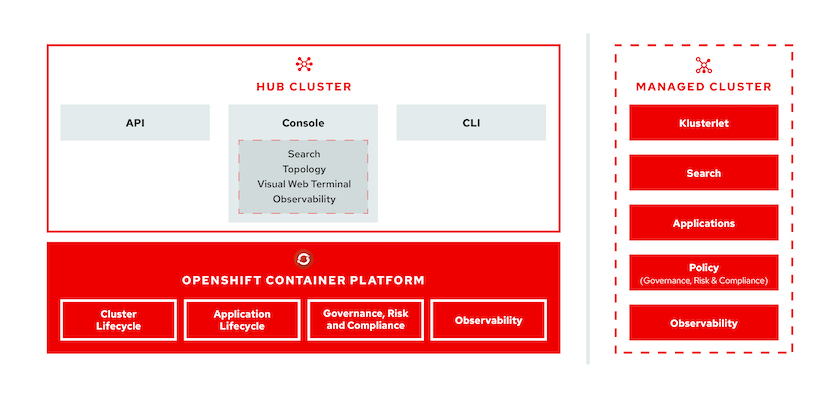
因为前阵子,有需求要将语音转为文本再进行下一步操作。感觉这个技术也不算是什么新需求,但是一搜,都是大厂的api,或者是什么什么软件,由于想要免费的,同时也要嵌入在代码中,所以这些都不能用。、
一筹莫展的时候,突然搜到whisper,这是个openai开源的工具,主打就是语音转文本。试了一下,还是不错的,虽然搜到的大多数介绍都是关于怎么直接命令行使用的,但是也有少量关于api的介绍,结合源码看了一下,还是很容易操作的。
这个项目,从安装开始,这个项目可能是太有名了还是啥,有很些大神进行了扩展和优化,所以直接pip安装的话,需要注意是pip install openai-whisper,直接装whisper不是那个哟。git地址openai-whisper![]() https://github.com/openai/whisper使用上,在代码中,import之后,whisper.load_model,传入模型名就可以了,不传的话,默认是small,个人觉得已经挺好的了,会自动下载,自动下载的权重是pt格式的,如果去hf下载的话,好像是bin格式,需要注意。模型名可以在源码中看到,或者是git上好像也有。顺便一提,由于hf需要科技,但是源码中的链接不是hf上的,下载速度还可以。
https://github.com/openai/whisper使用上,在代码中,import之后,whisper.load_model,传入模型名就可以了,不传的话,默认是small,个人觉得已经挺好的了,会自动下载,自动下载的权重是pt格式的,如果去hf下载的话,好像是bin格式,需要注意。模型名可以在源码中看到,或者是git上好像也有。顺便一提,由于hf需要科技,但是源码中的链接不是hf上的,下载速度还可以。
使用的时候model.transcribe再传入音频文件就可以了。是的,这个项目本身是不支持实时转录的,并且,传入的文件,他是通过ffmpeg来进行处理的,所以使用前需要安装ffmpeg。在使用transcribe方法的时候,还能追加一些参数,比如language,中文传zh或Chinese,如果不传,会自动检测音频前面一部分的主要语言,并且输出该语言。
需要注意的是,这个项目不支持多语言输出,注意,是输出,比如设定为中文,则无论输入音频是啥语言,输出都是中文,但中文是不是翻译的不太确认。这边试过英文,输入一段中文录音,结果输出是全英文,并且翻译后的英文,不是同音乱码啥的。其他参数建议就默认就行了。比如,如果torch检测到cuda可以用,就会自动切换cuda,并且量化fp16,如果是纯cpu,则fp16会报一个提示不可用,自动设为false。如果本机有显卡,但是加载显存不够而需要转cpu的话,则是在load_model方法设置device,但是即便是最大的模型,12G显存应该也是够用的,没仔细看。
这个项目有一些不足,第一,输入空白音频或者特别短的音频的时候,输出的文字是不对的,但是他有个参数名为no_speech_prob,顾名思义就是无人说话的概率;第二,接上一条,no_speech_prob这个值不太准,所以通过这个值进行过滤的时候,有可能会漏掉内容;第三,再接上一条,还是no_speech_prob这个值,这边测试,用小说软件读小说,基本上都认定无人说话,所以这个值莫非是检测是否是真人么,但对于真人录音,同样存在该值变动较大且不准的情况,即对于我的一段录音,总是会漏掉一些内容;第四,输出中文是繁体,有需要的简体的话,要再用zhconv转一下,zhconv.convert(text,'zh-cn');第五,速度快,但还不够快。
由whisper的速度,引发了下一个项目,不够快,经过一番查找,下面这个项目还是不错的
faster-whisper![]() https://github.com/guillaumekln/faster-whisperFasterWhsiperGUI 更快更强更好用的 whisper - 哔哩哔哩 (bilibili.com)
https://github.com/guillaumekln/faster-whisperFasterWhsiperGUI 更快更强更好用的 whisper - 哔哩哔哩 (bilibili.com)
这个链接写了一些对于whisper的一些评价,顺便推广了他自己的项目,他的项目似乎就是对faster这个的包装,弄了一个界面。所以我就直接使用faster了。
直接说结论,速度确实提升很大,不过宣称的4倍提升倒是没有测出来,但是两倍提升还是有的。其模型不能和原版模型共用,下载的话,需要去hf下,不过他也提供了将原版模型转为自己可用的模型,但是原版模型也要是hf的版本,所以科技还是少不了。
该项目的主要提升是速度提升很大,但是准确率没下降很多,但是这边测着,略有下降吧,不知道是不是个体差异,非专业和大量测试。
这两个whisper项目,优点是速度快,准确度还不错,缺点是幻听问题和返回是纯文本,没有标点的话,对于短文本还好,如果语句较长,歧义的风险比较大,不过他们都有返回时间戳,自己判断一下,在间隔较大的地方加个逗号也算满足要求。
但是由于我需要做的是语音ai对话,这样的话,如果输入文字有错误的话,ai的回复可能就会很莫名其妙,所以我需要找一个准确度更高的项目,此时强烈推荐funASR项目,由阿里达摩院开源。
funASR![]() https://github.com/alibaba-damo-academy/FunASR这个项目有点大,功能有点多,不过教程也是非常多的,简要说明一下,该项目支持三种模式,2pass:实时转录,并且会回头检测输出的文本,自动进行修改和标点添加;online:似乎是实时转录但是不会回头检测,没用过;offline:对全音频检测,就是输出2pass的最终结果,中间过程不输出。后面我用的全都offline模式,简单说一下其中的坑,最关键的是,从项目介绍来看,至少目前还不支持gpu,虽然用的时候好像显存有增加,但是他自己说gpu版还在进行中。
https://github.com/alibaba-damo-academy/FunASR这个项目有点大,功能有点多,不过教程也是非常多的,简要说明一下,该项目支持三种模式,2pass:实时转录,并且会回头检测输出的文本,自动进行修改和标点添加;online:似乎是实时转录但是不会回头检测,没用过;offline:对全音频检测,就是输出2pass的最终结果,中间过程不输出。后面我用的全都offline模式,简单说一下其中的坑,最关键的是,从项目介绍来看,至少目前还不支持gpu,虽然用的时候好像显存有增加,但是他自己说gpu版还在进行中。
首先,我是git下载源文件再安装的,因为如果pip下载的话,我不知道源文件在哪,而他的快速使用教程里面,需要找到源文件,再去某个目录下,开启服务端,再通过客户端请求转录文本,虽然有点麻烦,但是准确率比前面的高,并且,他自己介绍说,一般的硬件水平下也能支持百路并发,还是比较心动的,毕竟whisper的话,岂不是要我自己写flask来回应请求,效率不敢想。
此时发现,他的python服务端,只能支持一路,要多路并行,需要编译,不知道win能不能编译,反正教程是只写了linux怎么编。
再python环境下,同一段1分多几秒的音频,whisper需要10s左右,large模型,faster需要4s左右,也是large模型,但是内容有缺漏,换成small模型,只需要3s不到,内容反而不缺漏了。funasr用了33s,调用的是源文件中提供的api代码,里面有一些等待参数,都设为非常小的值了,0.0001什么的,这才到33s,如果设大一些,等待更久。查看api代码可知,他的请求方式是将音频循环读取chunk并发给服务端,服务端此时会返回识别内容,所以随着循环的进行,返回的内容会越来越多,越来越准,可以理解2pass模式是怎么工作的了。然后在最后关闭这个连接,此时会发来一个最终结果,这个就是offline的结果。不太能理解为什么不能一次输入全文件,然后直接得到结果。但是问题在于,在调用api的时候,发现,他最终结果经常发来一个空,反而是循环体中返回的内容是可用和正确的。感觉还是主打2pass,至少这个api文件是这样,如果设置为2pass模式的话,能看到每一步的返回,还有内容的修改,挺有意思的,大概是流式输出的意思。
总结,funasr,准确率高,有标点,但是慢,极慢。
事情还没完,在使用funasr之后,既眼馋他的准确,又遗憾他的速度,难道就不能两全么,原本我的目标是放在c++编译上,大不了编译出来一个,按说python转成c++之后,十倍提升应该不是问题才对。
此时仔细研究了下源码文件,发现之前使用的是runtime下的python目录的websocket,而python目录下还有onnx和libtorch,从目录名来看,这个项目貌似支持很多语言,然后仅就python而言,也有多种实现方式。
这边试了下libtorch,其每个文件夹下都有一个readme和demo,比较详细的介绍了怎么用,比如如何安装 torch版,然后怎么转换模型,因为直接下载的模型是pb格式,他需要转成torchscript格式,这一步卡了我好就,因为没有关注到这一点,一直以为是我下载的模型不对,而在modelscope中搜索半天,找不到之后,都准备提issue了,然后再一次看readme的时候,发现开头就写了要装onnx来转一下权重。而且不知道是不是路径问题,转换的时候会重新下载权重到当前目录下然后再转,所以可以提前把默认路径下的权重拷贝到当前目录。
demo中,关于model的加载,有一条是注释了gpu的,但是使用的话,无论传什么音频进去都提示“input wav is silence or noise”,不信邪的我再查看源码,发现这句打印只是在except中,打开注释掉的traceback.format_exc(),会打印真实原因,说是two device,看报错似乎不是我可以解决的,于是还是改为cpu版,此时速度只需要3s左右,准确率很好,但是没有了标点,只有一大段文字。然后下载官方长音频版权重,带vad和punc,输出还是没有标点,最后根据每个字的时间戳,遍历了一遍,总耗时达到4s,再改,用gevent,只需要分析相邻两字的时间即可,此时总耗时大概是3s,行吧,不想折腾了。