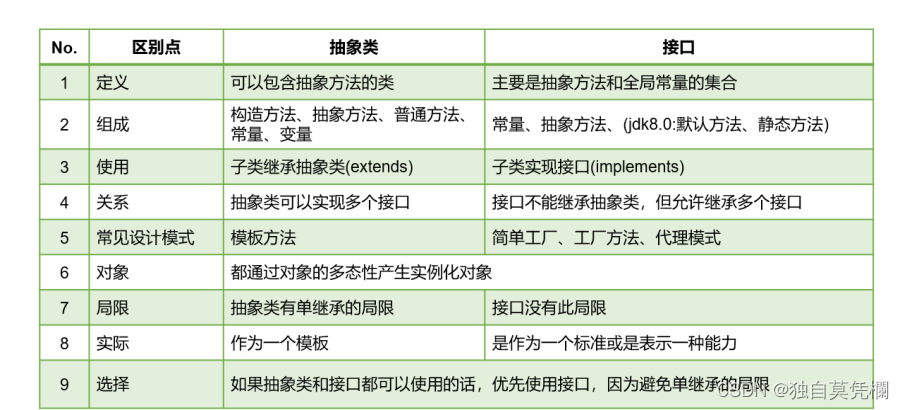
目录
1、动态生成内容
2、使用JavaScript混淆和压缩
3、使用CORS策略
4、检测用户行为
5、利用用户代理标识符
6、图片替代和隐藏字段
7、使用反爬虫服务
在当今的web开发中,JavaScript已经成为了一个不可或缺的部分。然而,这也引发了一个问题,那就是如何防止爬虫程序(如Google Bot或其他搜索引擎的爬虫)从网站中抓取数据。以下是一些关于如何防止JavaScript被爬虫抓取的技巧和策略,以及它们的一些工作原理。

1、动态生成内容
一个常见的防止爬虫抓取数据的方法是使用JavaScript来动态生成内容。这样,只有真正的人类用户才能看到完整的内容,而爬虫程序则只能获取到空白的或者部分的内容。
例如,可以使用AJAX来从服务器获取数据,然后使用JavaScript来将这些数据显示在网页上。这样,如果爬虫程序试图直接抓取网页内容,它就只能获取到HTML代码,而不能获取到实际的数据。
from flask import Flask, render_template
app = Flask(__name__) @app.route('/')
def index(): # 此处从数据库或其他源动态获取数据 data = get_data() return render_template('index.html', data=data)2、使用JavaScript混淆和压缩
另一个防止爬虫抓取数据的方法是使用JavaScript混淆和压缩。混淆是指将JavaScript代码转换成人类难以理解的形式,而压缩则是将JavaScript代码压缩成更小的形式。这使得爬虫程序难以理解和解析JavaScript代码,从而防止它们抓取数据。
from pyminifier import minify_js # 在HTML模板中使用混淆和压缩后的JavaScript代码
template = '''
<script> var compressed_js = {{ compressed_js|safe }}; eval(compress_js);
</script>
''' @app.route('/')
def index(): js_code = ''' function hello() { console.log("Hello, world!"); } ''' minified_js = minify_js(js_code) return render_template('index.html', compress_js=minified_js)3、使用CORS策略
CORS(Cross-Origin Resource Sharing)是一种安全策略,用于防止跨站点的请求被恶意的第三方利用。在这种策略下,服务器可以指定哪些网站可以访问它的资源,而其他的网站则不能访问。这样,如果一个爬虫程序试图从另一个网站抓取数据,它就会被阻止,因为CORS策略会阻止这个网站访问目标服务器的资源。
from flask import Flask, jsonify
from flask_cors import CORS app = Flask(__name__)
CORS(app) @app.route('/data')
def get_data(): # 获取数据,返回JSON响应 data = {'message': 'Hello, world!'} return jsonify(data)4、检测用户行为
最后,可以使用一些JavaScript代码来检测用户行为,以确定访问者是否是爬虫程序。例如,可以检测用户的鼠标移动轨迹、键盘输入、页面加载速度等。如果这些参数与人类用户的典型行为不符,那么很可能是爬虫程序在访问网站。
5、利用用户代理标识符
用户代理标识符(User Agent)是一个HTTP头部字段,它包含了关于浏览器类型、版本以及操作系统等的信息。虽然它不能直接用来防止爬虫抓取数据,但是它可以用来识别和限制某些类型的爬虫。例如,如果发现一个请求来自一个已知的爬虫程序,服务器可以返回一个错误信息或者定制的内容。
from flask import Flask, request, jsonify
import json
app = Flask(__name__) @app.route('/data', methods=['POST'])
def post_data(): # 检测请求头中的User Agent,根据需要定制响应 user_agent = request.headers.get('User-Agent') if 'spider' in user_agent: # 如果User Agent中包含“spider”,返回错误响应 return jsonify({'error': 'Spider detected'}), 4036、图片替代和隐藏字段
对于爬虫的防止,一种常见的方式是使用图片替代敏感信息。例如,可以将用户密码存储在一个图片中,然后使用JavaScript来读取这个图片并将图片中的数据提交给服务器。以下是使用Flask和Pillow库来生成包含密码的图片的示例代码:
from flask import Flask, render_template_string
from PIL import Image, ImageDraw, ImageFont
import io app = Flask(__name__) @app.route('/')
def index(): password = 'mypassword' # 此处为真实的密码 img = create_image(password) img_io = io.BytesIO() img.save(img_io, format='PNG') img_data = img_io.getvalue() return render_template_string('<img src="data:image/png;base64,{}"'.format(base64.b64encode(img_data).decode())) def create_image(password): img = Image.new('RGB', (200, 60), color=(255, 255, 255)) d = ImageDraw.Draw(img) fnt = ImageFont.truetype('/usr/share/fonts/truetype/dejavu/DejaVuSans-Bold.ttf', 15) d.text((10,10), password, font=fnt, fill=(0, 0, 0)) return img对于隐藏字段,可以使用HTML的隐藏表单元素。这些元素通常用于收集用户输入,但在提交表单之前不会显示。可以使用JavaScript来读取和提交这些隐藏字段。以下是使用Flask和HTML来创建隐藏表单的示例代码:
from flask import Flask, render_template
import html app = Flask(__name__) @app.route('/')
def index(): return render_template('hidden.html') @app.route('/submit', methods=['POST'])
def submit(): data = html.unescape(request.form['myHiddenField']) # 解码HTML特殊字符 # 此处处理数据...在HTML文件hidden.html中,应该包含一个隐藏的输入字段:
<!DOCTYPE html>
<html>
<body> <form action="/submit" method="post"> <input type="hidden" name="myHiddenField" value="这里是敏感信息"> <input type="submit" value="Submit"> </form>
</body>
</html>7、使用反爬虫服务
最后,可以使用一些专门为防止爬虫而设计的服务,如reCAPTCHA、Ahrefs等。这些服务通常使用一些特殊的算法和技术来检测访问者是否是爬虫程序,如果是,就会阻止它们抓取数据。虽然这些服务并不是完全可靠的解决方案,但是它们可以作为一种额外的防护措施来使用。
总之,以上就是一些常见的防止JavaScript被爬虫抓取的技巧和策略。当然,这些只是其中的一部分,还有很多其他的方法可以防止爬虫抓取数据。因此,在实际的应用中,需要根据具体的情况来选择最合适的方法来保护自己的网站和数据。