这不是马上要到1024了吗,这不得弄个什么工具给部门项目提提效😯?
1. 背景
在我们服务端应用当中,我们往往会要求更高的性能和更高的稳定性,但实际开发的过程中,可能会出现很多赶时间的情况(也不排除代码水平问题),那么代码就会写的比较随性🤣。

这里我主要想探讨的是 服务的不合理调用链路 对项目造成的影响。
首先介绍一下这里所指的 服务的不合理调用链路,它们包括但不限于以下情况:
- 同一个接口中反复调用同一个SQL或Dubbo。
- 接口入参没有做限制,加载大量数据,或某条SQL一次性查询出大量数据。
- SQL查询速度慢,没有正确使用索引或出现不合理的连表。
其实就是一些耗时操作,它们本来就比较费时间,还要被重复调用,或者是一些不合理的SQL,这很显然是可优化的。优化方法也很明显,限制参数、循环查询改成批量查询、SQL加索引等。
所以现在想要找出那些不合理的代码,怎么找就成了问题的关键。
PS:以下是我和我导师(wingli 的个人主页)的设计方案,与公司业务无关,所以才写成博客进行分享,各位且看且珍惜。(记得点赞关注✍️)
2. 方案选择
经过一上午的研究,得出以下几种方案。
| 方法 | 实现方式 | 优点 | 缺点 | 总结 |
| 静态代码分析 | 可以通过idea插件的方式,写一些代码检测逻辑。找出可能存在的不合理代码,约等于一个简单的代码review。 | 可以在编码期就针对性的做一些提醒,让写代码的人及时调整实现方式。 | 无法做到运行时处理,无法判断一些运行期可能出现的问题,比如大对象,而且以前的老项目也顾及不到。 | 应该属于是一个有用但收益相对较低的方案。 |
| 分析APM上报的数据 | APM会默认采集sql、dubbo、http、redis等调用链路数据,然后上报到ES,我们可以去ES中获取这些数据,然后对这些数据进行分析,寻找不合理的调用链路。 | 链路调用的数据比较全,而且已经普及到所有项目当中了。 | APM采样的数据方式无法兼容我们所有的需求,比如无法判断参数是否过大、是否多次重复调用相同的接口等。 | 有基础内容,但不完全满足需求。 |
| Java agent埋点 | 自己做一个采样工具,基于Java agent来实现,在需要被采集信息的方法前后插入代码,实现信息收集。 | 可自定义程度高,可以完全实现需求。 | 需要自己实现,有一定的工作量。 | 可以实现,也能满足需求,就是时间成本会高一些。 |
| 拦截器保留慢接口数据 | 通过拦截请求,判断请求耗时,采集高耗时的接口信息。 | 实现简单。 | 可收集的数据少,无法满足需求。如链路中多次调用相同的SQL或者Dubbo,无法收集。 | 实现简单,但不能满足需求,不如分析APM上报数据。 |
| 人工review | 自己在写的时候多检查几遍,并且代码评审时部门成员也认真提出不合理调用。 | 无需代码层面实现,没准还可以提高团队review次数。 | 更加消耗时间,而且没有保障,如果没注意就错过了,也难以对以前的项目全部进行review | 需要消耗大量的人员时间,属于是减效。 |
综合考虑各种方案的情况,决定通过 agent埋点 的方法来实现。
2.1. Java agent
这块估计很多小伙伴也不太了解,所以跟大家简单介绍一下。先来点官方的:
Java agent 是JVM提供的一种机制,允许开发者在应用程序运行时修改或增强已加载的类和字节码。通过 Java agent,开发者可以在不修改源代码的情况下,对应用程序进行动态的修改、监控和增强。
Java agent 的工作原理是通过在 JVM 启动时,通过命令行参数动态加载一个特殊的 jar 文件,这个 jar 文件被我们称为 Java agent。Java agent 可以用于字节码增强、性能监控、类加载和转换等方面的应用。它为开发者提供了更灵活和强大的工具,用于对 Java 应用程序进行动态修改和增强。
乍一看,感觉有点像Spring AOP,这里讲一下它们的区别:
Java agent 提供了更底层的字节码级别的修改和增强能力,可以在任何 Java 应用程序中使用,而 Spring AOP 是基于代理模式的框架,主要用于在 Spring 容器中对业务逻辑进行增强。
大概就是这样了,如果你还不太清除 Java agent 到底是个什么东西的话,那你就当它是“一种在字节码上进行修改的AOP”。
更详细的Java agent教程可以去网上找找其他文章,因为我也不太懂,这里我就不做过多介绍了。

3. 实现方案
3.1. 项目架构
项目架构分为:埋点层、收集层、上报层、持久层、展示层。其中前三层在agent服务当中,后两层在server服务当中,如下图所示:
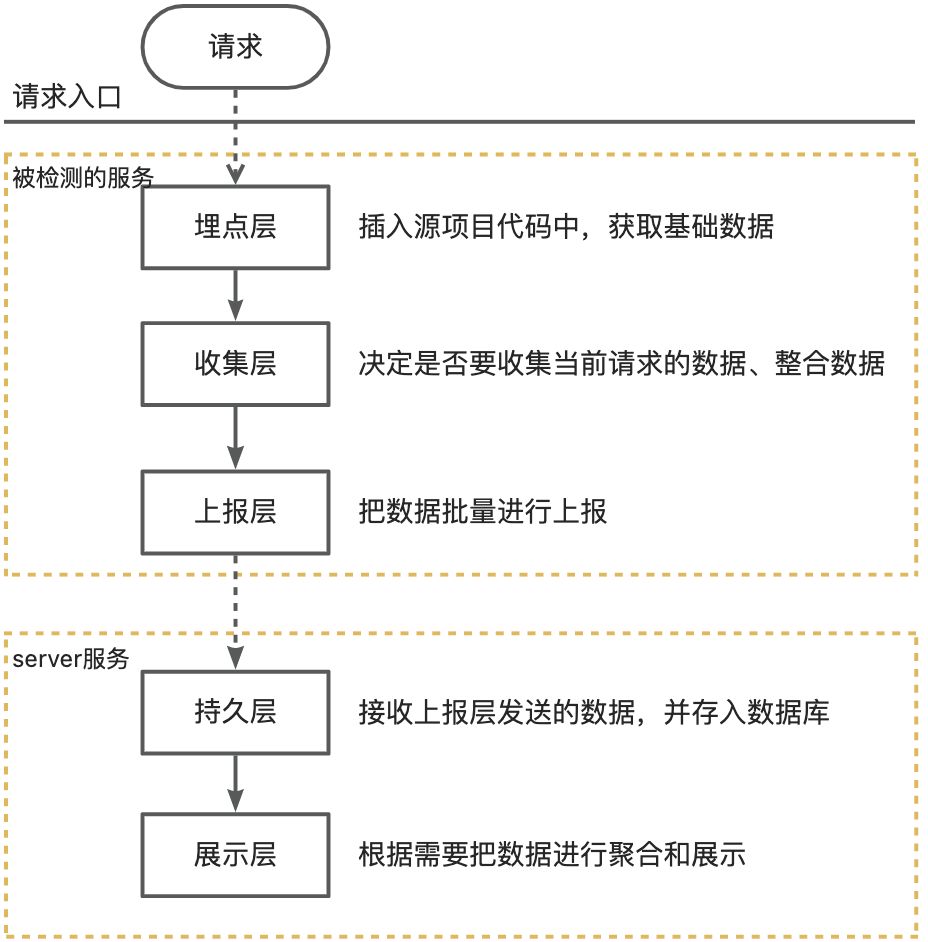
被检测的服务是使用了 Java agent 进行增强的服务,埋点层、收集层、上报层都是由agent插入到源项目代码当中的,对源代码无侵入性。
3.2. 埋点方案
首先我们需要对每一个请求都进行信息收集,我们把一个完整的请求称为 Transaction ,目前考虑到的请求入口包括:
- 来自客户端的HTTP请求
- 来自其他服务调用的Dubbo请求
- 来自MQ发来的消息消费
- 来自定时任务的调度事件
其次我们需要收集的信息主要是一些可能比较耗时的操作,我们把每一个操作称为 Span ,主要包括一些涉及到IO的操作:
- 数据库操作
- Redis操作
- Dubbo操作
- MQ操作
- 通过HTTP调用三方服务的操作
- 复杂的计算逻辑
我们在上述每一个入口处和每一个耗时操作前后都通过agent添加埋点,入口前后的埋点用来表示请求的开始和结束,而耗时操作前后的埋点则会获取当前堆栈中的相关数据,这样就构成了第一层【埋点层】。
核心代码示例如下:
public class BadCallDetectTransformer implements ClassFileTransformer {private static final CopyOnWriteArraySet<String> enhancedClass = new CopyOnWriteArraySet<>();private Instrumentation inst;public BadCallDetectTransformer(Instrumentation inst) {this.inst = inst;}public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined, ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {if (className == null) return classfileBuffer;className = className.replace("/", ".");try {//transaction httpif (className.equals("org.springframework.web.method.support.InvocableHandlerMethod")) {if (!enhancedClass.contains(className)) {String beforeCode = TransformerUtils.unShadeIfNecessary("shaded.com.seewo.detect.agent.helper.TransactionHelper.httpTransactionEnter($args,$0);");String afterCode = TransformerUtils.unShadeIfNecessary("shaded.com.seewo.detect.agent.helper.TransactionHelper.httpTransactionExit($args,$0,$_);");classfileBuffer = TransformerUtils.insertMethodBefore("doInvoke", loader, classfileBuffer, beforeCode);classfileBuffer = TransformerUtils.insertMethodAsFinally("doInvoke", loader, classfileBuffer, afterCode);logger.warn("enhanced class:{}", className);enhancedClass.add(className);}}//span mybatisif (className.equals("org.apache.ibatis.binding.MapperMethod")) {if (!enhancedClass.contains(className)) {//org.apache.ibatis.binding.MapperMethod,org.apache.ibatis.session.SqlSession,java.lang.ObjectString beforeCode = TransformerUtils.unShadeIfNecessary("shaded.com.seewo.detect.agent.helper.SpanHelper.mybatisSpanEnter($2,$0);");String afterCode = TransformerUtils.unShadeIfNecessary("shaded.com.seewo.detect.agent.helper.SpanHelper.mybatisSpanExit($2,$0,$_);");classfileBuffer = TransformerUtils.insertMethodBefore("execute", loader, classfileBuffer, beforeCode);classfileBuffer = TransformerUtils.insertMethodAsFinally("execute", loader, classfileBuffer, afterCode);logger.warn("enhanced class:{}", className);enhancedClass.add(className);}}} catch (Throwable t) {logger.error("enhance class:{} fail.", className, t);}return classfileBuffer;}}
其中 TransactionHelper 和 SpanHelper 的核心示例代码如下:
/*** transaction*/
public class TransactionHelper {public static void httpTransactionEnter(Object[] args, InvocableHandlerMethod invocableHandlerMethod) {String mark = "";long argLength = -1;TransactionData transactionData = null;try {Method method = invocableHandlerMethod.getMethod();Class<?> clazz = method.getDeclaringClass();mark = clazz.getName() + "#" + method.getName();if (!Collector.shouldBeCollect(mark, TransactionTypeEnum.HTTP, true)) {return;}TransactionHttpData transactionHttpData = new TransactionHttpData();RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();if (requestAttributes instanceof ServletRequestAttributes) {String uri = ((ServletRequestAttributes) requestAttributes).getRequest().getRequestURI();transactionHttpData.setUri(uri);}argLength = Utils.toJSONStringWithCatch(args).length();transactionData = transactionHttpData;} catch (Throwable t) {logger.warn("httpTransactionEnter err.", t);} finally {Collector.transactionEnter(mark, TransactionTypeEnum.HTTP, argLength, transactionData);}}public static void httpTransactionExit(Object[] args, InvocableHandlerMethod invocableHandlerMethod, Object returnObj) {String mark = "";long resultLength = -1;TransactionData transactionData = null;try {Method method = invocableHandlerMethod.getMethod();Class<?> clazz = method.getDeclaringClass();mark = clazz.getName() + "#" + method.getName();if (!Collector.shouldBeCollect(mark, TransactionTypeEnum.HTTP, false)) {return;}resultLength = Utils.toJSONStringWithCatch(returnObj).length();} catch (Throwable t) {logger.warn("httpTransactionExit err.", t);} finally {Collector.transactionExit(mark, resultLength, transactionData);}}}/*** span*/
public class SpanHelper {public static void mybatisSpanEnter(Object[] args, MapperMethod mapperMethod) {String mark = "";long length = -1;SpanData spanData = null;try {Field sqlCommandField = MapperMethod.class.getDeclaredField("command");sqlCommandField.setAccessible(true);MapperMethod.SqlCommand sqlCommand = (MapperMethod.SqlCommand) sqlCommandField.get(mapperMethod);mark = sqlCommand.getName();if (!Collector.shouldBeCollect(mark, SpanTypeEnum.MYBATIS)) {return;}String sqlCommandType = sqlCommand.getType().toString();length = Utils.toJSONStringWithCatch(args).length();} catch (Throwable t) {logger.warn("mybatisSpanEnter err.", t);} finally {Collector.spanEnter(mark, SpanTypeEnum.MYBATIS, length, spanData);}}public static void mybatisSpanExit(Object[] args, MapperMethod mapperMethod, Object returnObj) {String mark = "";long length = -1;SpanData spanData = null;try {Field sqlCommandField = MapperMethod.class.getDeclaredField("command");sqlCommandField.setAccessible(true);MapperMethod.SqlCommand sqlCommand = (MapperMethod.SqlCommand) sqlCommandField.get(mapperMethod);mark = sqlCommand.getName();if (!Collector.shouldBeCollect(mark, SpanTypeEnum.MYBATIS)) {return;}length = Utils.toJSONStringWithCatch(returnObj).length();} catch (Throwable t) {logger.warn("mybatisSpanExit err.", t);} finally {Collector.spanExit(mark, length, spanData);}}}
3.3. 收集方案
埋点层获取到主要信息后,就调用【收集层】的方法,把这些数据添加到一个临时的缓存中,并通过线程id把前后关联的数据连接起来,以形成一个完整的调用链路,这里可以用 ThreadLocal 来充当这一层的缓存。
收集层接口传入的主要参数应该包括:
- 方法的类型,DB、Redis、Dubbo、MQ等
- 方法的唯一标识,用于判断是否多次重复调用了同样的接口
- 方法的参数长度
- 其他需要的数据
一个请求开启时,记录初始时间,后续每次收到一条数据,就计算一下距离上次传入数据经过了多久,然后把他们放到当前线程的List内。
当请求结束后,计算出总耗时,同时判断该数据是否需要被上报,并不是所有数据都有上报价值,事实上,大部分的数据都是不需要上报的。
核心代码实现:
public class Collector {private static final ThreadLocal<Transaction> transactionThreadLocal = new ThreadLocal<>();private static final AtomicInteger atomicInteger = new AtomicInteger(0);/*** 是否需要收集*/public static boolean shouldBeCollect(String mark, TransactionTypeEnum transactionTypeEnum, boolean isEnter) {if (isEnter) {// 采样return Math.random() < 0.01 && atomicInteger.get() < 100;} else {Transaction transaction = getTransaction();return transaction != null;}}/*** 是否需要收集*/public static boolean shouldBeCollect(String mark, SpanTypeEnum spanTypeEnum) {Transaction transaction = getTransaction();return transaction != null;}/*** 事务开始** @param mark 事务标记* @param transactionTypeEnum http dubbo mq ...* @param length* @param transactionData*/public static void transactionEnter(String mark, TransactionTypeEnum transactionTypeEnum, long length, TransactionData transactionData) {try {// 值判定if (StringUtils.isBlank(mark) || length < 0) {return;}Transaction transaction = new Transaction();transaction.setTransactionType(transactionTypeEnum.getType());transaction.setMark(mark);transaction.setStartTime(System.currentTimeMillis());transaction.setTransactionData(transactionData);transaction.setArgLength(length);initTransaction(transaction);} catch (Throwable t) {logger.warn("transactionEnter err.");clearTransaction();}}public static void transactionExit(String mark, long length, TransactionData transactionData) {try {// 值判定if (StringUtils.isBlank(mark) || length < 0) {return;}Transaction transaction = getTransaction();if (transaction == null) return;// 计算耗时transaction.setCostTime(System.currentTimeMillis() - transaction.getStartTime());if (transaction.getCostTime() < 20) {return;}transaction.setTransactionData(transactionData);transaction.setReturnLength(length);// 整合计算数据CallStatData linkData = mergeData(transaction);// 上报数据MessageClient.add(linkData);} catch (Throwable t) {logger.warn("transactionExit err.");} finally {clearTransaction();}}/*** @param spanData sql的长度, dubbo的方法名,mq的topic*/public static void spanEnter(String mark, SpanTypeEnum spanTypeEnum, long length, SpanData spanData) {try {// 值判定if (StringUtils.isBlank(mark) || length < 0) {return;}Transaction transaction = getTransaction();if (transaction == null) return;Span span = new Span();span.setMark(mark);span.setSpanType(spanTypeEnum);span.setSpanData(spanData);span.setStartTime(System.currentTimeMillis());span.setArgLength(length);transaction.getSpanList().add(span);} catch (Throwable t) {logger.warn("transactionExit err.");clearTransaction();}}public static void spanExit(String mark, long length, SpanData spanData) {try {// 值判定if (StringUtils.isBlank(mark) || length < 0) {return;}Transaction transaction = getTransaction();if (transaction == null) return;Span span = transaction.getSpanList().get(transaction.getSpanList().size() - 1);span.setCostTime(System.currentTimeMillis() - span.getStartTime());span.setReturnLength(length);} catch (Throwable t) {logger.warn("transactionExit err.");clearTransaction();}}private static void clearTransaction() {transactionThreadLocal.remove();atomicInteger.decrementAndGet();}private static void initTransaction(Transaction transaction) {transactionThreadLocal.set(transaction);atomicInteger.incrementAndGet();}private static Transaction getTransaction() {return transactionThreadLocal.get();}}
3.3.1. 收集规则
判断该数据是否需要被收集,我们可以根据该请求的一些指标,来判断它可能的不合理程度,再加上随机采样的一些方法,来决定是否要保留这条数据。
暂且制定一些简单的规则:
- 请求的执行时长超过2s,收集(耗时过长)
- 记录每个接口的平均执行耗时,如果单个请求耗时超过平均耗时的5倍,收集(异常情况耗时过长)
- 请求的相关参数长度超过2000,收集(可能没做接口参数限制或分页查询限制)
- 调用链路中,出现较多的重复调用,收集(代码层面可能有优化空间)
- 调用链路中,收集到的span超过50个,收集(代码层面有优化空间)
- 其他正常流通的数据中,进行低频率动态采样,具体采样规则:
-
- 采样基本频率为 1/100
- 判断当前请求数压力,压力较大时降低频率
- 判断JVM内存情况,内存不足时,降低频率
3.3.1.1. 保险措施
同时,为了减少服务压力极大和内存严重不足时agent对源系统的影响,我们可以在请求开启时也做一次判断,如果当前压力值过大,我们可以直接放弃对当前链路所有基础数据的保存。
当压力极大时,系统本身就是非常不稳定的,可能所有的接口耗时都会提高非常多,这种情况下可能会导致收集器大量收集信息,从而加速服务的崩溃。
目前测试阶段数据量还比较少,所以基本都是全量收集,这块收集过滤的代码还没实现🤣。
3.3.2. 数据整合
当一条 Transaction 数据确认要被收集时,我们把它进行整合,主要是对 Span 当中的重复数据进行压缩,变成一条独立的数据,这样可以节省很多空间。
目前的话,我们考虑保留的 Transaction 数据包含:
- 总耗时
- 多次重复调用的span信息列表
-
- span调用次数
- span调用平均耗时
- 入参长度
- 出参长度
- 请求开始时间
整合完之后就可以发送给下一层了,同时把 ThreadLocal 中的数据也进行清除。
核心代码:
/*** Class: Collector* 整合数据*/private static CallStatData mergeData(Transaction transaction) {CallStatData callStatData = new CallStatData();callStatData.setMark(transaction.getMark());callStatData.setCostTime(transaction.getCostTime());callStatData.setStartTime(transaction.getStartTime());callStatData.setTransactionType(transaction.getTransactionType());callStatData.setArgLength(transaction.getArgLength());callStatData.setReturnLength(transaction.getReturnLength());callStatData.setTransactionData(transaction.getTransactionData());SpanCallCountStat countStat = new SpanCallCountStat();HashMap<String, SpanStat> statMap = new HashMap<>();// 统计调用次数和耗时、参数长度等信息for (Span span : transaction.getSpanList()) {countStat.addCallCount(span.getSpanType());// 使用 type+mark 作为keyString mapKey = span.getSpanType().getType() + span.getMark();SpanStat spanStat = statMap.computeIfAbsent(mapKey, key -> {// 初始化SpanStat value = new SpanStat();value.setMark(span.getMark());value.setSpanType(span.getSpanType().getType());return value;});// 添加调用信息spanStat.addCallCount(span.getCostTime(), span.getArgLength(), span.getReturnLength());}callStatData.setCallStat(countStat);callStatData.setSpanList(new ArrayList<>(statMap.values()));return callStatData;}/*** Class: SpanStat* 添加调用次数,参数:耗时、参数长度、返回值长度*/public void addCallCount(long costTime, long argLength, long returnLength) {callCount++;// 平均执行时间的增量计算公式:(当前执行时间 - 历史平均执行时间 * 当前执行次数) / 总执行次数avgCostTime += (costTime - avgCostTime) / callCount;maxCostTime = Math.max(maxCostTime, costTime);avgArgLength += (argLength - avgArgLength) / callCount;maxArgLength = Math.max(maxArgLength, argLength);avgReturnLength += (returnLength - avgReturnLength) / callCount;maxReturnLength = Math.max(maxReturnLength, returnLength);}
注意,到这里还只是简单了做了收集和处理,并没有持久化起来。
如果我们在agent服务中直接进行持久化,那势必会对原服务有较大的影响,不仅要求原服务提供数据源,还要求该数据源中有一张专门的表来供我们存储。
所以我们可以考虑把这部分功能进行分离,创建一个单独的server服务,来完成持久层和展示层的操作,然后所有的agent就统一把数据上报到这个server服务里来。如此,我们就需要一个【上报层】。
3.4. 上报方案
上报数据的方式可以考虑:
| 上报方式 | 优点 | 缺点 |
| HTTP | 兼容性好,原项目不需要添加其他依赖,用Java原生类库就可以实现。 | 性能一般,且需要自己做超时处理等操作 |
| RPC框架 | 性能比HTTP高,且有完善的框架,可以自动重试、自动熔断 | 需要依赖RPC框架 |
| MQ | 性能高,而且可以享受到MQ的好处,即使server挂了也不影响其他服务 | 需要依赖MQ |
所以性能上的优先级肯定是 MQ > RPC > HTTP,但兼容性方面 HTTP 是最好的。最佳方式肯定是三者都支持,允许服务自定义配置,但默认使用HTTP。
目前我们先考虑实现HTTP的方式,如果整体效果不错,对项目优化有帮助,再考虑实现其他功能。
3.4.1. HTTP上报数据
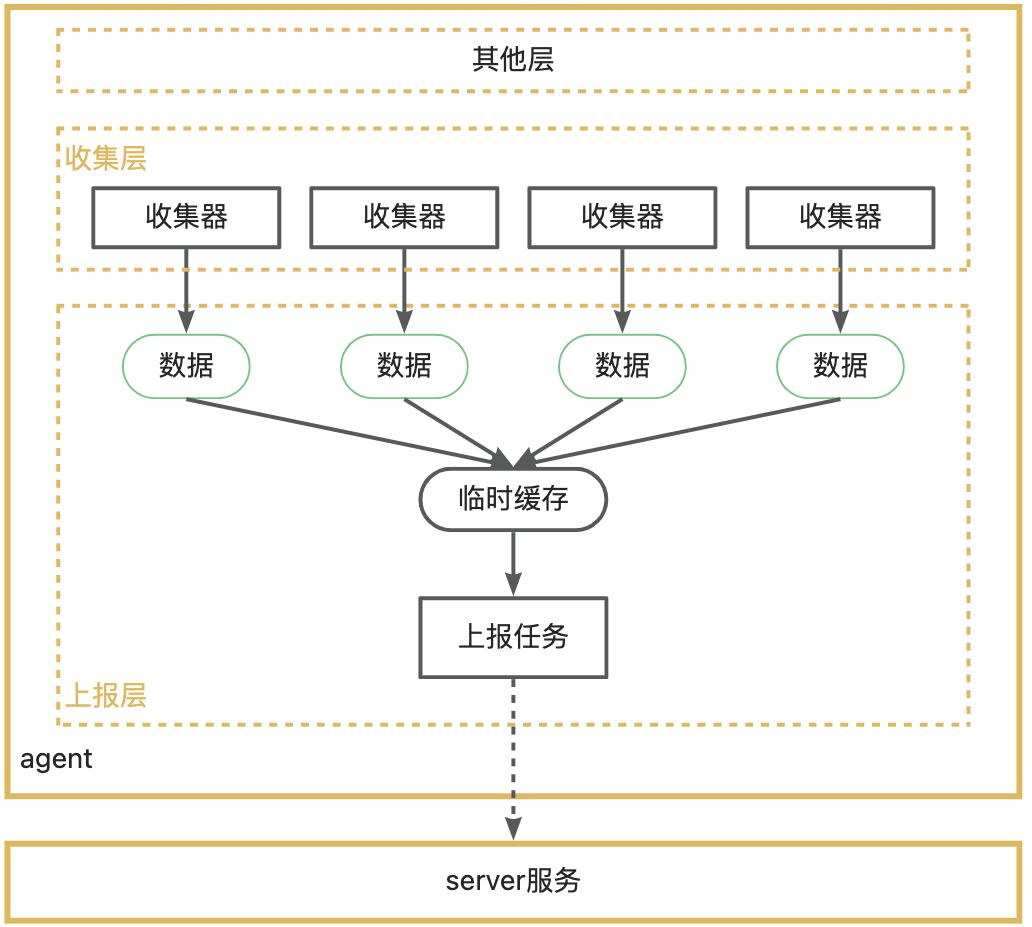
上报数据相对来说是比较耗时的,我们可以使用 异步+批量上报 的方式来尽可能减少对业务的影响。
当收集层把数据传给上报层的时候,我们先存储到一个临时的容器里,每隔一段时间,再单独用一个线程把这段时间内收到的数据进行批量上报。由于收集层是多线程的,所以这个临时的容器需要用线程安全集合类。
上报数据时所开启的HTTP请求不需要等待服务端的返回,只需要发送成功就好了,如此可以更快的完成上报。
核心代码如下:
public class MessageClient {private static final LinkedBlockingDeque<CallStatData> linkDataCache = new LinkedBlockingDeque<>(200);private static URL reportUrl;public static void add(CallStatData linkData) {if (reportUrl == null) {return;}if (linkDataCache.size() > 200) {logger.warn("链路检测服务:缓存数据过多,丢弃数据");return;}linkDataCache.add(linkData);}static {try {// url初始化initUrl();if (reportUrl != null) {// 定时任务初始化initTimer();}logger.info("链路检测服务:MessageClient初始化完成");} catch (Throwable e) {logger.error("链路检测服务:MessageClient初始化失败");e.printStackTrace();}}/*** 上报地址初始化*/private static void initUrl() {// url初始化String url = System.getProperty("callstat.url");if (url == null) {String env = System.getProperty("env");if (env == null) env = System.getProperty("ENV");if (env == null) env = "fat"; // 默认测试环境env = env.toLowerCase();switch (env) {case "dev":url = "http://127.0.0.1:8077/v1/callstat";break;case "fat":default:url = "xxxxxxx/v1/callstat";break;}}try {reportUrl = new URL(url);} catch (MalformedURLException e) {logger.error("链路检测服务:上报地址初始化失败,{}", e.getMessage());}}/*** 定时任务初始化*/private static void initTimer() {// 创建定时器任务TimerTask timerTask = new TimerTask() {@Overridepublic void run() {MessageClient.start();}};ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(1);scheduledThreadPool.scheduleAtFixedRate(timerTask, 1, 2, TimeUnit.SECONDS);}private static void start() {if (linkDataCache.isEmpty()) {return;}logger.debug("链路检测服务:开始发送缓存数据,数量:{}", linkDataCache.size());// 分离缓存数据ArrayList<CallStatData> oldRecords = new ArrayList<>(linkDataCache.size());linkDataCache.drainTo(oldRecords);// 发送数据sendHttpRequests(oldRecords);logger.debug("链路检测服务:发送数据结束");}}3.5. 持久化方案
持久化是在一个独立的server服务中,用来接收所有agent发送的数据。
3.5.1. 直接存
最简单的做法,每一个HTTP请求进来我们都插入一次数据库,就像下面这样:
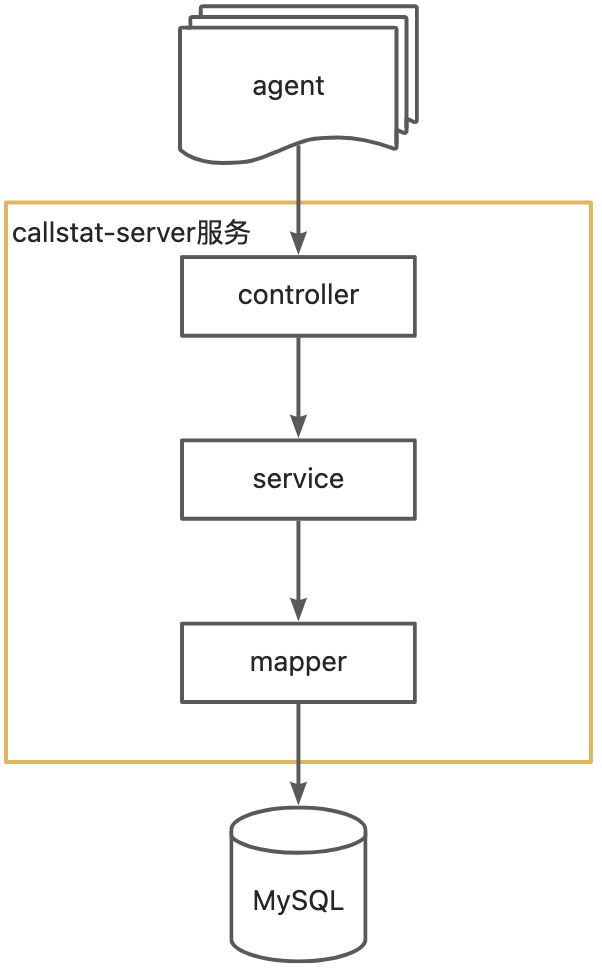
事实上,我还有一个更好更傻逼的方案!MQ!

3.5.2. MQ自产自销
虽然在agent当中强依赖MQ不好,但我们可以在server服务当中依赖MQ,当server接收到数据时,就发送到MQ中,同时自己也去消费该MQ中的消息,属于是 自产自销 。
这样做的好处是可以利用到mq的异步、削峰、限流,从而提高server服务的承受能力,在数据量较大的时候应该会有比较好的表现。大概长这样:
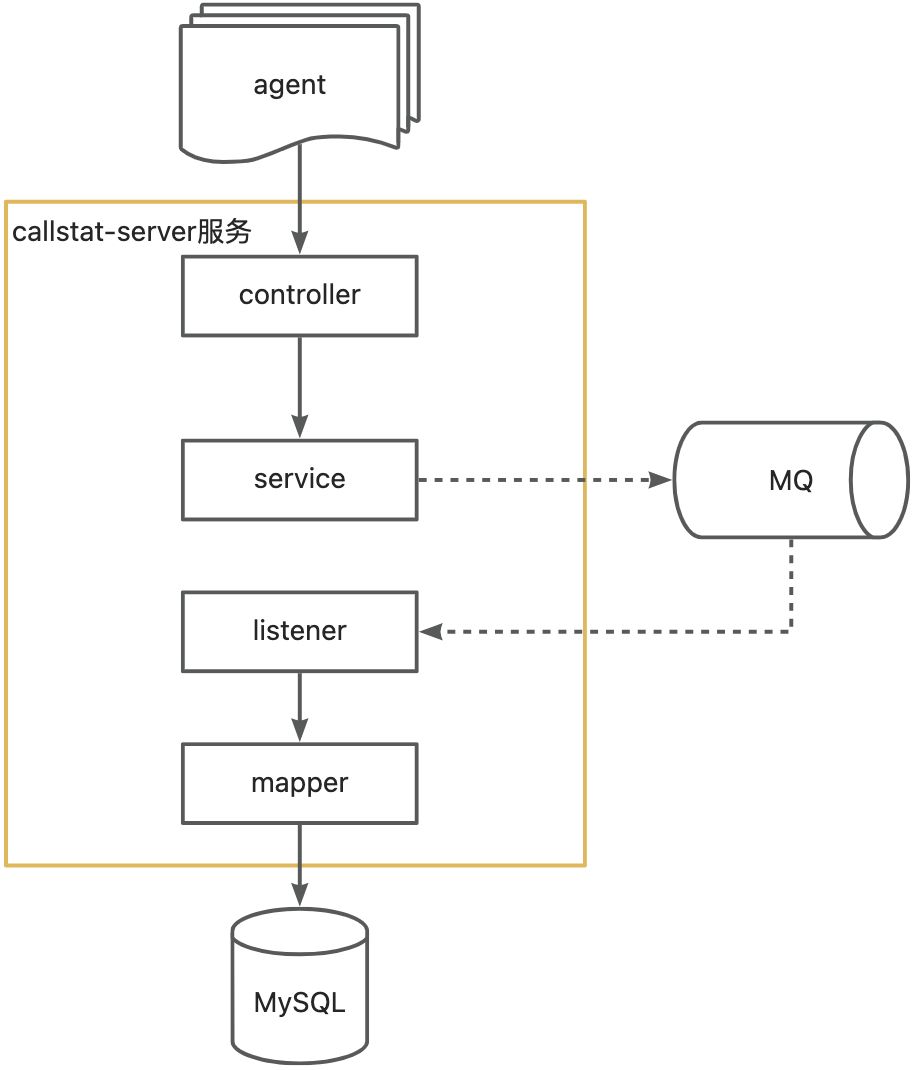
目前我们先采用每次请求都直接落库的方案来实现。
3.6. 展示方案
这一步就很简单了,可以根据自己想要的样子来做,数据都已经有了,取出来处理下,然后输出出来就行,我选择使用 easypoi 来生成Excel。
因为数据是无限,但接口是有限的,所以我们在展示的时候,也可以对每一个接口的数据进行聚合。
最后我们统计的内容有:
- 接口标识
- 类型
- 执行次数
- 平均调用dubbo数
- 最大调用dubbo数
- 平均查询sql数
- 最大查询sql数
- 平均执行耗时
- 最大执行耗时
- 平均入参长度
- 最大入参长度
- 平均出参长度
- 最大出参长度
- 不合理调用情况span列表
核心代码如下:
override fun getReport(): String {val callStatPoList: List<CallStatPo> = callStatMapper.all()val callStatDtoList: MutableList<CallStatDto> = ArrayList(callStatPoList.size)for (callStatPo in callStatPoList) {callStatDtoList.add(toDto(callStatPo))}// 聚合数据val reports = mergeCallStat(callStatDtoList)// 挑出异常数据val errorReports = reports.filter {it.avgCostTime > 500 || it.maxCostTime > 2000 || it.maxArgLength > 1000 || it.maxReturnLength > 1000 || it.maxSpanCallCount > 10|| it.badSpanList.any { span -> span.maxCallCount > 5 || span.avgCostTime > 200 }}.onEach {it.badSpanList = it.badSpanList.filter { span -> span.maxCallCount > 5 || span.avgCostTime > 200 }}// 生成报告val exportParams = ExportParams("服务链路报告", "服务链路报告")exportParams.type = ExcelType.XSSFexportParams.height = 20return exportExcel(exportParams, CallStatReport::class.java, errorReports)
}/*** 聚合数据*/
private fun mergeCallStat(callStatDtoList: List<CallStatDto>): Collection<CallStatReport> {val reportMap = HashMap<String, CallStatReport>()for (stat in callStatDtoList) {val mapKey = stat.transactionType + stat.markval report = reportMap.computeIfAbsent(mapKey) {CallStatReport().apply {this.mark = stat.markthis.transactionType = stat.transactionType}}report.addCallCount(stat.costTime, stat.argLength, stat.returnLength, stat.callStat.dubboCallCount, stat.callStat.sqlCallCount)report.addSpanList(stat.spanList)}return reportMap.values.onEach {it.format()}
}3.7. 效果展示
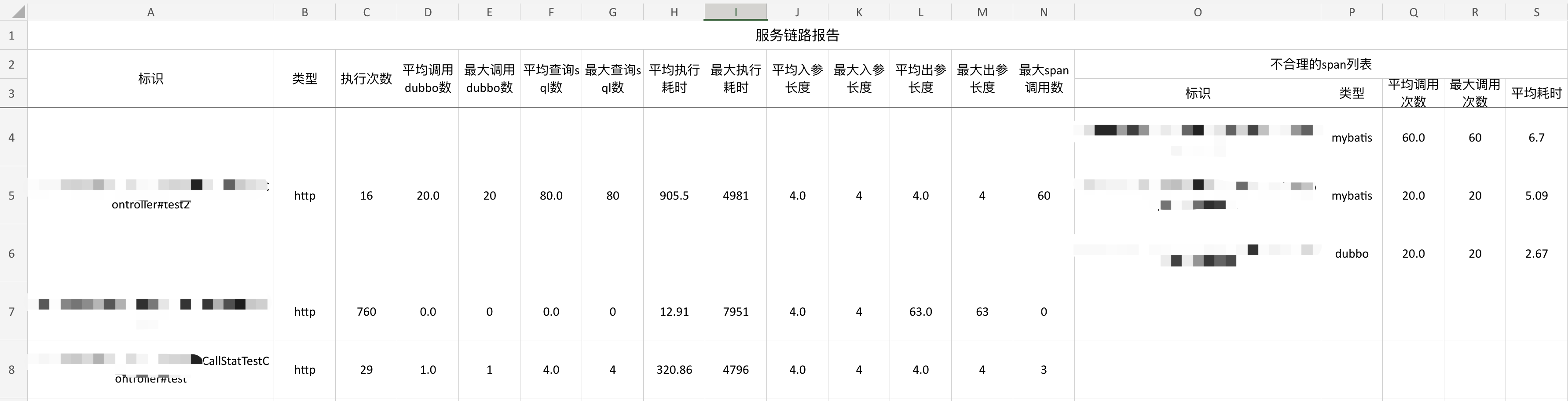
后续可以考虑优化下展示的样式,比如标红异常数据,更加直观的看到那些数据是异常的。
4. 最后
目前我们内部还在试用阶段,如果你觉得不错,可以参考我们的实现思路自己也做一个,没准也能帮你找到一些不合理的代码设计。
虽然但是,这个项目目前还比较简陋,很多地方都不太完善,各位佬有好的建议或者意见都欢迎在评论区提出,我一定积极听取,保证不改。

本来这是我和我导师写的项目,但是看完这篇文章,它也是你的了!
所以
点赞、收藏、关注!












![[深入浅出AutoSAR] SWC 设计与应用](https://img-blog.csdnimg.cn/img_convert/2bd7acf4ec67ae190cb4dc7b0a202941.jpeg)