目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据预处理
- 2. 特征提取
- 3. 模型训练及评估
- 1)常规赛预测模型
- 2)季后赛模型创建
- 4. 模型训练准确率
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目使用了从NBA官方网站获得的数据,并运用了支持向量机(SVM)模型来进行NBA常规赛和季后赛结果的预测。此外,项目还引入了相关系数法、随机森林分类法和Lasso方法,以评估不同特征的重要性。最后,使用Python库中的webdriver功能实现了自动发帖,并提供了科学解释来解释比赛预测结果。
首先,项目采集了NBA官方网站上的各种数据,这些数据包括球队与对手的历史表现、球员数据、赛季统计等。这些数据用于构建常规赛或季后赛结果的预测模型。
其次,支持向量机(SVM)模型被用来分析这些数据以进行常规赛或季后赛结果的预测。SVM是一种强大的机器学习算法,可以通过分析数据来确定不同特征对比赛结果的影响。
项目还使用了相关系数法、随机森林分类法和Lasso方法,以评估每个特征对常规赛或季后赛结果的重要性。这有助于识别哪些因素对比赛胜负有更大的影响。
最后,项目利用Python中的webdriver库自动发帖,在开源中国论坛中发布关于比赛预测的帖子。这些帖子不仅提供了预测结果,还附带了科学解释,以便其他球迷能够理解模型如何得出这些预测。这对于NBA球迷和数据科学爱好者来说可能是一个非常有趣的项目,能够帮助他们更好地理解比赛和预测比赛结果。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
系统整体结构如图所示。
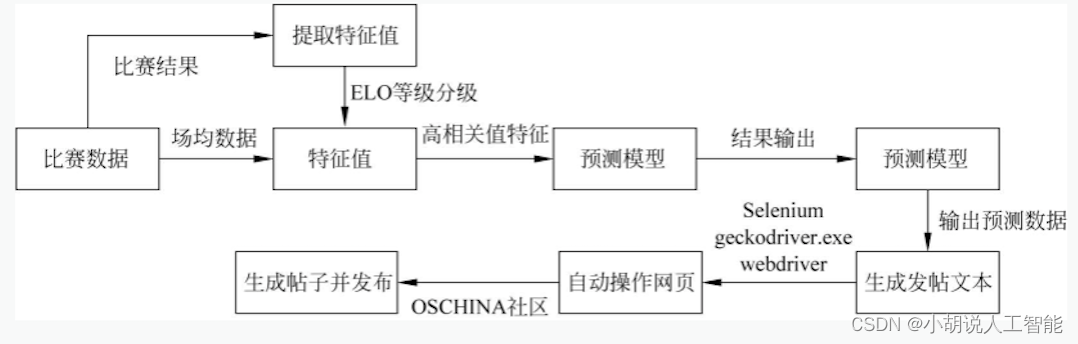
系统流程图
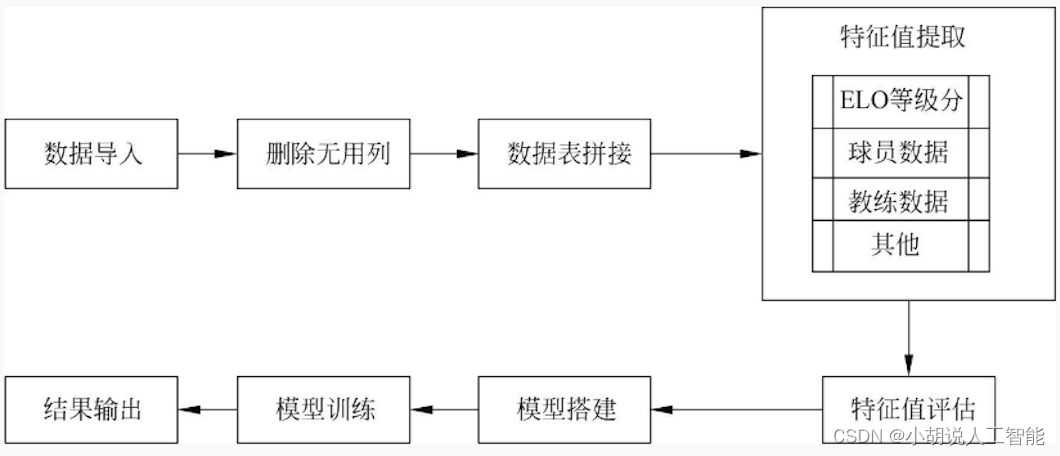
模型处理流程如图所示。
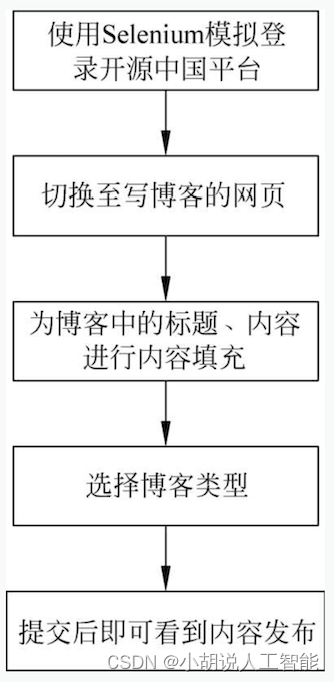
自动发帖流程如图所示。
运行环境
本部分包括Python环境、Jupyter Notebook环境、PyCharm环境和Matlab环境。
详见博客。
模块实现
本项目包括4个模块:数据预处理、特征提取、模型训练及评估、模型训练准确率,下面分别介绍各模块的功能及相关代码。
1. 数据预处理
数据处理分为常规赛和季后赛。
详见博客。
2. 特征提取
本部分包括常规赛特征提取和季后赛特征提取。
详见博客。
3. 模型训练及评估
本部分包括常规赛预测模型和季后赛模型创建。
1)常规赛预测模型
相关代码如下:
#定义预测数据集数组生成函数
def predict_dataset(df):X=[]for index,row in df.iterrows():team1=row['Vteam']team2=row['Hteam']team1_ELO=get_ELO(team1)team2_ELO=get_ELO(team2)feature_team1 = [team1_ELO,0]feature_team2 = [team2_ELO,1]for key,value in team_stats.loc[team1].iteritems():feature_team1.append(value) #不要加赋值语句for key,value in team_stats.loc[team2].iteritems():feature_team2.append(value)X.append(feature_team1+feature_team2)return X
#将18~19赛季比赛日历进行处理
X=predict_dataset(schedule1617)
#form_df函数是将数组转化为数据框的函数
X=form_df(X,z='test')
#删除不显著特征
X=processdf(X)
#产生预测结果
pred_y=model.predict(X)
#产生概率预测结果
pred_y_pro=model.predict_proba(X)
model=DecisionTreeClassifier()
model.fit(X,y)
采用决策树建模,模型参数如下图所示。其中criterion为确定特征选择标准; gini为依据基尼系数进行选择; splitter为确定特征划分标准; best为找出最优的划分点; max_depth为决策树最大深度; min_samples_leaf为叶子节点最少样本数; max_leaf_nodes为最大叶子节点数;class_weight为指定样本各类别的权重,主要是为了防止训练集某些类别的样本过多,导致决策树过于偏向这些类别。由于样本类别分布没有明显的偏倚,选择默认的None, 最后使用model.fit函数进行训练。

2)季后赛模型创建
本部分代码用于生成训练数据,调用sklearn中的SVM分类器进行拟合。
#引用库
import pandas as pd
import glob
import random
from sklearn import svm
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
#读入球队特征数据
team_stats = pd.read_csv('data_final.csv')
#根据比赛形成训练用的数据
def data_form(stringa, z='train'):X = []y = []for fname in glob.glob(stringa):result_data = pd.read_excel(fname)result_data.replace(['New Orleans Hornets', 'Charlotte Bobcats'], ['New Orleans Pelicans', 'Charlotte Hornets'],inplace=True)#标记数据赛季year = result_data['Yr'][0]season = year - 2000 + (year - 2001) * 100#print(season)for index, row in result_data.iterrows():Wteam = row['Teamw']Lteam = row['Teaml']#print(Wteam)aw = team_stats[(team_stats['Team'] == Wteam) & (team_stats['season'] == season)]bw = aw.drop(['season', 'Team'], axis=1)team1_features = bw.valuesal = team_stats[(team_stats['Team'] == Lteam) & (team_stats['season'] == season)]bl = al.drop(['season', 'Team'], axis=1)team2_features = bl.values#训练集随即划分左右,左边的特征减右边的特征,赢标记为1,输标记为0if z == 'train':if random.random() < 0.5:feature = team1_features - team2_featuresX.extend(feature.tolist())y.append(1)else:feature = team2_features - team1_featuresX.extend(feature.tolist())y.append(0)else:feature = team1_features - team2_featuresX.extend(feature.tolist())y.append(1)return X, y
#生成训练集10~11赛季至17~18赛季
fname1 = 'data/playoff/*playoff.xlsx'
X, y, = data_form(fname1)
SVC分类器使用“sigmoid”核函数,惩罚系数为1
#调用SKlearn svm
model = svm.SVC(kernel='sigmoid', C=1)
model.fit(X, y)
4. 模型训练准确率
常规赛使用决策树模型,准确率如下:
model.score(X, y)
计算结果为0.99924012158054709。
使用十折交叉验证,准确率如下:
cross_val_score(model, X, y, cv= 10, scoring='accuracy', n_jobs=-1).mean()
计算结果为0.61396768625776255。
季后赛十折交叉验证的准确率如下:
cross_val_score(node1, X, y, cv= 10, scoring ='accuracy', n_jobs=-1).mean()
计算结果为0.516666666666676。
相关其它博客
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(一)
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(二)
基于SVM+Webdriver的智能NBA常规赛与季后赛结果预测系统——机器学习算法应用(含python、ipynb工程源码)+所有数据集(四)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。