进程(1)——什么是进程?【linux】
- 一. 什么是进程?
- 二. 管理进程:
- 2.1 怎么管理:
- 2.2 PCB
- 2.3.1 task_struct
- 2.3.2 组织task_struct:
- 三.查看进程
- 3.1 ps ajx
- 3.2 ls /proc
- 四. 父子进程
- 4.1 什么是父子进程
- 4.2 创建子进程——fork()
- 4.2.1 用法
- 4.2.2 刨析fork三个疑问
- i. 为什么要给子进程返回零,给父进程返回pid
- ii. fork怎么返回两次
- iii. 一个变量怎么会有不同的值:
一. 什么是进程?
概念:正在运行的程序
还记得前面讲的冯诺依曼结构吗。
系统的软件和硬件
那里面我们讲了,输出设备和输入设备的数据交互基本都是和内存的
之后cpu从内存中读取数据,在内存中被读取到的程序就可以看作在运行
所以通俗的讲:一个已经加载到内存中的程序,就叫做进程
同时一个操作系统能运行多个进程,这个想必大家也知道
因为在现实中,我们能一边听歌一边玩游戏就是多个进程并行
二. 管理进程:
我们了解了什么是进程后,就要来了解了解
在系统中是如何管理内存中的一个个程序的
2.1 怎么管理:
这里我们要明确一个点:
我们是要对运行的程序进行管理,因为内存中有多个运行程序
我们的管理想法:是对各个运行程序能进行查看和改变他们的状态
但是光靠程序本身的代码和数据不能进行管理
就比如写了一个test.c其中有hello world的程序
当被读取到内存中的时候,还有很多个相同的程序
那如何进行区分,如何找到运行程序在内存中的地址?
这些问题程序本身的数据和代码不能解决的。
所以我们就需要自己给程序添加一些属性。
1.程序在内存中运行的编号(进程编号)
2.程序在内存中的地址
………………
等等
所以说进程不光是被读取到内存中的程序,同时还有为了方便管理而添加的属性

这里我们了解了进程的具体组成后,我们就可以聊聊该如何进行管理了。
这里有一个口诀:先描述再组织
描述:
我们之前做数据结构时,都是先想好管理的类是如何构成的
比如说为了写个学生管理系统,需要在类中塞进学生的各个信息的属性。
组织
管理的类什么样子想好后,就可以进行组织,挑选用什么结构去进行组织管理,链表,顺序表等
系统中的硬件都是这样进行管理的,所以操作系统中有大量的数据结构
所以说进程也是一样,但是进程是在系统中的,系统使用C语言写的,所以不是类,而是结构体
所以进程也是塞进数据结构中的,进程可以说是一个数据结构结构体对象
2.2 PCB
进程进行描述后,就是pcb
PCB是描述进程属性的一个数据结构结构体对象。
PCB结构体中包含了:
1.进程编号
2.进程状态
3.优先级
…………
所以对进程进行管理,就是对PCB进行管理
虽然PCB组织方式有很多,但基本上都是链表,所以管理PCB的本质就是对链表的增删查改
2.3.1 task_struct
在linux中PCB是:task_struct
task_struct 是pcb的一种
属于linux内核中的一种数据结构体对象
创建一个进程就是对task_stuct的实例化
2.3.2 组织task_struct:
linux如何组织进程:
linux内核中,最基本的组织进程task_struct的方式,采用双线链表组织
task_struct本身在双链表中
同时双链表可能处于别的数据结构组织中,所以关系错综复杂
三.查看进程
接下来就该查看系统中的进程了。
这里带来查看进程两种方法:
3.1 ps ajx
ps ajx

这里我们看到了多个进程
同时能看到:ppid pid等进程属性
这里小提一下,上面说了pcb本质在链表中,所以ps本质也是遍历链表
ps ajx | grep 文件名 查找进程:
这里我们发现第二个进程是grep test
正好是我们执行的代码,这是因为执行grep操作时,grep本身也变成了一个进程。
3.2 ls /proc
ls /proc
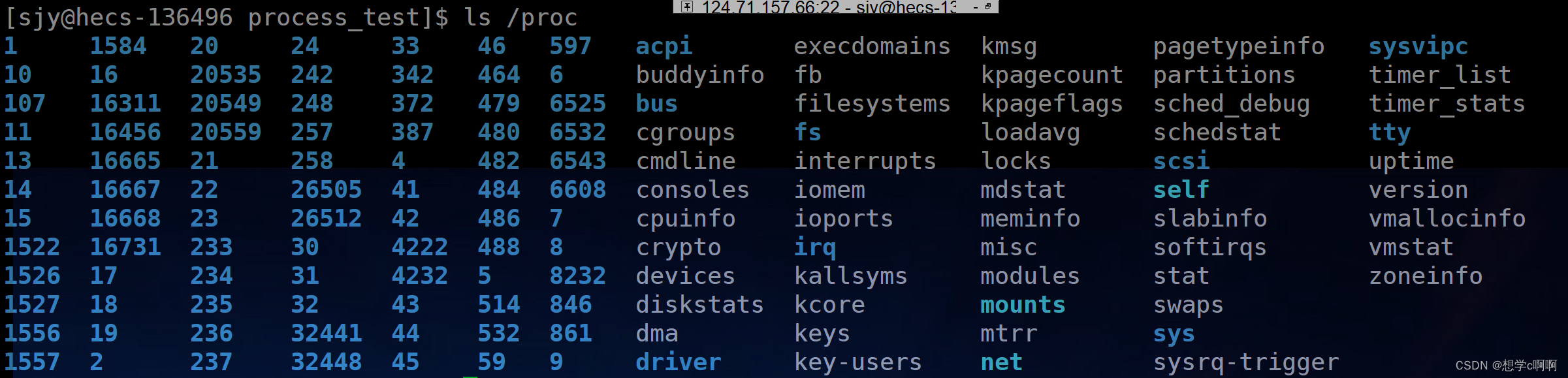
这里我们能看到大量的数字
这是因为:在proc目录中会给每一个正在运行的进程创建一个以他们的(进程编号)pid进行命名目录
同时:目录中有进程的属性,当进程结束了以后proc中的文件会进行对应进程的文件夹删除。
查看进程属性名
ls /proc/进程pid -l
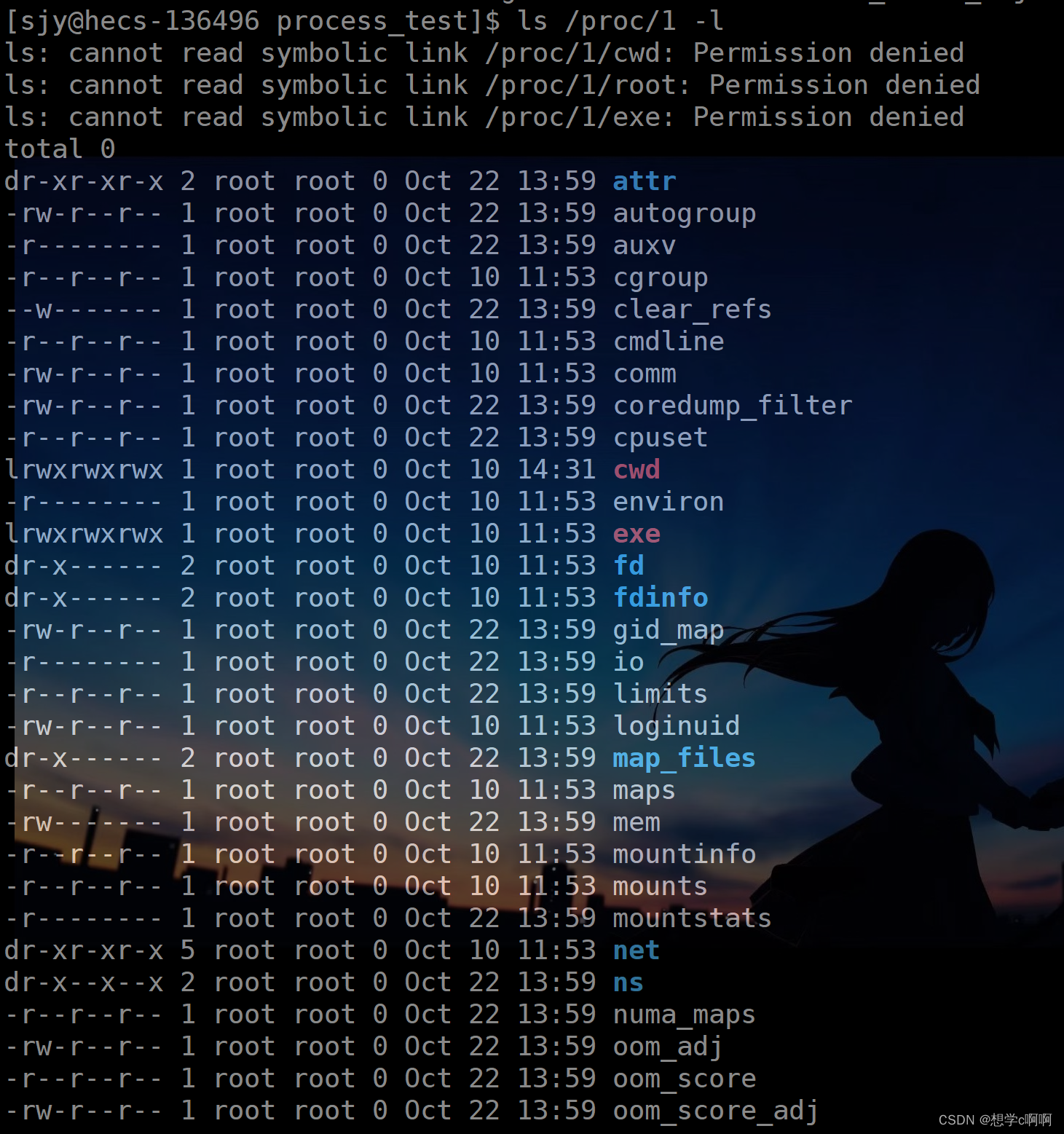
这里注意一下这个cwd
(current work dir)cwd:当前进程的工作目录(进程启动时,记录下来的文件所在目录)
这就是有时候用部分文件操作指令时,不需要输入目录,而是默认在当前文件的目录下执行,这是因为进程记录了当前的运行目录
四. 父子进程
4.1 什么是父子进程
pid:进程编号,每个进程都有属于自己的编号,便于管理
获得自己的pid:
getpid

ppid 父进程:可以认为时父进程中衍生出来的子进程
getppid
用法与子进程一样
这里我们让他们进行父子同台一下。
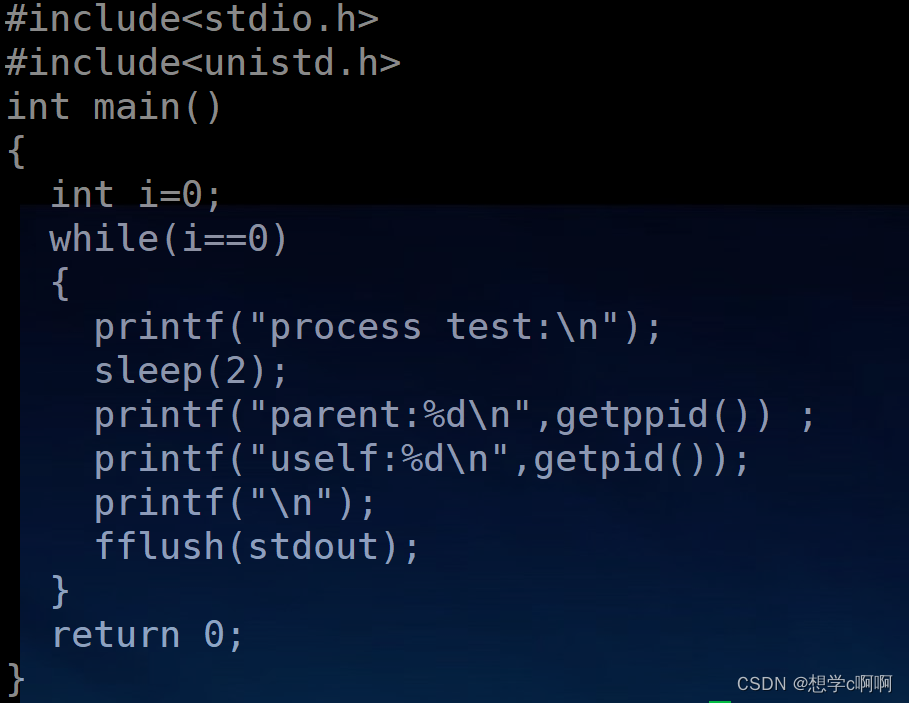
用这个文件进行测试一下。
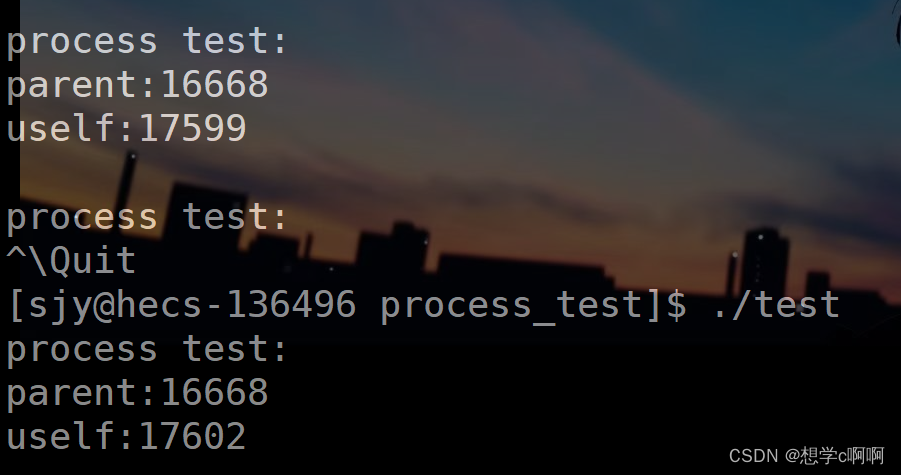
这里能发现每一次重新执行程序,父进程编号不变,子进程编号会变
这里我们来查看一下父进程是谁
ps axj | head -1 && ps -axj | grep 16668
这里&&代表两边指令都要执行
搜索出来:
16668是bash进程

bash是命令解释器,相当于充当用户和系统的中介,这个在之前的博客提到过。
我们所有在命令行打出的指令的父进程可以说都是bash的子进程。
4.2 创建子进程——fork()
fork()创建一个子进程——代码级别创建子进程
这里的fork不同于我们平常在指令出用的 ./
fork是在代码处使用的。
4.2.1 用法
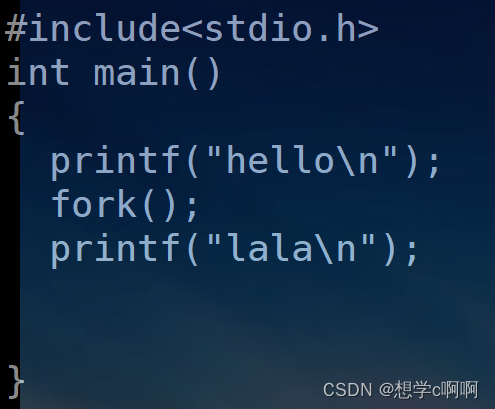

这里我们能发现这后面的lala,多打印了一遍。
说明创造出来的子进程,是从创造出来的位置执行代码的
fork具有返回值:
在父进程中,fork返回新创建子进程的进程ID;
在子进程中,fork返回0;
如果出现错误,fork返回一个负值
这里我们就用这个文件进行测试一下
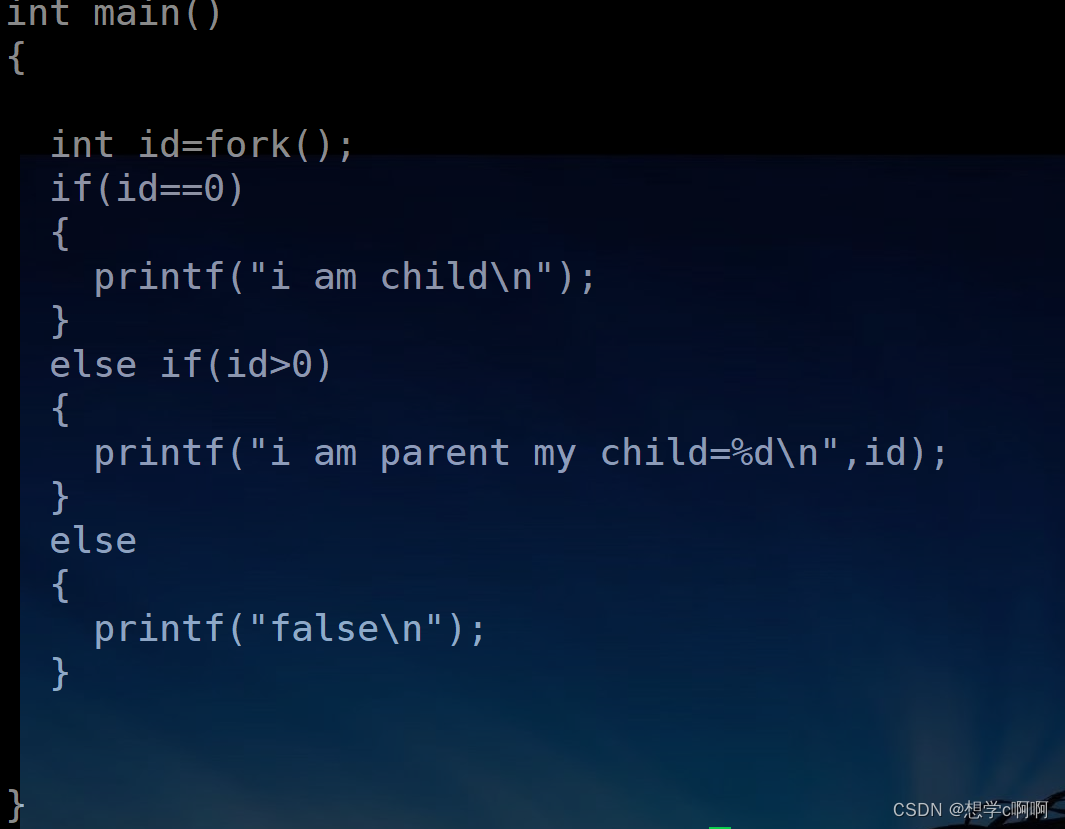

这里我们可以提出三个疑问了
1.为什么要给子进程返回零,给父进程返回pid
直接返回一样值不行吗?
2.fork怎么返回两次
fork明明就是一个函数是怎么做到返回两次的。
让父进程和子进程都接收到值
3.一个变量怎么会有不同的值
这个返回值为什么有不同的情况
4.2.2 刨析fork三个疑问
i. 为什么要给子进程返回零,给父进程返回pid
从前面我们知道fork之后的代码子进程和父进程共享
但是我们创建父子进程就是为了让他们干不同的事
因为fork之后代码共享,所以为了区分子进程和父进程,来让两个进程进入执行不同的代码,
所以返回不同的返回值,区分不同的进程流,执行不同的代码块(加了筛选条件,if while等)
ii. fork怎么返回两次
要回答这个问题的话需要了解fork这个函数到底是如何执行的。、
当在fork中将pcb创建完了后,
子进程就已经成为一个单独的进程,能被系统进行调用。
所以执行return的语句之前,子进程和父进程就已经代码块共享了
所以能执行return语句,就返回了两次。
iii. 一个变量怎么会有不同的值:
这里也可以理解为:
子进程和父进程的数据(变量)到底共享还是独有
因为进程的组成有:
数据和代码+pcb
两个进程的pcb已经复制,代码共享
接下来就是数据:
对于进程来说每个进程都具有独立性,都能单独进行运行
数据可能被进行修改,所以为了不影响两个进程的数据导致代码运行(保证进程独立性),所以两个进程的数据不能进行共享
所以子进程和父进程的数据是独立的,但是如果父进程有大量的数据,可能子进程压根就用不上,就会导致大量的内存流失。
所以在最开始的时候父进程和子进程数据代码都是共享的
但是当子进程尝试去修改父进程的变量时候,编译器会创建一个对应变量的空间,同时给子进程专门拷贝父进程对应的变量
可以称为写时拷贝。