一、冒泡排序算法:
介绍:
冒泡排序(Bubble Sort)是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端。
作为最简单的排序算法之一,冒泡排序给我们的感觉就像 Abandon 在单词书里出现的感觉一样,每次都在第一页第一位,所以最熟悉。冒泡排序还有一种优化算法,就是立一个 flag,当在一趟序列遍历中元素没有发生交换,则证明该序列已经有序。但这种改进对于提升性能来说并没有什么太大作用。
原理:
排序的趟数len-1,每趟将数组的中的进行两两比较,若前者值比后者值大(小),发生索引元素交换,每遍历一次,最后一位产生一个最大(小)值;
代码:
/*** 冒泡排序算法+优化* @param arr 数组* @param type 升序:asc 降序:desc*/
public void sort(int[] arr,String type){
// 原理:排序的趟数len-1,每趟将数组的中的进行两两比较,若前者值比后者值大(小),发生索引元素交换,每遍历一次,最后一位产生一个最大(小)值; System.out.println("原数组:"+Arrays.toString(arr));boolean flag = false; // 用来判断是否有交换,无交换说明已经排好序,不需要再排;默认无交换;for (int i = 0; i < arr.length - 1; i++) { // 执行多少轮 数组长度-1flag = false; // 每次循环之后,重置默认无交换for (int j = 0; j < arr.length - i - 1; j++) { // 每论执行多少次比较 数组长度-i-1if(type.equals("desc")){ // 降序排序if(arr[j] < arr[j+1]){ // 两数比较:前数小交换int tmp = arr[j];arr[j] = arr[j+1];arr[j+1] = tmp;flag = true;}}else{ // 升序排序if(arr[j] > arr[j+1]){ // 两数比较:前数大交换int tmp = arr[j];arr[j] = arr[j+1];arr[j+1] = tmp;flag = true;}}}System.out.println("第"+(i+1)+"排序:"+Arrays.toString(arr));if(!flag){ // 如果当前轮没有发生两数之间的交换,说明顺序已经排好,结束循环break;}}
}二、选择排序SelectionSort
介绍:
选择排序是一种简单直观的排序算法,无论什么数据进去都是 O(n²) 的时间复杂度。所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。
原理:
int[] ints = {6, 1, 4, 5, 2, 3};/** 第一轮: 下标为0的元素作为最小的, 下标0和下标1(下标为最小), 下标1和下标2, 下标1和下标3, 下标1和下标4, 下标1和下标5 5次* 1 6 4 5 2 3* 第二轮: 下标为1的元素作为最小的, 下标1和下标2(下标2位最小), 下标2和下标3, 下标2和下标4(下标4位最小), 下标4和下标5 4次* 1 2 4 5 6 3* 第三轮: 下标为2的元素作为最小的, 下标2和下标3, 下标2和下标4, 下标2和下标5(下标5最小) 3次* 1 2 3 5 6 4* 第四轮: 下标为3的元素作为最小的, 下标3和下标4, 下标3和下标5(下标5最下) 2次* 1 2 3 4 6 5* 第五轮: 下标为4的元素作为最小的, 下标4和下标5(下标5最小) 1次* 1 2 3 4 5 6* */代码:
/*** 选择排序-升序* @param arr 要排序的数组*/
public static void selectionSortAscendingOrder(int[] arr){// 原理:比较len-1趟;假设第n(从0开始)个位置的值为最小值,依次与后面的值比较,若前者数大于后者数,记录后者元素对应的索引;一趟之后,将两个索引位置元素进行交换// 需要循环的趟数,比较数组长度-1趟,例如:数组长度6,需要遍历5趟,依次找到五个最小值for (int i = 1; i < arr.length; i++) {int minIndex = i-1;// 记录:最小元素索引位置// 每趟需要比较的次数;for (int j = i; j < arr.length; j++) {//第一个索引位置的值依次与后面元素比较,若前者的值大于后者值,那么最小值的索引为后者元素的索引if(arr[minIndex] > arr[j]){minIndex = j;}}// 判断最小元素是否是自己,若不是自己再发生交换if(minIndex != i-1){ // 算数运算符的优先级高于比较运算符// 获取第一个位置的元素int temp = arr[i-1];// 获取最小索引位置的元素arr[i-1] = arr[minIndex];// 将两处索引位置的值交换arr[minIndex] = temp;}}三、快速排序
介绍:
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!它是处理大数据最快的排序算法之一了。
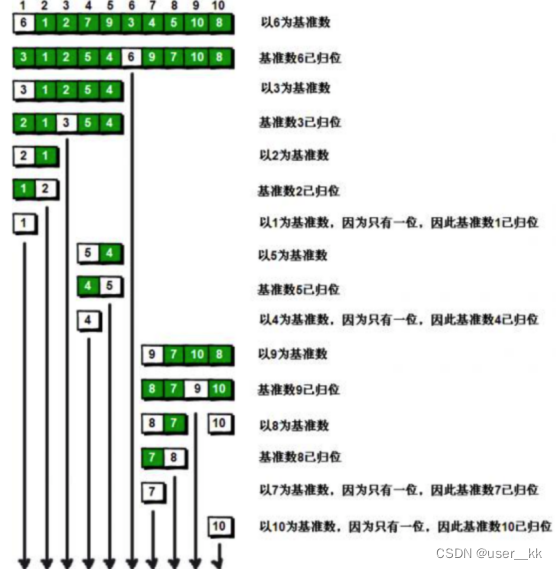
原理(步骤):
1. 从数列中挑出一个元素,称为 "基准"(pivot);
2. 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
3. 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
代码:
/*** 快速排序: 原理:以左边索引位0的数为基准,* 先从右边开始找,直到找到比基准数小的为止(左边索引小于右边索引);* 再从左边开始找直到找到比索引值大的为止(左边索引小于右边索引);* 交换两处索引位置的值;* 如果左边索引与右边索引相同,那么基准值与索引相同处元素替换使用递归依次处理* 左分区递归递归* 右分区递归递归* 判断递归出口* @param arr* @param left* @param right*/
public static void quickSort(int[] arr, int left, int right) {// 使用递归时的出口if(left >= right){return;}int i = left + 1;// left+1 表示从基准值下一位开始int j = right;// 基准元素(pivot Element)int baseElement = arr[left];// 循环交换数组中 比基准值大的 与 比基准值小的 交换while (i != j) {// 先从右边开始找, 如果找到比基准值小的 结束查找,并且左边索引要小于右边索引while (arr[j] > baseElement && i < j) {j--;}// 再从左边开始找,如果找到比基准值大的 结束查找,并且左边索引要小于右边索引while (arr[i] < baseElement && i < j){i++;}// 如果找到了左边找到了比基准值小的,右边找到了比基准值大的,两元素发生交换if(j != i){ // 如果两个索引相同就不需要交换了结束循环int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}// 左边索引与右边索引指向同一位置说明找到了,该基准值的位置;将基准值与索引位置值发生交换arr[left] = arr[i];arr[i] = baseElement;// 左分区递归调用排序quickSort(arr,left,i-1);// 右分区递归调用排序quickSort(arr,i+1,right);
}