目录
一、进程创建
写时拷贝
二、进程终止
echo $?
如何终止进程
_exit与exit
三、进程等待
进程等待的必要性
进程等待的操作
wait
waitpid
status
异常退出情况
status相关宏
options
四、进程程序替换
1、关于进程程序替换
2、如何进行进程程序替换
程序替换函数
execl
execv
execlp
execvp
Makefile(补充)
命令行参数(补充)
execle
execvpe
execve
简易的shell编写
一、进程创建
当一个进程调用fork后,就会创建出一个新进程,新进程是子进程,原来的进程是父进程,但是却可能执行不同的代码:

运行结果:
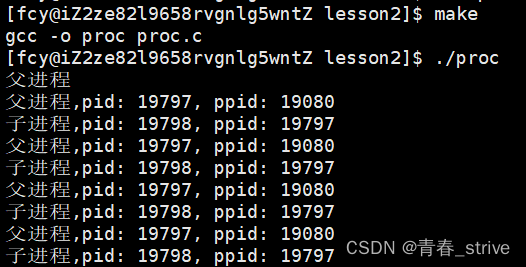
上面的结果可以充分证明父子进程执行不同代码的事实,id值==0的就是子进程,id值>0(即返回子进程的pid)的是父进程
结合地址空间的知识,一个父进程,一个子进程,各自都有地址空间,都有页表,所以用的虚拟地址相同,而物理内存其实是被映射到不同区域的,所以同一个变量id会有两个不同的值,所以父子进程会执行不同的代码
写时拷贝
父子进程的代码通常是共享的,父子进程不写入时,数据也是共享的,而当任意一方试图写入的时候,便以写时拷贝的方式再拷贝一份出来。
下面就是OS为何选择写时拷贝的原因:
1、OS在代码执行前,无法预知哪些空间会被访问
2、在用的时候再分配是高效使用内存的表现,是一种延时申请的技术
正是有写时拷贝技术的存在,所以父子进程得以彻底的分离,保证了进程的独立性
二、进程终止
首先在进程终止时,操作系统会释放进程申请的相关内核数据结构(PCB结构体、页表...)、对应的数据和代码
其实就是操作系统会释放系统资源
进程终止有如下三种方式:
1、代码执行完,结果正确
2、代码执行完,结果不正确
3、代码没有执行完,程序崩溃(涉及信号,后面会说到)
我们平常所写的main函数,最后一行都是return 0,这个0是什么?这个返回值的意义是什么?必须要是0吗?其他值比如5可以吗?
其实这里的0是进程退出码,返回值如果是0就说明是成功运行且结果正确,而如果是非0则说明运行的结果是不正确的
而这里的非0值是有无数个的,不同的非0值就可以表示不同的错误原因,这样就可以在我们的程序运行结束后,如果结果不正确,就能清楚的知道错误的原因
main函数返回值的意义是返回给上一级进程,用于判断进程执行结果对还是不对
下面的代码可以看出来,return 5也是可以的,不一定是0
echo $?
echo $?可以获得最近一个进程执行完毕的退出码
运行结果:
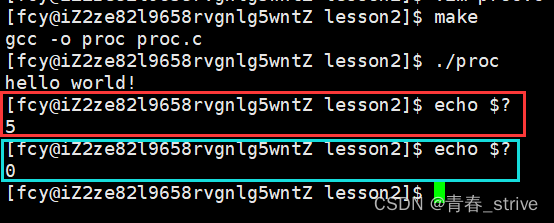
可以看到,第一次执行echo $?时,打印出来的就是我们main函数中写的退出码5
第二次执行echo $?时,打印出来的退出码是0,是因为当第二次执行echo $?时,最近一次执行完毕的进程就是上一次的echo $?,而上一次的echo $?执行成功,所以退出码是0
下面举个退出码验证结果的例子:

我们使用退出码验证结果是否正确,从1加到3结果应该是6,所以判断一下如果结果不等于6,则改变退出码ret变为1,否则就是正常返回0

可以看到正常运行结束,echo $?查看退出码为0,说明结果正确
下面改变一些,将for循环的判断语句变化一下:
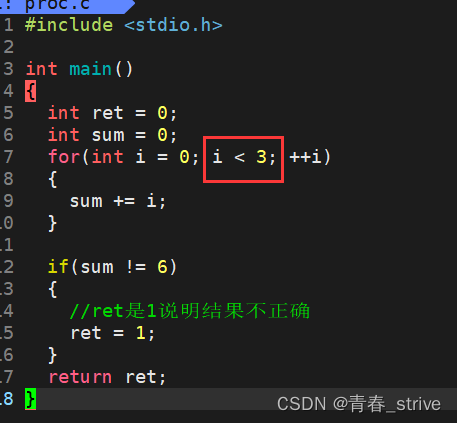
这时运行完再观察退出码:

这时的退出码就不是0了,变为了1,说明运行结果不正确
下面可以看看正常情况下,非0值表示的什么意思
其中strerror就是将一个整数转化成字符串描述,所以可以查看每一个非0值表示的意义

结果为:

每一个非0值后面就表示它所代表的错误信息
下面举个例子:
我们平时ls打印文件信息,如果ls后面的文件不存在,就会报这样的错误提示:
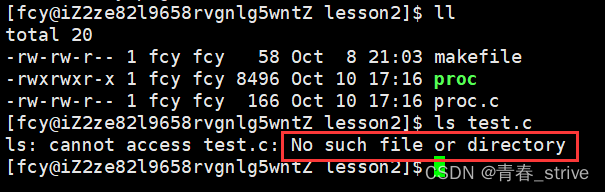
而我们刚刚打印出来的退出码的含义,其中2后面对应的错误信息就是这个,所以我们执行一下echo $?,打印一下最近一次进程的退出码,即ls test.c这个进程的退出码
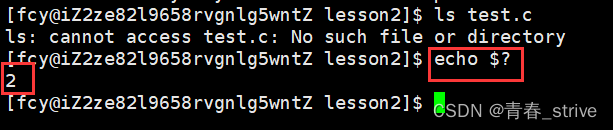
通过结果可以看到,退出码就是2
还需要注意的是,如果进程终止是第三个情况,程序崩溃而终止,这时的退出码无意义,这种情况一般都是退出码对应的return语句没有被执行
如何终止进程
①main函数中return
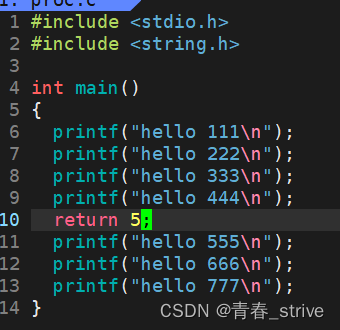
在main函数中,直接return,运行结果为:
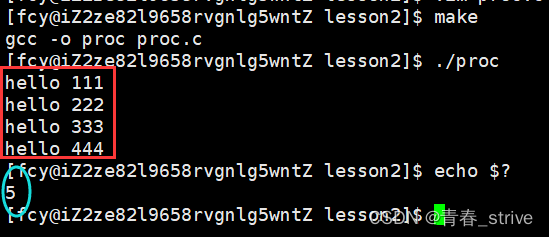
执行到return语句前面就终止了,并且查看退出码也是5,结果正确
②exit
需要包头文件stdlib.h
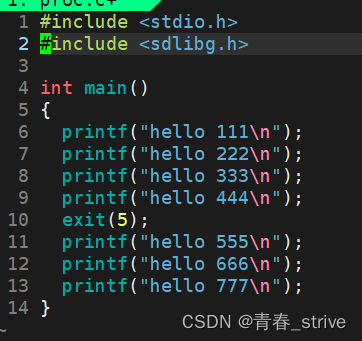
运行结果即退出码如下:

可以看到,与return的结果相同
return和exit的区别
①return是语句,而exit是函数
②exit在任何地方调用都表示直接终止进程
而return在普通函数中表示函数调用结束,在main函数中才代表进程退出
如下所示:

运行后,查看退出码:

可以发现退出码并不是调用的add函数中的return值,而是main函数中的return值
下面看exit的情况:

运行后查看退出吗:

可以发现,在调用add函数中,最后的exit(10),而退出码也是10,说明exit在任何地方调用都表示直接终止进程
_exit与exit
正常情况下,区别不大,下面举个缓冲区的例子:

正常情况下,由于我们的hello后面没有\n换行,所以程序是将hello先放到缓冲区中,去执行后面的sleep(2)和exit(5),这时看下面的结果:

exit会在终止进程前,从缓冲区中读出hello,然后再终止
下面观察_exit的情况:
结果为:

我们可以发现,如果是_exit,终止进程前并没有打印出缓冲区的内容
所以exit与_exit的显著区别就是:
exit终止进程前,会执行用户清理函数,打印缓冲区的内容,关闭流...
_exit则直接终止进程
所以上面的代码,exit等看到打印的结果,而_exit则看不到结果
三、进程等待
进程等待的必要性
父进程创建出子进程,是要子进程完成任务的,那么子进程是否完成,又该如何处理,是进程等待需要做的
如果子进程结束,父进程不管子进程,就可能会造成僵尸进程,造成内存泄漏的问题
因此通过进程等待可以回收子进程资源,获取子进程退出信息
进程等待的操作
wait
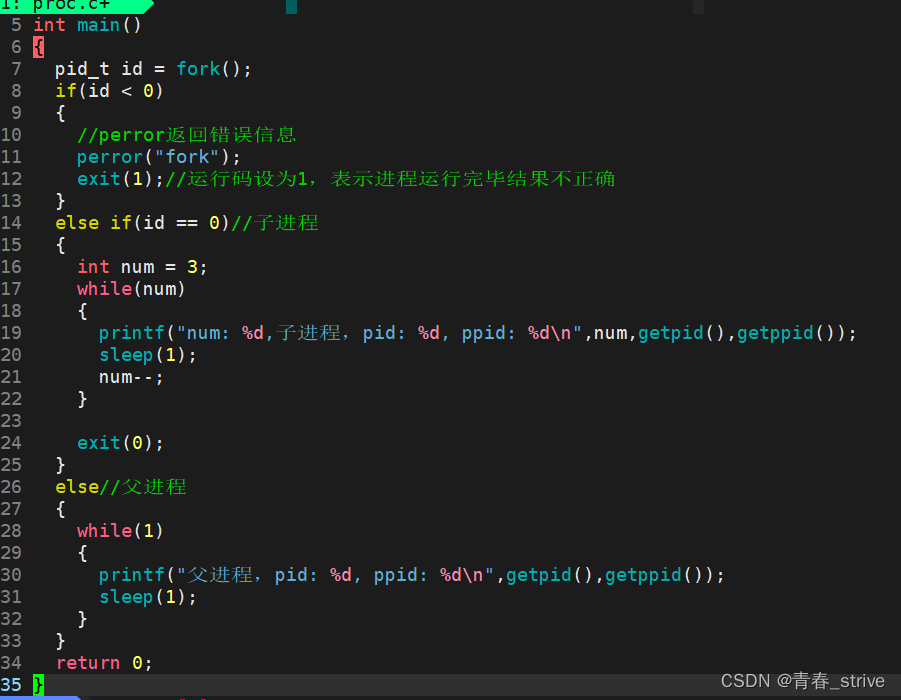
首先运行fork函数,创建出子进程,并且子进程执行三次就退出,而父进程继续执行
还没运行可执行程序proc时,用ps指令查看进程,发现只有grep进程,因为我们在执行这个命令

然后复制SSH渠道,变为两个窗口,方便我们观察进程状态:

右边窗口执行,左边观察:

可以发现,在刚开始运行时,子进程还没有终止时,进程状态是S,而子进程运行三次终止后,只剩父进程执行时,再观察进程信息,可以看到子进程的进程状态变为了Z,即僵尸状态,后面也有defunct表示它是无效的
接着man 2 wait了解一下wait

wait的返回值:成功就返回子进程的pid,失败了就返回-1
下面改变父进程的else中的语句
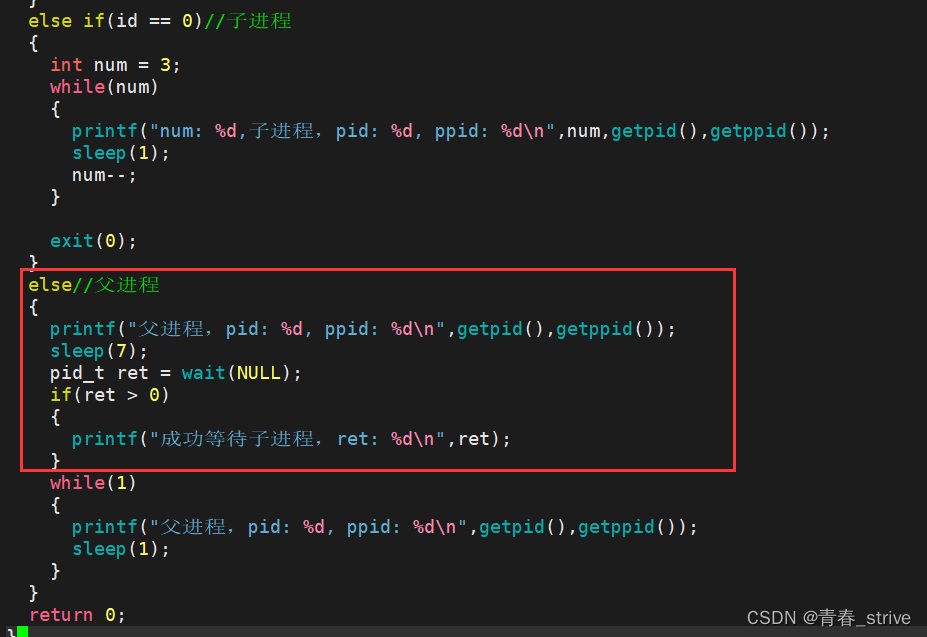
先执行一次父进程的printf语句,然后sleep7秒,由于子进程执行每次循环都sleep1秒,执行三次就退出,所以三秒后子进程就是僵尸进程
我们设置父进程sleep7秒再执行下面的代码,前三秒父子进程都正常,三秒后子进程变成僵尸进程,7秒后父进程执行wait,就可以清楚观察到子进程变成僵尸进程后,父进程执行wait,所造成的结果是什么
结果如下:

一共用ps指令查看了三次,第一次是子进程还没有执行完三次,父子进程正常运行
第二次是子进程执行完三次已经退出,而父进程还在sleep,没有执行wait的进程状态
第三次是父进程执行完wait的进程状态
上面左边窗口的图放大:

可以看到第一次pid为25490的子进程的进程状态是S,父子进程正常运行
第二次pid为25490的子进程的进程状态为Z,子进程已经退出进程,变为僵尸进程,父进程正常运行
第三次父进程执行完wait后,可以发现pid为25490的子进程已经被父进程回收,所以进程列表看不见pid为25490的子进程了
上面就是执行完wait后的情况,所以之后编写多进程,都会使用fork + wait/waitpid
waitpid
同样用man看一下waitpid的信息:

同样包含在头文件sys/types.h和sys/wait.h中
注意看上面的第二个框中的内容:waitpid有三个参数
第一个参数pid:
当 pid == -1时,等待任一子进程,与wait等效
当pid > 0时,等待其进程id与pid相等的子进程
第三个参数options:
默认为0,表示阻塞等待
第二个参数status:
status是一个输出型参数,我们通过waitpid获得子进程的退出结果,想用status来标识子进程退出的结果是什么,如果不关心可以为NULL
所以使用waitpid时,waitpid(pid, NULL, 0) 与 wait(NULL)等价
waitpid的返回值pid_t
大于0表示等待子进程成功,子进程退出
小于0表示等待子进程失败
等于0表示等待子进程成功,子进程未退出
下面将使用wait时的代码,做以改变,将wait改为waitpid

其中框住的部分,第三个参数为0,是父进程默认在阻塞状态去等待子进程状态变化,即等待子进程退出
和上面处理一样,两个窗口方便观察进程状态

左边窗口观察结果:

与wait一样,刚开始父子进程正常执行时都是S,子进程执行完毕退出,状态变为Z,即僵尸进程,然后父进程执行waitpid,回收子进程资源,僵尸进程被回收
用waitpid也完成了进程等待,这就是回收僵尸进程的两种方法wait、waitpid
status
下面详细说下status,就status的构成来说,status不是按照整数来整体使用的,而是按照比特位的方式,将32位进行划分,我们只学习低16位
而这低16位中,次低的8位,表示的是进程的退出码,所以如果想打印出子进程退出码,需要将status的先右移8位,将次低的8位移到低位的8位,然后按位与0xFF,就可以得到这低16位中次低8位的值,即进程的退出码

可以看到子进程中我们设置的退出码是10,这时运行代码:

可以得到子进程的退出码
所以父进程就可以通过子进程的退出码是0还是非0,来确定子进程运行有没有成功,结果是否正确,如果失败,错误码是什么,表示什么原因失败的
进程终止的情况三是进程异常退出,或是崩溃,其实本质就是操作系统杀掉了进程
操作系统是通过发送信号的方式杀掉进程
而我们上面说到进程退出码是status的次低8位比特位,而终止信号则是最低7个比特位,倒数第八个比特位是core dump标志(gdb调试崩溃信息时,在信号部分详解)
信号有以下这些,通过kill -l查看:

我们只需要关注前31个普通信号,其中第9个我们曾经还用于终止进程
所以这时我们还可以看到子进程收到的信号编号,在代码中再加以改进:

代码中加了红框框起来的,由于最低7位是终止信号,所以status与0x7F按位与得到的就是最低7位的值,0x7F即0000......0111 1111,四个二进制位表示一个16进制位,后七位即7F
打印结果为:
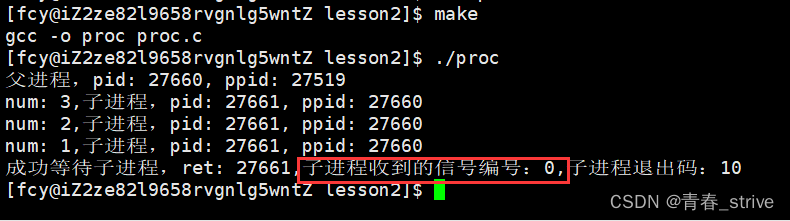
子进程收到的信号编号为0,说明进程是正常跑完的
子进程的退出码是10,说明结果是正确的
异常退出情况
接下来,尝试一下异常情况,子进程直接崩溃,即一个数除0时,观察子进程的信号编号情况:

观察下面结果:
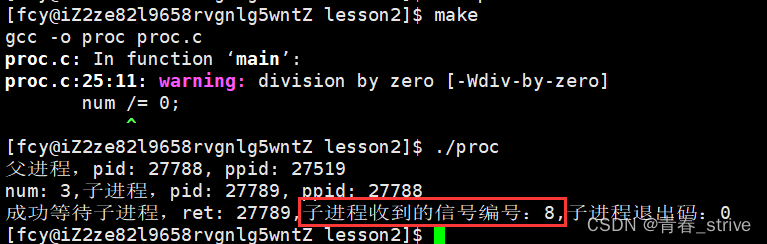
编译时给了一个警告warning,分母不能为0,但不是报错依然可以运行,在子进程循环第一次的时候,就终止程序了,程序崩溃,可以看到报的信号编号为8
这时子进程收到的信号编号为8,不为0,表示不正常,进程崩溃了,这时的退出码0无意义
而信号编号8则可以看上面的kill -l打印的信号列表,即SIGFPE,表示浮点数错误
下面试一下野指针的情况:

指针pa指向空,再改变pa的值,即野指针问题
结果为:

子进程收到的信号编号为11,不为0,同样表示不正常,进程崩溃了,这时的退出码0同样无意义
信号编号11则可以看上面的kill -l打印的信号列表,即SIGSEGV,即段错误
程序异常不仅仅是内部代码有问题,也可能是外力造成的:

我们将子进程while循环的num不--,就会导致子进程死循环,这时父进程等不到子进程结束,于是使用外力kill,直接杀掉进程,如下:

子进程pid是28223,所以直接输入kill -9 28223,相当于直接杀死进程,这时的信号编号是9,即我们经常用到的SIGKILL
而kill杀掉了进程,子进程代码无法确定是否运行完毕,所以退出码同样没有任何意义
status相关宏
我们其实不用每次都是使用这种按位与或者右移再按位与的方法,对status进行二进制处理,系统中给我们提供了宏:
WIFEXITED(status):若正常终止子进程,则为真(检测是否正常退出)
WEXITSTATUS(status):若WIFEXITED为真,则提取子进程退出码(查看子进程退出码)
所以上面代码中可以不用进行二进制处理,可以用以下方式:
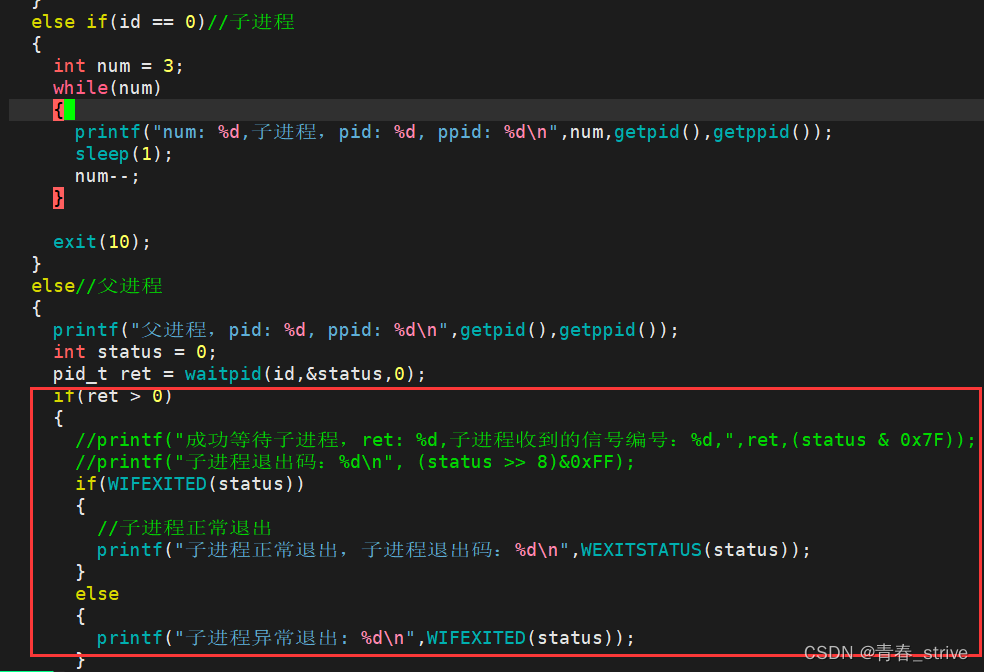
使用宏处理,运行结果为:
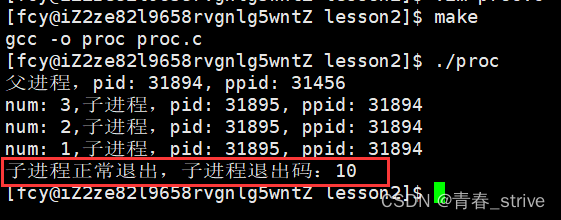
可以正确得到子进程退出码
若是异常退出,则为假,返回值为0
经过上面知识的铺垫,我们就可以理解,父进程通过wait/waitpid拿到子进程的退出结果,而不用全局变量,是因为进程是具有独立性的,改变数据时会发生写时拷贝,父进程是无法拿到的,并且还有上面说到的子进程的信号编号通过全局变量也是无法做到的
并且还有一个问题,进程是具有独立性的,那子进程退出了,子进程的退出码也是子进程的数据,父进程为什么可以拿到,其中的wait/waitpid是怎么做到的?
其实很简单,在子进程变为僵尸进程后,父进程回收子进程资源,其中子进程的PCB结构体是保留下来的,而这个PCB结构体中是保留了子进程的退出结果信息的,而wait/waitpid就是系统调用接口,相当于操作系统,所以是有权限调用PCB结构体中的信息的,所以本质其实就是父进程通过wait/waitpid系统调用接口,读取了子进程的PCB结构体里的信息,因此父进程可以拿到子进程的退出码就可以很好地解释了
options
options是waitpid的第三个参数,默认为0,代表阻塞等待
WNOHANG选项:代表父进程非阻塞等待
这里的WNOHANG,其实就是Wait No HANG(夯住了)
夯住了本质就是这个进程没有被调度,也就是要么是在阻塞队列中,要么是等待被调度
那么WNOHANG(Wait No HANG)就是不被夯住,也就是非阻塞等待
之前的阻塞等待时,子进程如果没有运行结束,父进程是会一直等待子进程运行结束的,而现在的非阻塞等待,改变代码如下:
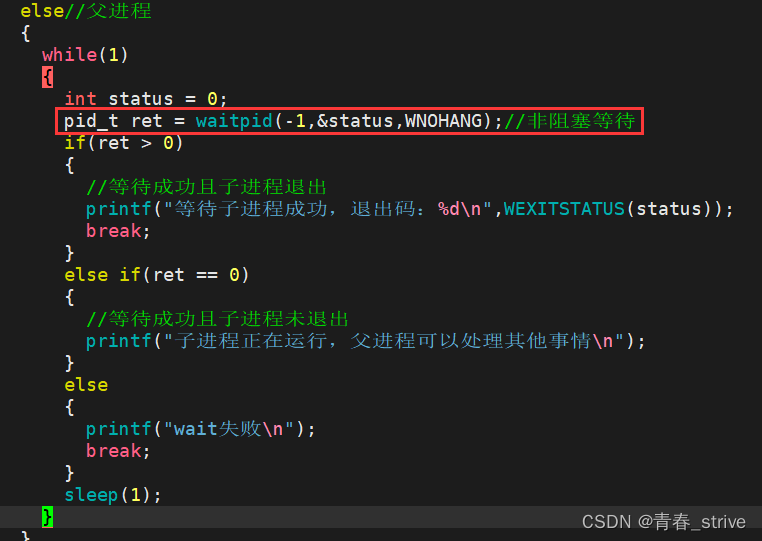
进行非阻塞等待运行结果如下:

观察结果可知,非阻塞等待中,在子进程还没有退出时,父进程不像阻塞等待那样什么都不干,父进程是可以边执行任务边等待子进程的
四、进程程序替换
1、关于进程程序替换
前面说到fork()后,父子会各自执行父进程代码的部分,父子代码共享,数据写时拷贝,那么子进程想执行一个全新的程序时,就要引入进程程序替换的概念了
程序替换是通过特定的的接口,加载磁盘上全新的程序(代码+数据),进而加载到调用程序的地址空间中,从而让子进程执行其他程序
而进程替换这个过程,原本的PCB结构体、地址空间等内核数据结构都不发生改变,只是将新的磁盘上的程序加载到内存中,并和当前进程的页表建立映射关系即可,所以进程替换并没有创建新的子进程
而程序替换的原因就是是和应用场景有关的,有时候我们必须要程序替换
exec*函数的本质,就是如何加载程序的函数
2、如何进行进程程序替换
首先看下面的简单例子:

这是一个很简单的程序,运行结果:
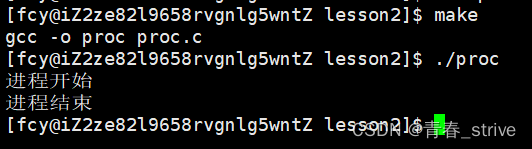
程序替换函数
execl
接下来调用execl函数,先用man查看一下execl
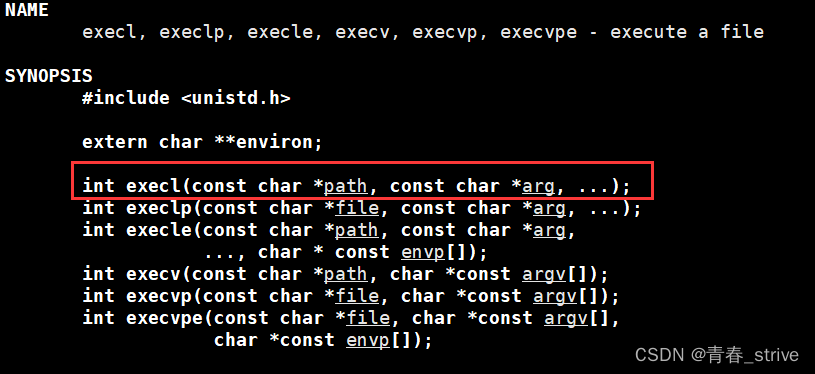
execl的参数解释一下:
第一个参数path,是路径+目标文件名
第二个参数arg及后面的...,我们在Linux命令行上怎么填,就在这里怎么填,最后一个必须是NULL,表示参数传递完毕
参数最后的...表示可变参数列表,即可以传入多个不定个数的参数
具体见下面例子,以ls举例:

使用which查看,ls路径是/usr/bin/ls,所以在代码做以修改:

execl第一个参数传入ls的路径,第二个参数及后面的参数按命令行的写法顺序写入,即"ls","--color=auto","-a","-l",最后以NULL结尾,其中"--color=auto"是ls打印时所带的颜色
然后运行程序,再运行ls -a -l对比

可以发现结果是一样的
另外,在使用函数execl之前,打印了 进程开始 和 进程结束 ,但是执行execl后,没有打印进程结束了
这是因为,execl是程序替换,在调用该函数成功后,会将当前进程的所有代码和数据都进行替换,其中包括已经执行的和没有执行的
所以一旦调用成功,后续代码都不会执行
根据这个性质,我们可以得到execl不需要的返回值的理由,如果有返回值,调用成功的时候会将当前进程所有代码都替换,包括返回值,这时的返回值无意义
如果调用失败,我们只需要在execl下面写exit即可,这样成功了不会执行exit,失败才执行
如下面的例子,path里传入一个完全不对的路径,在下面加上exit(6):

这时编译再运行:

这时调用失败,就不会再执行下面的代码了,并且查看退出码是我们设置的6
上面进程替换的例子是不创建子进程时的例子,下面都是在创建子进程的前提下的例子:
而我们创建子进程的原因:
创建子进程是为了不会影响父进程,我们需要父进程执行读取数据、解析数据、指派进程执行的功能,如果在进程替换时不创建子进程,那么替换的就是父进程,所以需要创建子进程
execv

execl函数以l结尾,可以看做list,我们需要将参数一个一个传入
而execv函数以v结尾,可以看做vector,我们则需要将所用参数传入一个指针数组argv中,然后将argv当做参数传入execv函数中
所以execl与execv只是在传参方式上有区别
下面是execv的例子:
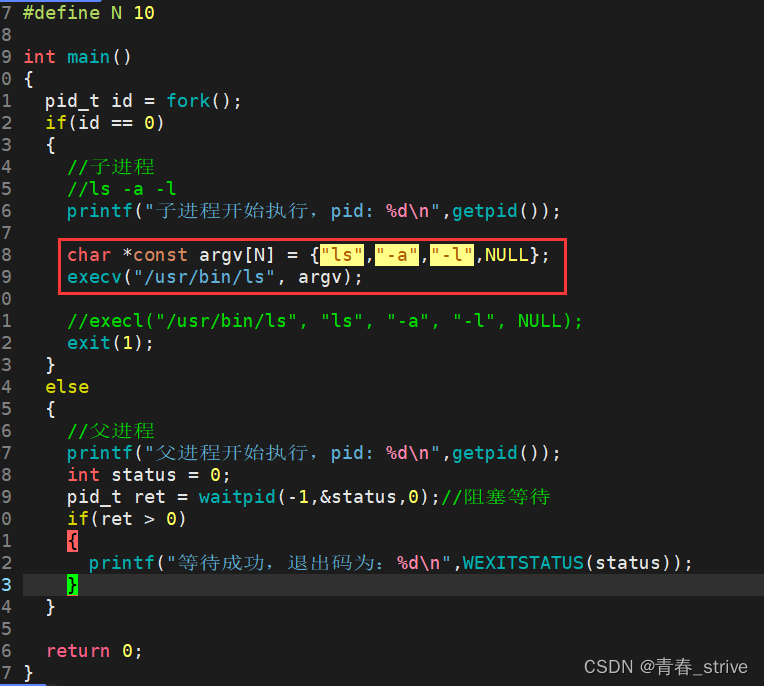
执行结果:

所以execl与execv的功能是一样的
execlp
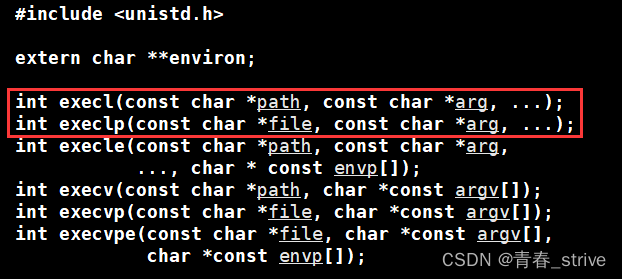
通过观察,execlp和execl的第一个参数,一个是path,一个参数是file
这个execlp函数,结尾是p,可以看做它会自己在环境变量PATH中进行查找,不需要告诉它要执行的程序的路径
所以将上面的程序做以改变:

运行结果:

同样执行成功
这里需要注意,看下图:

这里两个ls并不是两次无意义的重复
第一个ls是找到程序
第二个ls及之后的内容表示,找到程序后要执行什么选项
execvp
同样通过man查看:

这里的execvp与execlp都是以p结尾,所以也不需要带路径
并且第二个参数与execv相同,所以就不用多说,直接看用法:
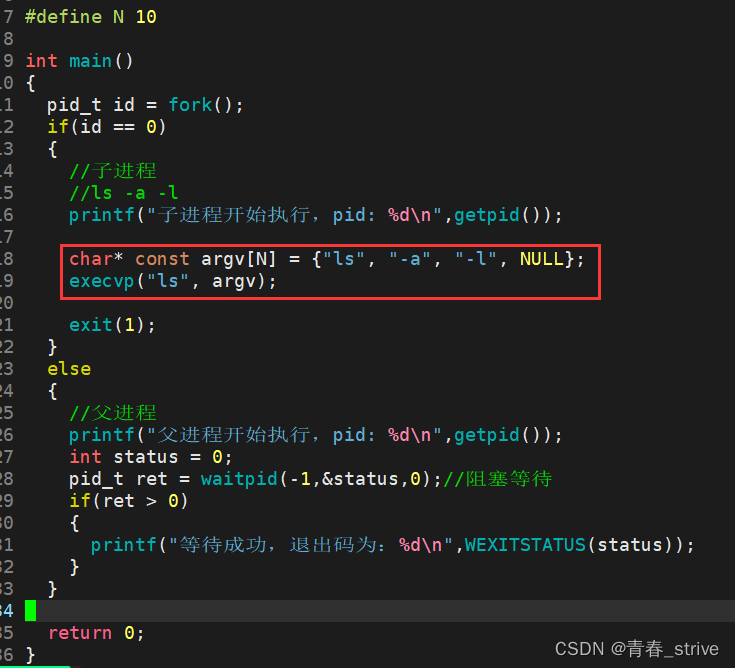
运行结果为:
同样执行成功
Makefile(补充)
如果我们当前文件夹中,有两个文件,Makefile如何书写,可以做到make时生成两个可执行,如下所示:

我们当前有两个文件exec.c和test.c,Makefile改变如下:

这时当Makefile从上往下被扫描时,需要生成的目标文件第一个遇到的就是all,而all依赖的是exec和test,所以就会往下扫描,将exec与test的可执行程序执行完,all的依赖条件具备后,想执行all的依赖方法,发现all没有依赖方法,所以Makefile就结束了,在clean中也删除两个可执行文件
以后如果还想make生成更多的可执行文件,只需在all后面,空格为间隔继续跟即可
这时执行make,就可以生成两个可执行程序:

make clean也可以清理两个可执行程序:

上面创建的test.c代码如下:
命令行参数(补充)

main函数后面的参数argc、argv叫做命令行参数,因为我们生成的可执行程序是test,假设执行的操作是test -a或test -b
所以这里的第一个参数argc是2,表示test是一个,-a或-b是第二个
argv[0]就是test,argv[1]就是-a或-b
因此第一个if语句就是与argc有关,判断是否为2,为2再往下执行,不为2直接exit退出进程
下面的else if语句则检测输入的选项是否是-a或-b或其他
我们的test.c程序写好了,那么如何在exec.c中,让子进程执行我自己写的C/C++代码,例如让exec的子进程执行test.c:
(里面的/home/fcy/lesson3/test是绝对路径的表示,也可以使用相对路径表示,即./test)

使用execl第一参数传入可执行程序test的路径,第二个参数及后面的参数,按命令行的形式填入,即test -a,这时结果为:

成功在exec可执行程序中执行我们自己写的代码test.c的可执行程序
如果改变为:

则结果为:
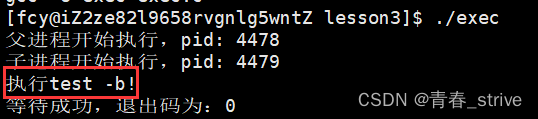
而如果出现test中并未提及的选项,比如-d,如下:

则会进入else,打印失败

execle
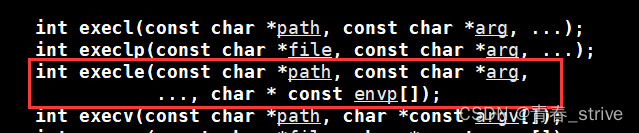
这里的execle比上面说到过的execl多了一个e,这里的e可以看做环境变量
所以使用execle就可以向目标进程传递环境变量
我们想要在exec的子进程中调用test,所以在test中实现我们自己的环境变量MY_VAR,之后由exec的子进程调用即可
由execle的第三个参数类型可以看出,传入的环境变量类型也是一个指针数组:

所以在exec.c中自己创建一个环境变量MY_VAR,在指针数组env中,接着在子进程中调用execle函数,最后一个参数传入env,第一个参数中的路径是可执行程序test
下面是test.c中代码:
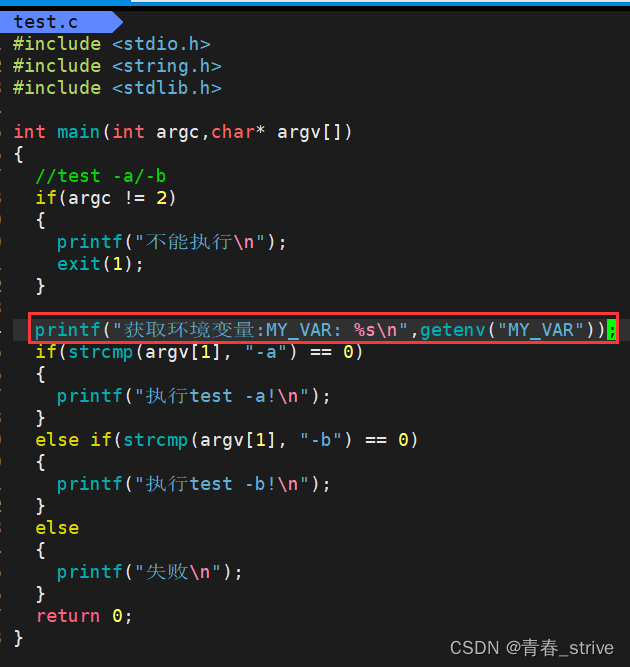
执行结果为:

得到了我们自己创建的环境变量MY_VAR
此时exec里面的环境变量MY_VAR就传递给了test
所以到这里就可以明白,之前说到过的环境变量可以被子进程继承,具有全局属性的原因,main函数的命令行参数三个分别是:int argc, char* argv[], char* env[],其中第三个参数env就是环境变量,所以在子进程执行execle时,最后一个参数传入env,就可以继承父进程的环境变量
execvpe
还有最后一个execvpe没有说到:
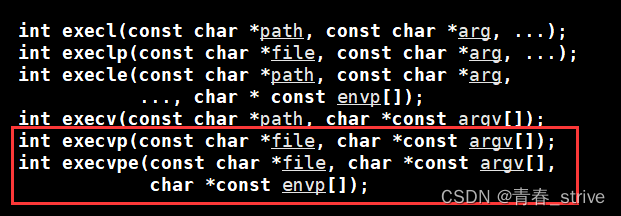
经过上面的例子,可以非常清楚看到execvpe就只是比execvp多了一个环境变量参数,这个参数的用法具体参照execle,就不具体说明了
execve
首先通过man查看execve,如下:
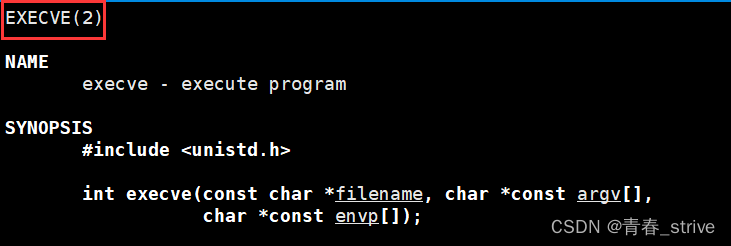
而上面的六种exec*函数通过man查看:

可以发现,execve是2号,即系统调用,而上面的六个函数都是3号,是系统提供的基本封装
也可以说上面六个的函数底层就是execve,传入数据根据不同的情况传入这几种不同的函数中,然后经过处理变为execve的三个参数,最终调用的都是execve
之所以提供这些封装,就是因为我们遇到的场景不一样,为了满足这些不同的调用场景
最后再看execve的参数:

经过前面几种函数的学习,可以很容易明白含义:
第一个参数,就是传入详细的路径
第二个参数,即将所有参数放入指针数组中,然后以指针数组的形式传入
第三个参数,即传入环境变量
进程程序替换的exec*函数涉及的知识结束
简易的shell编写
具体实现的细节都在代码中详细注释了
1 #include <stdio.h> 2 #include <stdlib.h>3 #include <unistd.h>4 #include <sys/wait.h>5 #include <string.h>6 #include <sys/types.h>7 8 #define N 309 #define SIZE 2010 //保存完整的命令行字符串11 char my_cmd[N];12 //保存打散后的命令行字符串 13 char* _argv[SIZE];14 15 int main()16 {17 //命令行解释器,不退出,执行死循环while(1)18 while(1)19 {20 //1. 打印想Linux命令一样的提示信息21 printf("[root@local myshell]# ");22 //由于printf后面没有'\n',所以内容都在缓冲区23 //fflush(stdout)就是取出缓冲区的内容24 fflush(stdout);25 //将my_cmd内容初始化为'\0'26 memset(my_cmd,'\0',sizeof my_cmd);27 //2. 获取用户键盘输入的指令和选项28 if(fgets(my_cmd, sizeof my_cmd, stdin) == NULL)29 {30 //如果输入错误,重新输入31 continue;32 }33 //由于用户输入完指令和选项会按回车即'\n',多换一行34 //所以将用户输入的最后一个字符'\n'替换成'\0'35 //即"ls -a -l\n\0" 变为 "ls -a -l\0\0"36 my_cmd[strlen(my_cmd)-1] = '\0';37 //3. 命令行字符串解析38 //即"ls -a -l" -> "ls" "-a" "-l"39 //strtok用于打散空格隔开的字符串40 //第一次调用,要传入原始字符串41 _argv[0] = strtok(my_cmd, " ");42 int num = 1;43 //给ls执行后的结果带上颜色44 if(strcmp(_argv[0], "ls") == 0)45 {46 _argv[num++] = "--color=auto";47 }48 //循环直到字符串遍历完毕49 //第二次调用strtok如果还是解析原字符串,传入NULL50 while(_argv[num++] = strtok(NULL, " "));51 //4. 如果是切换路径的命令cd,就不能在子进程中执行52 //因为子进程被替换后会exit退出,再次回到循环最开始的地方53 //路径并没有发生改变,所以这种需要父进程执行的就是内置命令54 //内置命令的本质就是shell的一个函数调用55 if(strcmp(_argv[0], "cd") == 0)56 { 57 //如果cd后面有命令,则调用函数chdir改变路径,然后continue58 if(_argv[1] != NULL)59 {60 chdir(_argv[1]);61 }62 continue;63 }64 //5. fork()创建子进程65 pid_t id = fork();66 if(id == 0)67 {68 //子进程69 printf("子进程执行下面的功能\n");70 execvp(_argv[0],_argv);71 exit(1);72 }73 //父进程74 int status = 0;75 pid_t ret = waitpid(id, &status, 0);//阻塞等待76 if(ret > 0)77 printf("进程退出码:%d\n",WEXITSTATUS(status));78 79 }80 return 0;81 }实际执行的和我们命令行上的操作基本类似,底层使我们自己刚刚模拟实现的简易的shell,能够执行简单的指令,如下:
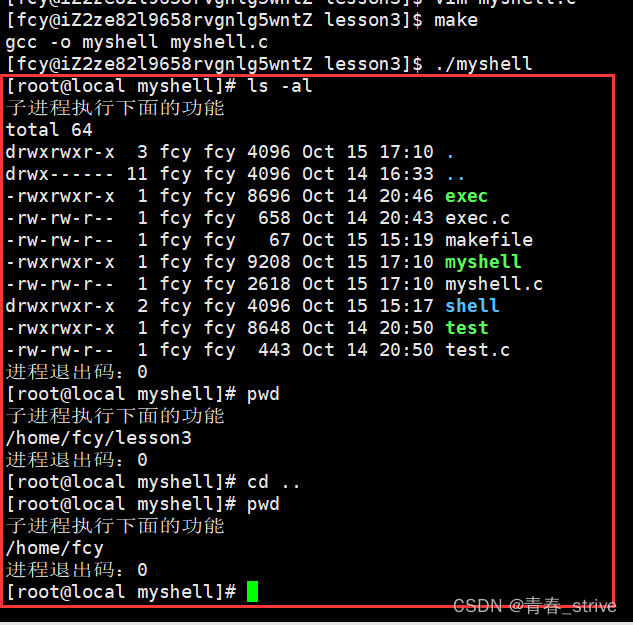



![[开源]MIT开源协议,基于Vue3.x可视化拖拽编辑,页面生成工具](https://img-blog.csdnimg.cn/img_convert/b55fb4e85a01ec6e03aa764f5a511797.png)