Pytorch从零开始实战——明星识别
本系列来源于365天深度学习训练营
原作者K同学
文章目录
- Pytorch从零开始实战——明星识别
- 环境准备
- 数据集
- 模型选择
- 开始训练
- 模型可视化
- 模型预测
- 总结
环境准备
本文基于Jupyter notebook,使用Python3.8,Pytorch2.0.1+cu118,torchvision0.15.2,需读者自行配置好环境且有一些深度学习理论基础。本次实验的目的是了解如何设置动态学习率。
第一步,导入常用包。
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn.functional as F
import random
from time import time
import numpy as np
import pandas as pd
import datetime
import gc
import os
import copy
os.environ['KMP_DUPLICATE_LIB_OK']='True' # 用于避免jupyter环境突然关闭
torch.backends.cudnn.benchmark=True # 用于加速GPU运算的代码
设置随机数种子
torch.manual_seed(55)
torch.cuda.manual_seed(55)
torch.cuda.manual_seed_all(55)
random.seed(55)
np.random.seed(55)
创建设备对象
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device # device(type='cuda')
数据集
本次数据集使用的一系列明星图片,每一位明星的图片存放在对应的文件夹中,文件夹名为明星的姓名。
使用pathlib查看类别名称
import pathlib
data_dir = './data/star'
data_dir = pathlib.Path(data_dir) # 转成pathlib.Path对象
data_paths = list(data_dir.glob('*'))
classNames = [str(path).split("/")[2] for path in data_paths]
classNames

使用transforms将图片进行预处理,并且使用datasets整合数据集,每个姓名标签对应的一个数字标签。
train_transforms = transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])total_data = datasets.ImageFolder("./data/star/", transform=train_transforms)
total_data.class_to_idx

查看随机五张图片。

将数据集以8比2划分为训练集和测试集,使用DataLoader划分批次和随机打乱。
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_ds, test_ds = torch.utils.data.random_split(total_data, [train_size, test_size])batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,batch_size=batch_size,shuffle=True,)
test_dl = torch.utils.data.DataLoader(test_ds,batch_size=batch_size,shuffle=True,)len(train_dl.dataset), len(test_dl.dataset) # (1440, 360)
模型选择
本次实验我们直接调用官方的数据集,使用官方预训练的VGG16,冻结模型参数,只训练最后一层的参数。
# 调用官方vgg16
from torchvision.models import vgg16
model = vgg16(pretrained = True).to(device) # 加载预训练的vgg16模型for param in model.parameters():param.requires_grad = False # 冻结模型的参数,只训练最后一层的参数model.classifier._modules['6'] = nn.Linear(4096, len(classNames)) # 修改vgg16模型中最后一层全连接层,输出目标类别个数
model.to(device)
model

创建模型,使用summary查看参数,VGG16的参数还是比较多的。
from torchsummary import summary
# 将模型转移到GPU中
model = model.to(device)
summary(model, input_size=(3, 224, 224))

开始训练
定义训练函数
def train(dataloader, model, loss_fn, opt):size = len(dataloader.dataset)num_batches = len(dataloader)train_acc, train_loss = 0, 0for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)opt.zero_grad()loss.backward()opt.step()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
定义测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)test_acc, test_loss = 0, 0with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss += loss.item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss
设置超参数,本次使用官方的学习率衰减,学习率每经过 4 个 epoch 就会以 0.92 的指数衰减。
lambda1 = lambda epoch: 0.92 ** (epoch // 4)
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.001
opt = torch.optim.SGD(model.parameters(), lr=learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(opt, lr_lambda=lambda1) # 选定调整方法
开始训练,可能是因为只训练最后一层,模型学习的不是很好。
import time
epochs = 30
train_loss = []
train_acc = []
test_loss = []
test_acc = []T1 = time.time()best_acc = 0
best_model = 0for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)scheduler.step()model.eval() # 确保模型不会进行训练操作epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)if epoch_test_acc > best_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)print("epoch:%d, train_acc:%.1f%%, train_loss:%.3f, test_acc:%.1f%%, test_loss:%.3f"% (epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))T2 = time.time()
print('程序运行时间:%s毫秒' % ((T2 - T1)*1000))PATH = './best_model.pth' # 保存的参数文件名
if best_model is not None:torch.save(best_model.state_dict(), PATH)print('保存最佳模型')
print("Done")

模型可视化
可视化函数
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
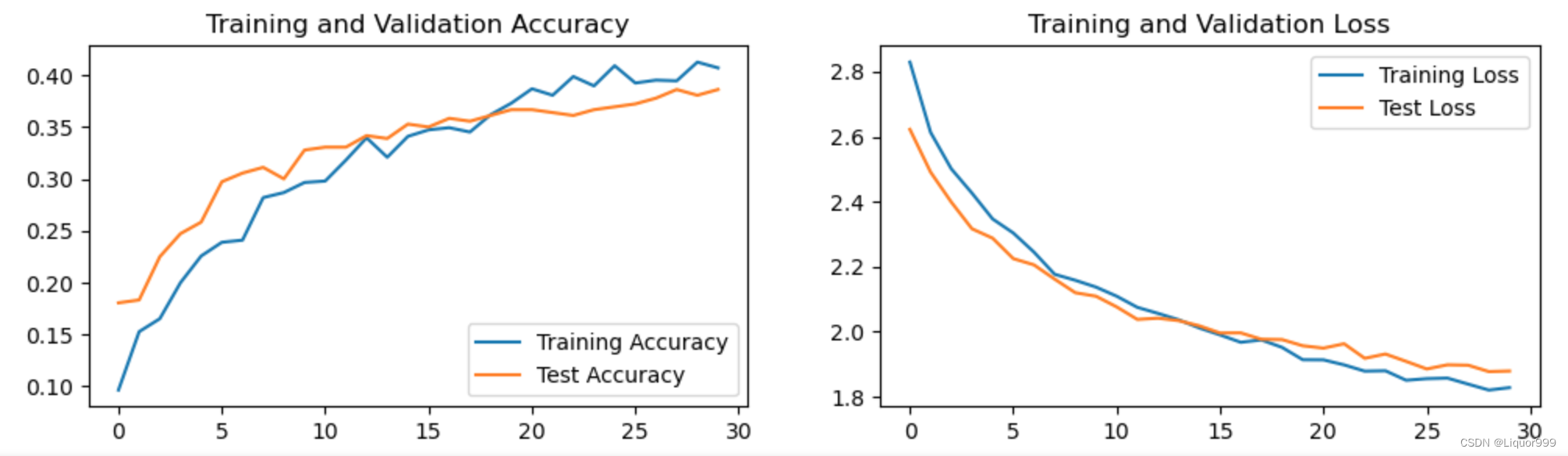
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
模型预测
定义预测函数
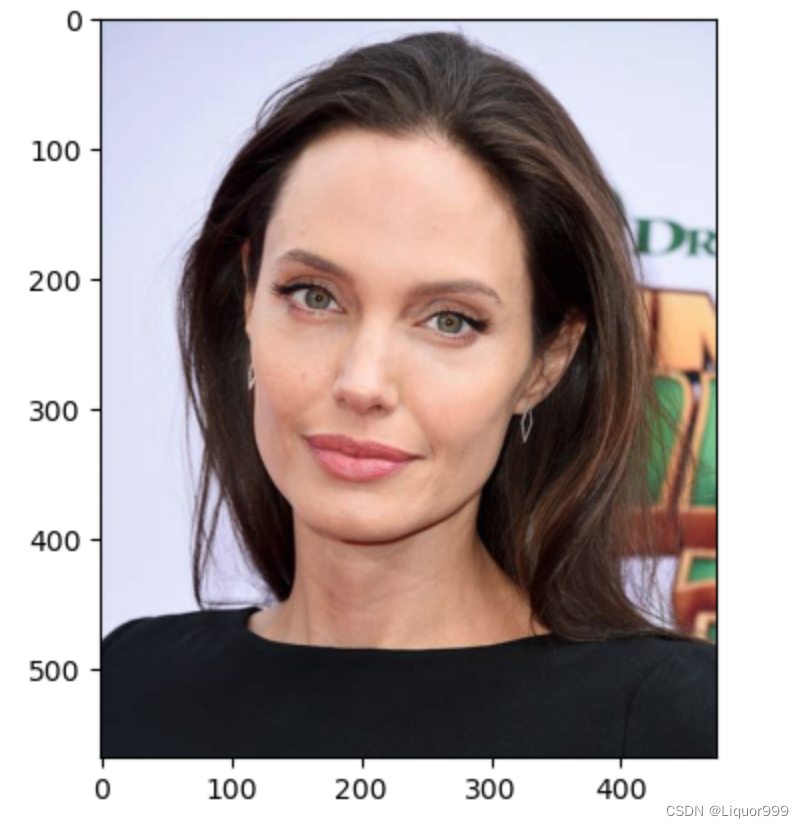
from PIL import Image classes = list(total_data.class_to_idx)def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_,pred = torch.max(output,1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')
调用函数,使用模型预测图片
predict_one_image(image_path='./data/star/Angelina Jolie/001_fe3347c0.jpg', model=model, transform=train_transforms, classes=classes)
# 预测结果是:Angelina Jolie
使用保存的最佳模型查看一下损失。
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
epoch_test_acc, epoch_test_loss # (0.3861111111111111, 1.9115476707617443)
总结
本次调用官方预训练的VGG模型,由于VGG的参数量过大,我们仅训练了最后一层,所以效果不是很好,所以未来数据集比较大的时候,可以放开所有的层重新训练。


![[架构之路-240]:目标系统 - 纵向分层 - 应用层 - 应用层协议与业务应用程序的多样化,与大自然生物的丰富多彩,异曲同工](https://img-blog.csdnimg.cn/caf5fe620f0647d18a6ffcf629648b61.png)