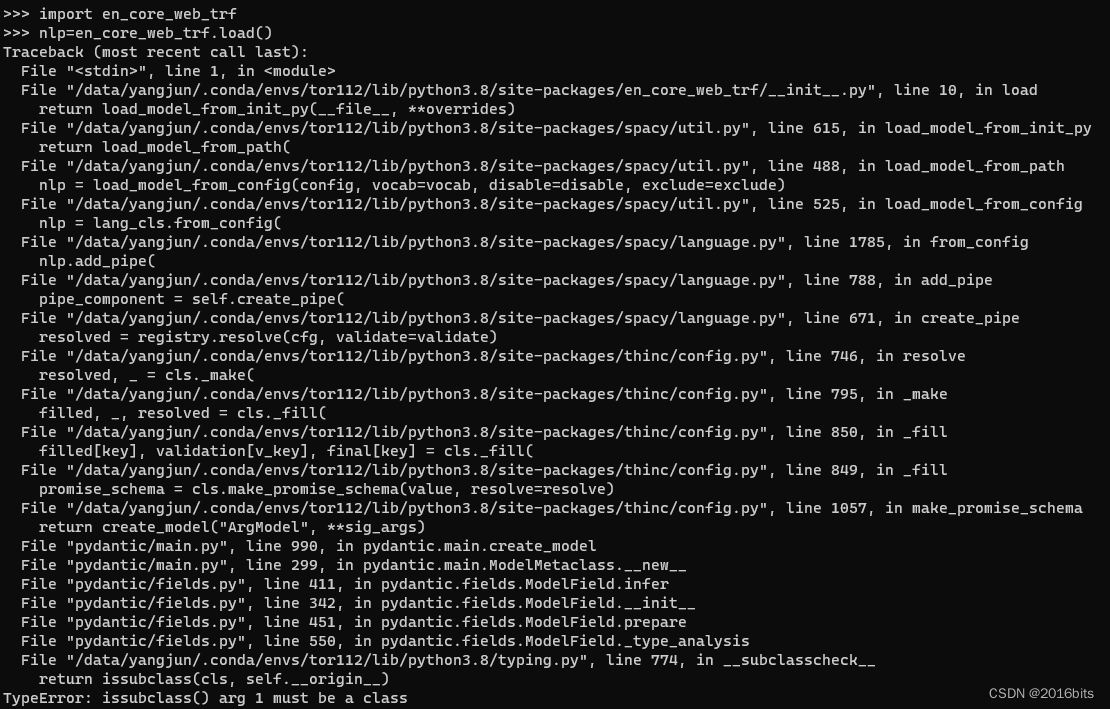
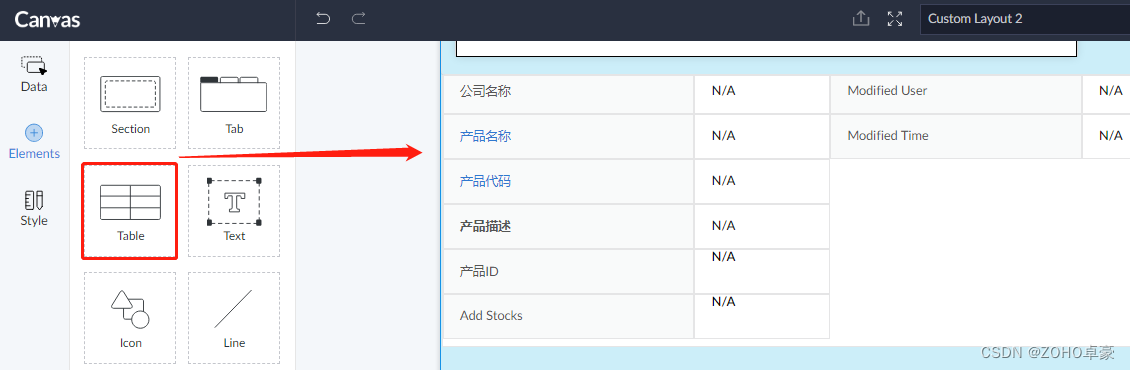
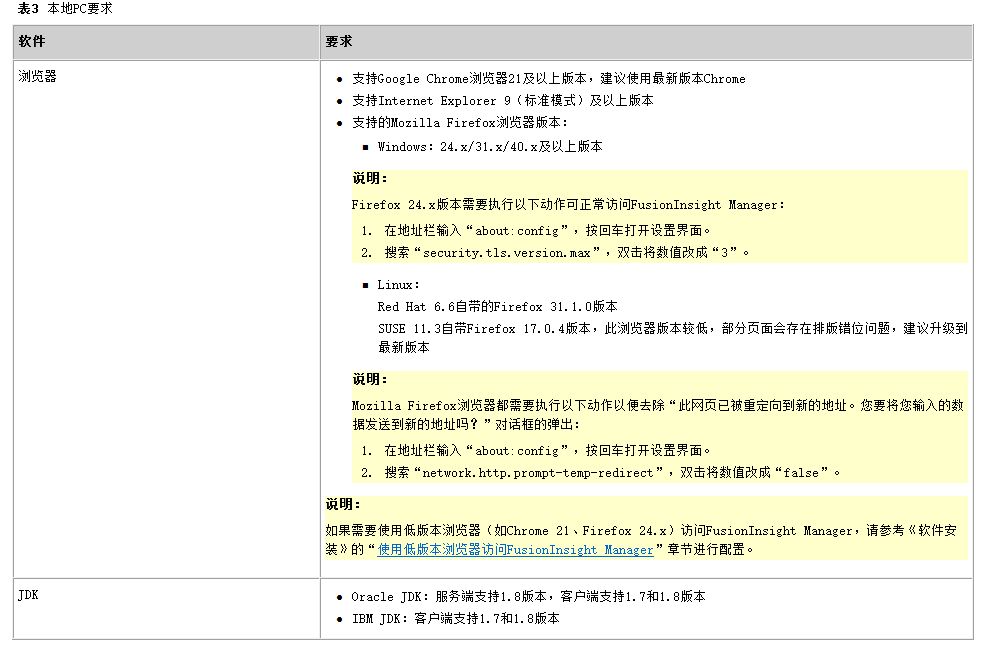
🔥 🔥🔥
github: https://github.com/declare-lab/tango
效果:https://tango-web.github.io/
论文地址:https://arxiv.org/pdf/2304.13731.pdf
数据集audiocaps下载: https://blog.csdn.net/weixin_43509698/article/details/131406337
任务描述: 文本输入生成音频,例如输入A bird is whistling.,结果会输出一只小鸟在鸣叫的声音
训练心得: audiocaps下载完成后需要按data下的json文件将音频文件的名称修改为json中的名字,即 YouTube_ID ,将音频文件采样成单通道的16KHz的文件,并根据实际修改json文件。
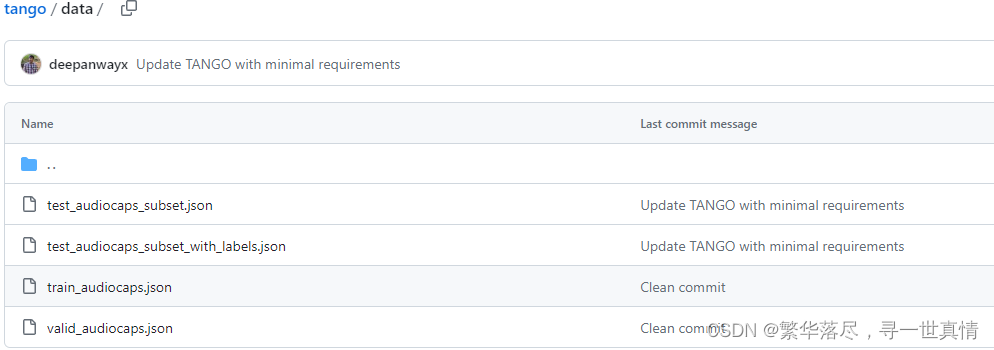
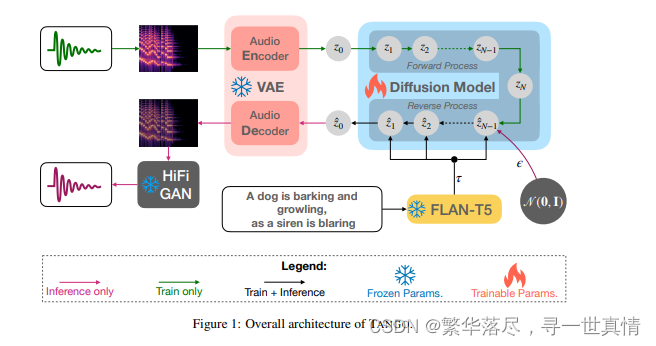
文生音频的模型架构图:
摘 要
最近的大型语言 型(LLM)允许许多有趣的属性,例如,基于指令和思想链的微调,这在许多自然语言处理(NLP)任务中显著提高了零样本和少样本(Zero-Shot和Few-Shot)性能。 受这些成功 的启发 ,我们采用了这 样 一个指令调优的LLM FLAN-T5 作为文本到音频(T T A)生成的文本编码器,该任务的目标是从文本描述生成音频。先前在TT A 上的工作要么预先训练一个联合文本-音频编码器,要么使用非指令调优模型 ,如T5。因此,我们基于潜在扩散模型(LDM)的方法 (TANGO 在大多
数指标上优于最 先进 的 AudioLDM,并且在 AudioCaps 测试集上保持可比性, 尽管在小 63 倍 的 数 据集上训练LDM并保持文本编码器冻结 。 这种改进也可能归因于在训练集中采用了基于音频压力的增强 , 而之前的方法采用随机混合。
1 介绍
随着文本到图 像 (TTI )自动生成的成功 [31-33], 许 多研究人员采用与 前 者类 似的 技术 , 也成 功地 进行了 文 本 到音 频 (TT A )生 成[17,18, 43]。 这 样 的 模型 在 媒 体制 作 中 可能 有 很强 的 潜 在价值,因 为 创作者 总是 在 寻找 适 合他 们创 作 的新 颖声 音 。这 在 原型 制作 或 小规 模项 目 中尤 其 有用 ,因 为 制作 精确的声音可能 是不 可行的 。除 此之外 ,这 些技术 还为 通用的 多模态 A I 铺 平了道 路, 可以同 时识 别和生成多种模态。
为此 ,现 有 的作 品使 用了 大 型文 本编 码 器, 例如 , RoBERTa[ 19]和 T5[3 0], 对 要生 成的 音频 的 文本描 述 进行 编码 。 随后 , 大型 变压 器 解码 器 或扩 散模 型 生成 音 频先 验 ,随 后由 预 训练 的 VAE 解码, 然 后是 声 码 器。 相 反, 我 们假 设 用指 令 调优 的 大 型语 言 模型 (L L M)替 换 文 本 编码 器 将提 高 文本理 解和 整体 音频 生 成, 而无 需任 何 微调 ,因 为它 最近 发 现了 梯度 下降 模 仿特 性[4]。为 了 增强 训练样 本, 现 有的 方 法采 用随 机 生成 的音 频 对组 合, 以 及它 们 的描 述的 串 联。 这样 的 混合 并没 有 考虑 到 源 音 频 的整 体 压 力 水 平 , 可 能 会 导 致 更 大声 的 音 频 压 倒 更 安 静 的 音 频 。 因此 , 我 们 采 用 了Tokoz um e 等人 [3 9]建 议的 基 于压 力水 平的 混合 方法
我们 的模 型 (TA N G O )受到 1 潜 在扩 散模 型 (L D M)[3 3]和 Au dioL D M[ 18]模型的启发。然而 ,我 们没 有使用 基于CLAP 的 嵌 入, 而是 使用 了大 型语 言模 型 (LL M), 因 为 它具 有强 大的 表征 能力 和微 调机 制,可以 帮助 学 习文 本 描述 中的 复 杂概 念。 我 们的 实验 结 果表 明 ,使 用 LL M 大 大 提 高 了文 本到 音 频的生 成, 并 且优 于最 先 进的 模 型, 即使 在 使用 显着 较 小的 数据 集 时也 是如 此 。在 图 像生 成文 献 中,之前 已经 有撒 哈拉 等人 研究 过 LL M 的 效 果。 然而 ,他 们认 为 T5 是 文本 编码 器, 它没 有在 基于 指令的 数据 集上 进行 预训 练。 FL A N-T5[3]使 用 T5 检 查点 初始 化, 并 在 1.8 K NL P 任 务的 数据 集上 进行指 令和 思维 链推 理的 微调 。 通过 利用 基于 指令 的调 优, FL A N-T5 在几个 N LP 任 务上 实 现了 最先进的性能,与具有数十亿参数的 llm 的 性能 相匹 配。
在 第 3 节中 , 我 们通 过 经验 证 明, 尽 管 L D M 在 小 63 倍 的 数 据 集 上进 行 训练 , 但 T A N G O 在Au dioCa ps 测 试集 的 大多 数 指标 上都 优于 Audio L D M 和 其 他 基线 方法 。 我们 相 信, 如 果 TA N G O在更大的数据集 (如 AudioSet )上进 行训 练 (如 Liu et al.[18]所做的), 它 将能 够提 供更 好的 结果 ,并 提高 其识别更广泛声音的能力。
本文的总体贡献有三个方面:
1.我 们不 使 用任 何联 合 文本 -音 频编 码器 (如 CLAP)作 为 指 导。Liu 等 人 [18]声 称 ,为 了 获得 更好 的 表现, 在 训 练过 程 中 基 于 CLAP 的 音 频 指 导 是必 要 的 。在 训 练 和推 理 中 ,我 们 使 用了 一 个冻 结 指 令调整的预训练 LLM FLA N-T 5, 它具 有很 强 的文 本 表示 能力 , 用于 文本 指 导。
2.A udioL D M 需 要 微调 RoBE RT a[1 9]文 本编 码器 来预 训练 CL AP。 然而 ,我 们在 L DM 训 练 期间 保持 FLA N-T5 文 本 编码 器冻 结。 因此 ,我 们发现 L D M 本 身能 够从 一个比 A udioL D M 小 63 倍的 训练集中学习文本到音频的概念映射和组合, 给定 一个 指令 调谐 的 LL M。
3.为 了混 合 音频 对 以增 强数 据 , 受 Toko zu m e 等 人 的启 发 ,我 们考 虑 音频 对 的压 力水 平 ,而 不 是像 AudioL D M 这样 的 随机 组合 。 这确 保了 融 合音 频中 两 个源 音 频的 良好 表 示。
2 方 法
如图 1 所 示 , TANGO 有 三 个 主 要 组 成 部 分:1)文本编码器, 2)潜 在 扩 散 模 型( LDM ),以及3) and iii) mel-spectogram/audio VAE。文本编码器对音频的输入描述进行编码。随后,使用文本表示 从 标 准 高 斯 噪 声 中 构 建 音 频 或 音 频 先 验 的 潜 在 表 示 , 使 用 反 向 扩 散 。 然 后 , mel-spectogram VAE 解 码 器 根据 潜 在 音频 表 示构 建 mel-spectogram。该梅尔谱图被 馈 送到 声 码 器以 生 成最 终 的 音频。
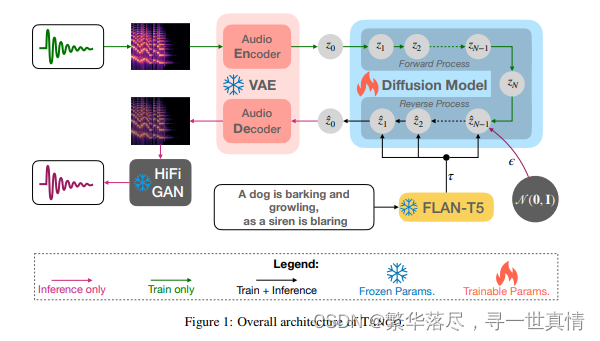
2.1 文本提示编码器
我 们 使 用 预 训 练 的 LLM FL A N-T5 -L A R G E(780 M )[3] 作 为 文 本 编 码 器 (E) ,得到 t ex t 文 本 编 码τ∈ RL× d,其中 L 和 dtext分 别为 令 牌 计数 和 令牌 嵌入 大 小。 由于 在 大规 模 思维链 (CoT)和基于指令的 数 据 集上 对 FL A N -T 5 模 型 进 行 了预 训 练 ,Dai 等 人[[4] ]假 设 它 们能 够 通 过注 意 力 权重 模 拟梯 度 下 降 , 从上 下 文 信 息 中 很 好 地 学 习 新 任务 。 这 一 特 性 在 较 老 的 大 型 模 型中 是 缺 失 的 , 例 如RoB ER T a [ 19] ( Liu 等人 使 用的 [18] )和 T5 [3 0] ( Kr euk 等 人 使用 的[17])。 考 虑 到每 个 输入 样本 都 是一 个 不 同 的 任务 , 我 们 可 以 合 理 地 假 设 梯 度下 降 模 拟 特 性 在 不 微 调 文 本 编 码器 的 情 况 下 , 在 学习 文 本 和 声 学概 念 之 间 的 映 射 方 面 可 能 是 关键 的 。 更 丰 富 的 预 训 练 也 可 能 允许 编 码 器 以 更 少 的噪 声 和 丰 富 的上 下 文 更 好 地 强 调 关 键 细 节 。这 再 次 可 能 导 致 将 相 关 的 文 本 概念 更 好 地 转 化 为 声学对 应 物。 因 此, 我 们将 文 本编 码 器保 持 冻结 状 态, 假 设随 后 的反 向 扩散 过 程 (参见第 2.2 节 )能够在 构 建之 前很 好 地学 习 音频 的模 态 间映 射 。我 们还 怀 疑微 调 可能会降低 其上 下 文学 习 text能力 ,因 为 音频 模 态的 梯度 不 在预 训 练数 据集 的 分布 范围 内 。这 与 Liu 等人的[18]形 成 对比 , 他们对 预 训 练的 文 本 编码 器 进 行微 调 , 将其 作 为 文本 -音 频 联 合 表示 学 习(CL AP )的 一 部 分, 以 允 许从文 本中 预 先重 建音 频 。在 第 3 节 中, 我 们通 过经 验 证明 ,这 种 联合 表 示学 习对 于 文本 到音 频 的转换可能不是必需的。
2.2 文 本引导生成的潜在扩散模型
潜在扩散模型 (L D M)[33]改编自 Liu 等人的 [18],目的 是在文本编码 τ 的指 导下构建音 频先验 z0 (见第 2.5节)。这本质上简 化为用参数 化的 pθ (z0|τ )近似真实先 验 q(z0 |τ )。LD M 可 以通 过正 向和 反向扩 散过 程来 实现 上述 功能 。正向 扩散 是一 个预 定噪 声参数 为 0 <1 2 β<
β<···< β<N 1 的高斯分布的马尔可夫链到 z0 的样本噪声版本


用 U- N et[34]对 噪 声估 计 θ 进行 参数 化, 并加 入交 叉关 注分 量, 以包 含 文本 指导 τ。 相比 之下 ,Au dioL D M[ 18]在 训 练过 程中 使用 音频 作为 指导 。在 推 理过 程中 ,它 们切 换回 文本 指导 ,因 为这 是通过 预先 训练 的联 合文 本音 频嵌 入 (CL AP)来 促 进的 。 如 2.1 节 所述 ,我 们没 有发 现音 频指 导训 练和预训练 CLA P 是 必要 的。
2.3 增强
许多文本到图像 [28 ]和 文 本 到 音 频[ 17 ]的 工 作 已 经 显 示 了 使 用 基 于 融 合 的 增 强 样 本 进 行 训 练 以提高扩散网络的跨模态概念组成能力的有效性。因此,我们通过将现有音频对相互叠加并连接其字幕来合 成额 外 的 文 本 -音频对。与 Liu et al.[18]和 Kr euk et al.[1 7]不 同的 是, 为了 混合 音频 对, 我们 不会 随机 地将 它们 组合 起来 。根据 To koz um e 等 人 的 研究 ,我 们 转而 考虑 人类 听 觉感 知的 融 合。 具体 来 说, 我们 考 虑了 音频 压力水 平 G, 以 确 保高 压 水 平的 样 本 不会 压 倒 低压 水 平的 样 本 。音 频 样 本的 权 重(x1 )计 算 为 相对 压力级(其分布参见附 录中 的图 2 )
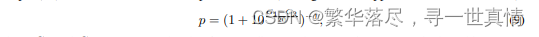
式 1 中,2 分别为两个音频样本的压力级 x1 and x2。这确保了两个音频样本的良好表示,后混音
此外,正如 Tokozum e 等人 b [39]所指 出的,声波的 能量与其振 幅的平方成 正比。因此 ,我们将 x1and x2 as 混合
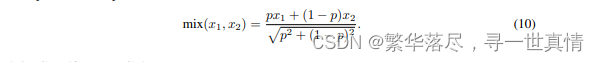
2.4 无分类器引导
为了引导反向扩散过程重构音频先验 z0,我们采用 文本输入 τ 的无分类器引导 [7]。在推 理过程中,
相对于传递空文本的非引导估计 θ,一个引导尺度 w控制了文本引导对噪声估计的贡献 λ,其中:
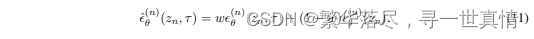
我们 还 训练 了 一 个模 型 ,在 训 练过 程 中 , 10 %的 样 本 的文 本 指导 被 随机 丢 弃 。我 们 发现 这 个模 型的表现与一个总是对所有样本使用文本引导的模型相当。
2.5 音 频 VAE和 声码器
音频 变 分 自编 码 器Avariational auto-encoder (VAE)[ 13]将音频样本 m∈ R T× F 的 频 谱 压缩 为 音频先 验 z0∈ R C ×T / r× F/ r,其中 C、 T、 F、 r 分 别 为信 道 数、 时 隙 数、 频 隙数 和 压 缩级 别 。 L D M(参 见2.2 节 )使用输入-文本 引 导 τ 重建 音 频先 验 z0 - uuu。 编 码 器 和 解码 器 由 ResUNet 块 [1 5]组成,并通 过 最 大化 证 据下 界 (E L B O)[ 13]和 最 小 化 对 抗性 损 失[9]进 行 训 练。 我 们 采用 Liu 等人 b[ 18]提供的 音 频 VAE 检 查 点 。 因 此 ,我 们 使用 他 们 的最 佳 报告 设 置 ,其 中 C 和 r 分别被设置为 8 和 4。作为将 音频 - va e 解 码器 生成 的 mel-spectogram 转 换为 音频的声码器 ,我们也使用 HiFi-G A N [14]作为 Liu 等人的 [18 ]。
3 实验
3.1 数据集和训练
Text-to-Audio生成。 我们在 AudioCaps 数据集 [12 ]上 执 行主 要 的 文本 到 音频 生 成 实验 。 该数 据 集包 含 45,4 38 个 音 频 片 段 , 与人 工 编 写 的训 练 字 幕配 对 。 验 证集 包 含 224 0 个 实 例 。 音 频片 段 长10 秒,从 Y ou Tu b e 视 频 中收 集 。 这些 片 段最 初 是 众包 的 ,作 为 音 频分 类 任务 中 更 大 的 AudioSet数据集[5]的 一部 分 。
我们 只使 用来 自 Audio Caps 数 据 集的 成对 (文 本、 音频 )实例 来训 练 L D M。 我 们使 用 Audio Caps 测试集 作为 评估 数据 。 测试 集为 每个 音频 片 段包 含五 个人 工编 写 的字 幕。 为了 与 Liu 等 人的 工作 保持一 致 的评 价 ,我 们对 随 机选 择 的每 个 片段 使 用一 个标 题 。随 机 选择 的 标题 被 用作 文本 提 示, 我们使用它从我们的模型中生成音频信号。
音 频 VAE 和 声 码 器。 我们使用 Liu 等 人 的 音 频 V AE 模 型 。 这 个 VAE 网络是在 A udioSet 、Au dioCa ps、 Freeso und2 和 BBC 音效库 3 (SFX )数 据集 上训 练的 。 Freesou nd 和 B BC SF X 中 较 长的音频 片段 被截 断到前 30 秒 ,然 后分 成三 个部 分, 每个 部分 10 秒。 所有 音频 片段 以 16K Hz 频率重新采样,用于训练 VA E 网络 。我 们 对 VAE 网 络使 用 4 级 压缩 和 8 个 潜在 通道 。
我们 还使 用 Liu 等人 [18]的 声 码 器, 从 V AE 解 码 器 生成 的 mel 谱 图生 成音 频 波形 。声 码 器是 在Au dioSet 数 据集 上 训练 的 HiFi-G A N [1 4]网 络 。所 有音 频 片段 在 16 K Hz 重 新 采 样以 训练 声 码器 网络。
模 型 、 超 参数 和 训 练细 节 我们将 FL A N-T5-L A R GE 文本 编 码器 冻结 在 T A N G O 中 ,只 训练 潜在 扩 散模型 的参 数 。扩 散模 型 基于 稳 定扩 散 U- N et 架 构 [33,34],共有 866 M 个 参 数 。 我们 在 U- N et 模 型中使用 8 个通道和 1 024 个 交叉 注意 维 度。
我们使用学习率为 3e-5 的 Ada m W 优化器 [20]和线性学 习率调度器 进行训练。 我们在 AudioCaps 数据集上训练 了 40 个 epoch 的 模型,并报 告了具有最 佳验证损失 的检查点的 结果,这是我 们在 epoc h39 获得的。我 们使用四 个 A6000 gp u 来训 练 TA N G O,总共需 要 52 小时来训 练 40 个 epoch,在 每个 epoch 结 束时进行验 证。我们使用 每个 GPU 批处 理大小为 3(2 个 原始实例 + 1 个增 强实例 ),具 有4 个梯度累积步骤。训练的有效批大小为 3 (instan ce)∗ 4 (accum ulation)∗ 4 (GPU) = 48。
3.2 基 线 模型
在我 们的 研 究中 ,我 们 检查 了 三种 现有 模 型:Y ang 等人的 DiffSo und, K re uk 等 人的 Audio G en, Liu等人 的 A udioL D M。 A udio G en 和 DiffS oun d 使 用文 本 嵌入 进行 条 件生 成训 练 , 而 Audio L D M 使用音 频嵌 入 来避 免配 对 文本 音 频数 据中 弱 文本 描述 的 潜在 噪声 。 A udioL D M 使用来自 C L AP 的 音频嵌 入 ,并 断 言它 们 在捕 获 跨模 态 信息 方面 是 有效 的 。这 些 模型 在 大型 数 据集 (包 括 A udioS et)上进行 了预 训 练, 并在 评 估前 对 A udioC aps 数 据 集 进行 了 微调 ,以 提 高性 能。 因 此, 将它 们 与我 们的 TANGO 模 型进 行 比较 并不 完 全公 平 。
尽管 在一 个 小得 多的 数 据集 上 训练 ,我 们 的模 型 T A N G O 优于 在 大得 多的 数 据集 上 训练 的基 线 。我们 可能 在 很大 程度 上 将此 归 因于 LL M FL A N -T5 的 使 用 。因 此 ,我们的 模型 T A N G O 将自己与现有的三个模型区分 开来, 使 其成 为该 领 域当 前研 究 的一 个令 人 兴奋 的补 充。
值得 注意 的是 , Liu 等人 [18]的 A udioL D M -L -Full-F T 检 查点 在 我们 的研 究中 不可 用。 因此 ,我 们使 用了 由 作 者 发 布的 Audio L D M-M-F ull-F T 检 查 点 , 该 检查 点有 416 M 个参数。这个检查点在Au dioCa ps 和 M usicCa ps 数 据集 上进 行了 微调 。在 我们 的研 究中 ,我 们使 用这 个 检查 点进 行了 主观评 估。 我们 尝试 对 Au dioCap s 数 据集 上的 AudioL D M -L -Full 检查 点进 行微 调。 然而 ,由 于缺 乏关于所使用的超参数的信息,我们无法重现 Liu 等 人的 研究 结果 。
我 们 的 模 型 可 以 直 接 与 audio c m - l 进 行 比 较 , 因 为 它 具 有 几 乎 相 同 数 量 的 参 数 , 并 且 仅 在Au dioC aps 数 据集 上 进行 训练 。 但值 得注 意 的是 , Liu 等人 [18]并 没 有 释放 该 检查 点 ,这 使得 我 们无法对其生成的样本进行主观评价。
3.3 评价指标
客观的评价。 在这项工作 中, 我 们使 用了 两个 常用 的 客观 指标 :Frech et 音频 距离 (F A D)和 KL 散度。FA D[1 1]是 一种 感知 度量 ,改 编 自 Fech et Inc eption Distanc e (FI D ), 用于 音频 域。 与基 于参 考的 指标不 同, 它 在不 使用 任 何参 考 音频 样本 的 情况 下测 量 生成 的音 频 分布 与真 实 音频 分 布之 间的 距 离。另一 方 面 , K L 散 度[43,17 ]是 一 种 依 赖于 参 考的 度 量 ,它 根 据 预训 练 的分 类 器 生成 的 标 签计 算 原始音 频样 本和 生成 音频 样本 分布 之间 的散 度。 虽然 FAD 更 多 地 与人 类感 知有 关,但 K L 散 度捕 获了原 始 音频 信 号和 生成 音 频信 号 之间 基 于它 们 所存 在 的广 泛概 念 的相 似 性。 除 了 FA D 外,我们还使 用 Fre ch et 距 离 (FD)[ 18]作 ** 客观 指标 。** F D 与 FA D 相 似, 但它 用 PA N N 代 替了 V G Gish 分 类器。在 FA D 和 F D 中 使 用不 同的 分类 器使 我们 能够 使用 不同 的 特征 表示 来评 估生 成的 音频 的性 能。
主 观评 价。 继 Liu 等人 [18]和 Kre uk 等 人 [17]之后 ,我 们要求 六名 人类评 估人 员评估 30 个随 机选 择的基线 和 tang o 生成的音 频样 本的两 个方 面—— 整体 音频质 量 (O VL)和 与 输入 文本的 相关 性 (REL),范围从 1到 100。 评估 者精 通英语 ,并 被很好 地指 导做出 公平 的评估 。
主要的结果。 我们 在 表 1 中 报 告 了 我 们 的 主 要 比 较 研 究 。 我 们 将 我 们 提 出 的 T A N G O 方 法与DiffSo und [43 ]、 Audio G en [17 ]以 及 Au dioL D M [1 8]的各种配置进行了比较。在推理过程中,Au dioL D M 从 L D M 中采样 20 0 步 获 得 了 最 佳结 果 。 为 了公 平 比 较 , 我们 还在 T A N G O 和其他Audio L D M 实验中 使用了 200 个 推 理 步 骤 。 我 们 对 TA N G O 使 用 无 分 类 器 的 指 导 等 级 为 3。Audio LD M 在 他们 的各 种 实验 中使 用 了 {2,2 .5,3 }之 间的 指 导量 表。
当 仅在 Audio- Cap s 数 据 集 上训 练 时 ,TA N G O 在 客 观 指 标上获得 了新 的 最 先 进的 结 果 ,得 分 为24.52 F D, 1.37 KL 和 1.5 9 F A D。 这 明显 优于 最直 接的 基线 au diocd m - l, 后者 也只 使用 A udioCa ps数据 集进 行 L DM 训 练 。我 们将 此归 因于 在 T A N G O 中使用 FLA N -T5 作 为文本编 码器 。我 们 还注意到, TA N G O 的 性 能匹 配或优于 Audio L D M-* -F T 模 型 ,后 者使 用了 显著 (~ 63 倍 )更 大的 数据 集进 行L D M 训练。 Audio L D M-*-F T 模 型 使用 了两 个阶 段 的 L D M 训 练— —首 先 在四 个数 据集 的集 合 上,然后 只在 Au dioCaps 上 。因 此 ,与 Audio L D M- *-F T 型 号系 列 相比 , TA N G O 具 有 更高 的采 样效率。
在 主观 评 价 方 面, T A N G O 也 显示出非常好的结果,其整体音频质量得分为 85. 94,相关性得分为 80.36,表 明 其音 频 生成 能力 明 显优 于 A udio LD M 和其 他 基线 文 本到 音频 生 成方 法。
表 1:T A N G O 模 型与 基线 TTA 模 型 的 比较 。F T 表 示该 模型 在 Au dioc aps ( A C)数 据 集 上进 行了 微 调。AS 和 AC 分别代表 Au dioSet 和 Audio cC aps 数 据 集。 除了 A udio L D M-L-F ull 外, 我 们借 用 了 [18]的所 有结 果 , Audio L D M -L -Full 是 使用 作 者在 Hu ggingf a ce 上 发 布的 模型 进 行评 估的 。 尽管 L D M是在 一个 小 得多 的数 据 集上 训 练的 , 但 TA N G O 在 客 观 和 主 观指 标上 都 优于 AudioL D M 和其他基线 TTA 模型 。表 示 使用 L iu 等 人释 放的 检 查点 获 得结 果 。[18]。
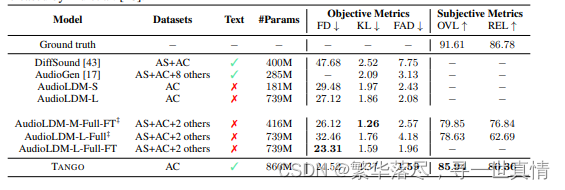
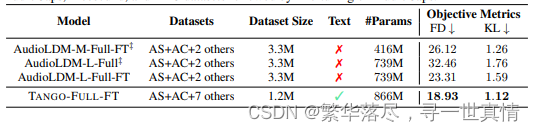
表 2:在 大型 数据 集的 语料 库上 训练 时, T A N G O 和 基线 TT A 模 型 的 比较 。T A N G O-Full-F T 首先在 包含 AudioSet 、 A udioCa ps 、 Frees ound 和 BBC 数据集样本的语料库上进行预训练,然后对AudioC aps 进 行微 调。
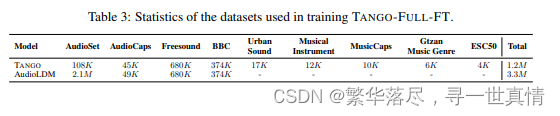
大数据集上的训练。 在本实 验 中 , 我 们 遵 循 两 个 步 骤 来 提 高 T A N G O 的 性 能 。 首先,我们使用来 自 Wav Ca ps[ 24]、 A udio Ca ps 、 ES C[ 26]、 Ur b an- S ou nd [3 6]、 Music C aps [1]、 G T Z A N [4 0]和Musica l Instrum e ntsda ta set4 的文本提示 和 音 频样 本 组 成 的 不 同 语 料 库 进 行 预训 练 。 数 据 集 统 计表 3。所 有超 过 10 秒 的音 频片 段被 分割 成连 续 10 秒 或更 短的 分区 。我 们还 将所 有音 频片 段重 新采样到 16 K Hz。 Wav Ca ps 数 据 集由 chatgpt 为 FreeS ound5、 BBC 音效 6 (SF X)和 AudioS et 强 标记 子集生 成的 字幕 组成 。城 市声 音 和 ESC50 数 据 集包 含各 种环 境声 音。 乐器 数据 集包 含吉 他、 鼓、 小提琴 和钢 琴乐 器的 声音 。 GT Z A N 数 据集 包含 不同 音乐 类型 的 声音 -古典 ,爵 士等 。这 四个 数据 集 -城市 声音 , ESC50, 乐 器, G TZ A N 是 音 频分 类数 据集 。我 们使 用分 类标 签, 例如 钢琴 和一 个更 自然的钢琴提示音,为这 些数 据集 的每 个音 频样 本创 建两 个不 同的 训练 实例 。
最初 的预 训 练阶 段旨 在 获取 对 音频 和文 本 交互 的广 泛 理解 。接 下 来, 我 们针 对 A udioC aps 数据集
对预 训练 模 型进 行微 调 。所 获 得的 结果 如表 2 所 示 ,表 明与 A udio L D M 家 族 中 的类 似 模型相比 ,T A N G O -F U LL-F T 实 现 了 显 着 的 性能 改 进 。这 些 可 比模 型 经 历了 相 同 的预 训 练 和 微调 方 法 ,突 出了我 们的 方 法在 提高 模 型整 体 性能 方面 的 有效 性。 我 们使 用 4 个 A60 00 gpu 对 T A N G O 进 行 了持续 20 万 步的 预 训练 。为 了 优化 训 练过 程, 我 们将 每 个 GP U 的 批 大 小设 置 为 2,并 采 用 8 个梯 度累积 步骤 , 这有 效地 将 批大 小 增加到 64 个 。 我 们在 Au dioCa ps 上 微 调了 57 K 步 的 模型 。 为了 帮助 TTA 中的 开源 研 究, 我们 公 开发 布了 这 个数 据集 。
不同数据增强策略的效果。 表 4 给出了随机和相对基于压力的数据增强策略的比较。值得注意的是,基于相对压力的增强策略产生了最有希望的结果。在评估 T A N G O 与 A u dio L D M -L 时 ,两者都使用随机数据增强策略, T A N G O 在三个客观指标中的两个方面优 于 Au dio L D M -L。 这一显著的改进可归功于在 T A N G O 中集成了一个强大的大型语言模型( F L A N -T5 )作 为 文 本 提 示编码器。
表 4:随机与相对压力引导增强对客观评估指标的影响。以3 和 200 个推理步骤的指导量表计算得分。

推 理 步 骤 与 无分 类 器 引导 的 效 果 。 推理步数 和 无分 类器 引 导尺 度 对于 从 潜在 扩 散模 型 中采 样 至关 重要 [38,7]。 我 们 在表 5 中报 告了 不 同步 数 和不 同制 导 尺度 对 Audio Ca ps 中音 频 生成 的影 响 。我 们发现 ,指 导 等级 为 3 的 T A N G O 提 供 了 最 好的 结果。 在 表 5 的左 侧 部分 , 我们 固定 了 3 的 指导 尺度, 并 将步 数 从 10 变化到 200。 随 着 步 数的 增 加, 生 成的 音 频质 量 和最 终 的客 观 指标 始 终变 得更好 。 Liu et al.[ 18]报道, Au dioL D M 的性能在 100 步 左右 趋于 平 稳, 200 步 只 提供 略微 更 好的 性能。 然而 , 我们 注意 到 ,当 T A N G O 的 推 理 步骤 从 100 步 增加 到 200 步 时, 性 能有 了实 质 性的 提高,这表明更多的推 理步 骤可 能 会进 一步 提 高性 能 。
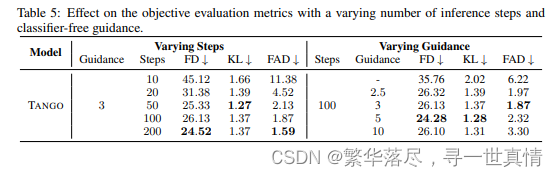
我们在 表 5 的 右半 部分报 告了 用固定 的 100 步改 变指导 量表 的效果 。第 一行使 用 1 的引导 尺度 ,因此 在推 理 过程 中 有效 地完 全 不应 用无 分 类器 的 引导 。不 出 所料 ,这 种 配置 的 性能 很差 , 在所 有客观度 量上远 远落 后于无 分类 器引导 模型 。指导 分值为 2.5,F D 和 K L 较 好, 指导 分值为 5。在 指导尺度为 3 时,得到最 佳 FA D 指标, 指导 尺度越 大, 指标越 差。
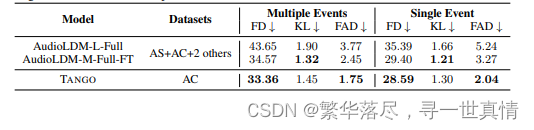
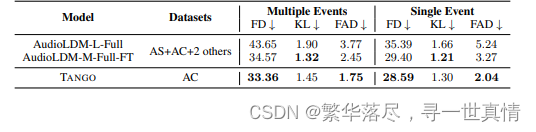
时序建模 (Temporal Sequence modeling). 我们 分析 了 当 文本 提 示 包含 多 个 连续 事 件 时, T A N G O 和AudioL D M 模 型如何 执行 音频 生成。 考虑 下面的 例子 :一 个小男孩说话,然 后是 塑料叮当声,然后 是一个孩 子笑, 其 中包 含 三 个 独立 的 连 续事件,而滚雷和闪电 只 包含 一 个 。我们使用时态标识符 (while、befor e、 after、 then 和 follows)将 Au dioCaps 测 试集 分离 为两 个子集 ,一 个具 有多个 事件 ,另 一个具有单 个事件 。我 们在表 6 中 显示 了这些 子集 上音频 生成 的客观 评估 结果。 T A N GO 在 多个事 件和单个事 件实例 中都 能获得 最佳 的 F D 和 FA D 分 数。 Audio L D M-M-Full-F T 模型的 K L 散度 得分 最高。我们推 测,与 无参 考的 F D 和 F A D 指 标不 同,来 自 Au dioL D M 中 四个 训练数 据集 的更大 语料 库可能更有助于改进基于参考的 K L 指 标.
表 6:A udioC ap s 测 试集 中 文本 提示 符 中存 在多 个 事件 或 单个 事件 时 音频 生成 的 客观 评估 结 果。 多个事 件和 单 个事 件子 集 共同 构 成了 整个 AudioC aps 测 试 集 。需 要注 意 的是 , F D 和 F AD 是语料库级别 的非 线 性指 标, 因 此 表 1 中 报告 的 F D 和 F A D 分 数 并 不是 本 表中 报告 的 子集 分数 的 平均 值 。
性能与标签数量的关系。 回想一下, A udioCaps 数据集是根据 AudioS et 数 据 集中 音 频分 类 任务 的注释 进行 策 划的 。因 此 , Au dioCa ps 中 的文 本 提示 可以 与 Au dioSet 的 离散 类 标签 配对 。 A udioSet数据 集 总共 包 含 632 个 音 频 事件 类 。例 如 ,一个女人 和一 个婴 儿正在 进行 对话, 其 对 应的 音 频片 段有以 下三 个 标签 :Speech, C hil d Speech ki d s peaki ng, Insi de s mall room。我 们 在 Au dioCa ps 中对 具 有一 个标签 、 两 个标 签 和 多个 (两 个 或 更多)标 签 的 实 例进 行 分组 , 并 跨客 观 指 标评 估 生 成的 音 频 。我 们在 表 7 中报 告 了实 验结 果 。 TA N G O 在 从 带有 一 个标 签 或两 个标 签 的文 本生 成 音频 的所 有 客观 指标上 都优于 Au dioL D M 模 型 。 对 于具 有 多个 标签 的 文本 , Au dioL D M 获得了更好的 KL 发散分数,T A N G O 获得了更好 的 F D 和 F AD 分 数 。 有趣 的 是, 随 着标 签的 增 加, 所有 的 模型 都获 得 了更 好的 FD 和 KL 分 数, 这 表明 扩 散模 型更 有 效地 处理 了 这些 文本 提 示。
表 7: 对 于 包 含 一 个 、 两 个 或 多 个(两 个 或 更 多 )标 签 的 文 本 , A udioC aps 中 音 频 生 成 的 性 能 。
Au dioC aps 中 的每 个 文本 都有 A udioSet 中 相应 的多 类 别标 签 。我 们使 用 这些 标签 将 Au dioCa ps 数据集划分为三个子集。
增 压 的 影 响和 相 对 压力 水 平 §增 压 的 分 布 我们在前面 的 2.3 节 中描 述了 我们 的增 压策 略。 方程 (9)中相对 压力 水平 p 在 训练 样本 中的 分布 如图 2 所 示, 这意 味着 相 对压 力水 平大 致为 正态 分布 ,许 多样本 的相 对 压力 水 平较 低, 这 可能 在随 机 混合 中表 现 不佳 。 相比 之下 , 我们 的方 法 允许 更公 平 的混合。
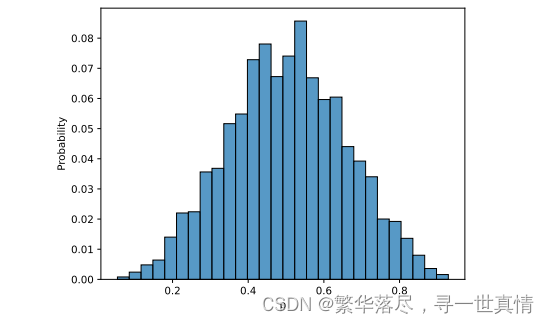
表 8:A udioC aps 数 据 集 中 最常 见 类别 的 Audio L D M - M -Full FT 和 T A N G O 性 能“ CE B” 表 示 通 道、环境和背景声音 类别 。

分类模型。 AudioSet 中的类 标签 可以 分层 排列 ,获 得以 下顶 级类 别:i)人 类声 音, ii)动物 声音 ,iii)自然声音,iv)声音事物 , v)通道 , 环境 ,背 景声 音 , vi)源 模糊 的声 音 ,以 及 vii)音 乐。 我们 将 A udioCa ps 中 的类 标签映 射到 上面 列出 的七 个主 要类 别。 音乐 类别 在 Au dioCa ps 中 非常 罕见 ,其 他类 别要 么单 独出 现,要么 与其 他类 别组 合在 一起 。我 们选 择最 常出 现的 类别 组合 ,并 分析 表 8 中构成 AudioC aps 实 例的各 种模 型的 性能 。这 两个 模型 的性 能在 F D 和 KL 指 标 上相 当平 衡, T A N G O 在 某些 方面 更好 ,而 AudioL D M 在 其 他方 面 更好 。然 而, 除了 一组 之 外, T A N G O 在 所 有组 中都 取得 了更好 的 FA D分数,在(人类,动 物 ), (自 然), (事物 )和(自然 ,事 物 )类 别中 有 很大 的改 进。
4 相 关 作品
扩散模型。 近年 来, 扩 散 模 型作 为 生 成 高质 量 语 音 的主 要 方 法 激增[2,1 6,27, 28,1 0,8]。这些模型利用固 定 数 量的 马 尔 可夫 链 步 骤将 白 噪 声信 号 转 换为 结 构 化波 形 。其 中 , FastDiff 在 高 质 量 语音 合成 [8]方 面 取得 了 显著 的 效果 。 通过 利 用时 间 感 知扩 散 过程 堆 栈, FastDiff 可 以 以 令 人印 象 深刻 的速度 生成 卓越 质量 的语 音样 本, 比 V10 0 GPU 上 的 实时 速度 快 58 倍 ,使 其适 用于 语音 合成 部署 。在端 到 端文 本 到语 音合 成 方面 , 它超 越 了其 他 现有 的方 法 。另 一 个值 得 注意 的 音频 合成 概 率模 型是 Diff Wa ve[ 16], 它 是非 自回 归的 ,为 各种 波形 生成 任务 生成 高保 真音 频, 包括 基于 mel 谱图 的神经 语 音编 码、 类 条件 生 成和 无 条件 生 成。 Diff Wa ve 提 供 的 语 音质 量 与强 大 的 Wav e N et 声码 器[25]相 当 , 同 时 合成 音 频 的速 度 要 快得 多 。 扩散 模 型 已经 成 为 一种 很 有 前途 的 语 音处 理 方 法, 特别是 在语 音增 强方 面 [21,37,2 9,22 ]。 扩散 概率 模型 的最 新进 展导 致了 一种 新的 语音 增强 算法 的发 展,该 算法 将 有 噪声 语 音 信号 的 特 征纳 入 正 向和 反 向 扩散 过 程[23]。 这 种 新 算法 是 概 率扩 散 模 型的 一种广 义 形式 , 被称 为条 件 扩散 概 率模 型 。在 其 反向 过程 中 ,它 可 以适 应 估计 语 音信 号中 的 非高 斯实噪 声, 使得 其在 提高 语音 质 量方 面非 常有 效。 此外 , Qiu 等 人[29]提出了 SRT Net, 这是 一种 用于语 音 增强 的 新方 法, 将 扩散 模 型作 为 随机 细 化的 模块 。 所提 出 的方 法 包括 确 定性 模块 和 随机 模块的 联合 网络 ,形 成了 “ 增强 -细化 ”范 式 。本 文还 对所 提出 的方 法的 可 行性 进行 了理 论论 证, 并给出了支持其有效性的实验结果,突出了其在提高语音质量方面的潜力。
Text-to-Audio生成。 文本到音频 生成 领域 直 到最 近 才得 到有 限 的关 注 [17,4 3]。 在 Y ang 等人的[43]中, 使 用文 本编 码 器来 获 取文 本 特征 , 然后 由非 自 回归 解 码器 处 理以 生 成谱 图令 牌 。这 些 标记 被馈送 到矢 量 量化 V AE ( V Q - V A E)以 生 成声 谱图 , 声码 器 使用 该声 谱 图生 成音 频 。非 自回 归 解码 器是 一个 概 率 扩散 模 型 。 此外 ,Y an g 等 人 引 入 了一 种 新 的 数据 增 强 技 术, 称 为 基于 掩 码 的 文本 生成 策略 ( MB T G ), 该 技 术屏 蔽 了 不 代表 任 何 事 件的 输 入 文 本部 分 , 例如 那 些 表 示时 间 性 的 部分 。M BT G 的 目 的 是在 训练 过 程中 从音 频 中学 习增 强 文本 描 述。 虽然 这 种方 法看 起 来很 有前 途 ,但 它的 根本 限 制 是生 成 的 数 据缺 乏 多 样 性, 因 为 它无 法 混 合 不同 的 音 频样 本 。 后 来, Kre uk 等 人[1 7]对该 方 法进 行了 修 正, 根 据随 机 信噪 比 混合 音频 信 号, 并 将相 应 的文 本 描述 串接 起 来。 这 种方 法允许 生成 新 的 (文 本 、音 频)对, 并 减轻了 Y an g 等 人 的 限制 。与 Y an g 等 人 [43]不同,Kr eu k 等 人提出的架构[17]使用 变 压器 编码 器 和解 码器 网 络从 文 本输 入自 回 归地 生成 音 频令 牌。
最近 , Liu 等 人提 出 了 A udioL D M, 将 文 本 到 视觉 的 潜在 扩散 模 型转 化 为文 本 到音 频的 生 成。 他们 预先 训 练 了基 于 va e 的编码器-解 码 器 网络 来 学 习音 频 的 压缩 潜 在 表示 , 然 后 用它 来 指 导扩 散模型 从 文本 输入 生 成音 频 令牌 。 他们 发 现, 在反 向 扩散 过 程中 使 用音 频 嵌入 而不 是 文本 嵌 入改 善了条 件音 频 生成 。 在推 理期 间 ,他 们 使用 文本 嵌 入进 行 文本 到音 频 的生 成 。使 用预 训 练 的 CL AP获得音频和文本嵌入,这是原始 LD M 模 型中 使用 的 C LIP 嵌入 的 音频 对应 。
5 局 限性
T AN G O 并不 总是 能够通 过文 本控制 提示 来精细 地控 制其生 成, 因为它 只在 小型 A udioCaps 数据集上进行 训练 。例 如, 《 TA N G O》 中 的几代 人在 木桌 上切 西红 柿和 在金属 桌上 切土 豆是 非常 相似 的。在桌 子上 切 菜也 会 产生 类似 的 音频 样本 。 因此 , 需要 在更 大 的数 据集 上 训练 文 本到 音频 的 生成 模型, 以使 模型 学习 文本 概念 的组 成和 各种 文本 -音频 映 射。 在未 来, 我们 计划 通过 在更 大的 数据 集上训练 TAN G O 并增强其组成和可控 生成 能力来 改进 它。
6 结 论
在这 项工 作 中, 我们 研 究了 指 令调 谐模 型 FL A N-T 5 在 文 本到 音频 生 成中 的有 效 性。 具体 来 说, 我们在 潜在 扩 散模 型中 使 用 FL A N-T 5 生 成的 文 本嵌 入 来生 成 mel 谱 图 标记 。然 后 将这 些标 记 馈送 到预训 练的 变 分自 编码 器 (V A E )以 生成 m el 谱图 , 这些 谱 图稍 后由 预 训练 的声 码 器使 用以 生 成音 频 。与 最先 进 的 文本 到 音 频模 型 Audio L D M 相比,我们的模型在客观和主观评估下都取得了卓越的表现 ,尽 管 使用 的训 练 数据 只 减少了 6 3 倍 。我 们 主要 将 这种 性能 改 进归 因于 FL A N-T5 的表示能力, 这是 由 于它 在预 训 练阶 段 基于 指令 的 调整 。在 未 来, 我们 计 划研究 FL A N-T 5 在 其他 音 频任 务中的有效性,例如音频超分辨率和喷漆。
参 考 文献
[1] Andrea Agostinelli, Timo I Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon,
Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, et al. Musiclm: Generating
music from text. arXiv preprint arXiv:2301.11325, 2023.
[2] Nanxin Chen, Yu Zhang, Heiga Zen, Ron J Weiss, Mohammad Norouzi, and William Chan.
Wavegrad: Estimating gradients for waveform generation. arXiv preprint arXiv:2009.00713,
2020.
[3] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li,
Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu,
Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav
Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov,
Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason
Wei. Scaling instruction-finetuned language models, 2022. URL https://arxiv.org/abs/
2210.11416.
[4] Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Zhifang Sui, and Furu Wei. Why can gpt learn
in-context? language models secretly perform gradient descent as meta-optimizers. ArXiv,
abs/2212.10559, 2022.
[5] Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. Audio set: An ontology and human-labeled
dataset for audio events. In 2017 IEEE international conference on acoustics, speech and
signal processing (ICASSP), pages 776–780. IEEE, 2017.
[6] Tiankai Hang, Shuyang Gu, Chen Li, Jianmin Bao, Dong Chen, Han Hu, Xin Geng, and
Baining Guo. Efficient diffusion training via min-snr weighting strategy, 2023.
[7] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. NeurIPS 2021 Workshop
on Deep Generative Models and Downstream Applications, 2021.
[8] Rongjie Huang, Max WY Lam, Jun Wang, Dan Su, Dong Yu, Yi Ren, and Zhou Zhao. Fastdiff: A fast conditional diffusion model for high-quality speech synthesis. arXiv preprint
arXiv:2204.09934, 2022.
[9] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-image translation
with conditional adversarial networks. 2017 IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), pages 5967–5976, 2016.
[10] Myeonghun Jeong, Hyeongju Kim, Sung Jun Cheon, Byoung Jin Choi, and Nam Soo Kim.
Diff-tts: A denoising diffusion model for text-to-speech. arXiv preprint arXiv:2104.01409,
2021.
[11] Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. Fréchet audio
distance: A reference-free metric for evaluating music enhancement algorithms. In INTERSPEECH, pages 2350–2354, 2019.
[12] Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. Audiocaps: Generating captions for audios in the wild. In Proceedings of the 2019 Conference of the North
American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 119–132, 2019.
[13] Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. CoRR,
abs/1312.6114, 2013.
[14] Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. Hifi-gan: Generative adversarial networks
for efficient and high fidelity speech synthesis. Advances in Neural Information Processing
Systems, 33:17022–17033, 2020.
[15] Qiuqiang Kong, Yin Cao, Haohe Liu, Keunwoo Choi, and Yuxuan Wang. Decoupling magnitude and phase estimation with deep resunet for music source separation. In International
Society for Music Information Retrieval Conference, 2021.
[16] Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile
diffusion model for audio synthesis. arXiv preprint arXiv:2009.09761, 2020.
[17] Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre D’efossez, Jade Copet,
Devi Parikh, Yaniv Taigman, and Yossi Adi. Audiogen: Textually guided audio generation.
ArXiv, abs/2209.15352, 2022.
[18] Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo P. Mandic, Wenwu Wang,
and Mark D . Plumbley. AudioLDM: Text-to-audio generation with latent diffusion models.
ArXiv, abs/2301.12503, 2023.
[19] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy,
Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert
pretraining approach. ArXiv, abs/1907.11692, 2019.
[20] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint
arXiv:1711.05101, 2017.
[21] Yen-Ju Lu, Yu Tsao, and Shinji Watanabe. A study on speech enhancement based on diffusion probabilistic model. In 2021 Asia-Pacific Signal and Information Processing Association
Annual Summit and Conference (APSIPA ASC), pages 659–666, 2021.
[22] Yen-Ju Lu, Zhong-Qiu Wang, Shinji Watanabe, Alexander Richard, Cheng Yu, and Yu Tsao.
Conditional diffusion probabilistic model for speech enhancement. In ICASSP 2022 - 2022
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages
7402–7406, 2022. doi: 10.1109/ICASSP43922.2022.9746901.
[23] Yen-Ju Lu, Zhong-Qiu Wang, Shinji Watanabe, Alexander Richard, Cheng Yu, and Yu Tsao.
Conditional diffusion probabilistic model for speech enhancement. In ICASSP 2022-2022
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages
7402–7406. IEEE, 2022.
[24] Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao,
Mark D Plumbley, Yuexian Zou, and Wenwu Wang. Wavcaps: A chatgpt-assisted weaklylabelled audio captioning dataset for audio-language multimodal research. arXiv preprint
arXiv:2303.17395, 2023.
[25] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex
Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. Wavenet: A generative
model for raw audio. arXiv preprint arXiv:1609.03499, 2016.
[26] Karol J. Piczak. ESC: Dataset for Environmental Sound Classification. In Proceedings
of the 23rd Annual ACM Conference on Multimedia, pages 1015–1018. ACM Press, 2015.
ISBN 978-1-4503-3459-4. doi: 10.1145/2733373.2806390. URL http://dl.acm.org/
citation.cfm?doid=2733373.2806390.
[27] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail Kudinov. Gradtts: A diffusion probabilistic model for text-to-speech. In International Conference on Machine
Learning, pages 8599–8608. PMLR, 2021.
[28] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Kudinov, and Jiansheng Wei. Diffusion-based voice conversion with fast maximum likelihood sampling scheme.
arXiv preprint arXiv:2109.13821, 2021.
[29] Zhibin Qiu, Mengfan Fu, Yinfeng Yu, LiLi Yin, Fuchun Sun, and Hao Huang. Srtnet: Time domain speech enhancement via stochastic refinement. arXiv preprint arXiv:2210.16805, 2022.
[30] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena,
Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified
text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020. URL
http://jmlr.org/papers/v21/20-074.html.
[31] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark
Chen, and Ilya Sutskever. Zero-shot text-to-image generation. ArXiv, abs/2102.12092, 2021.
[32] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical
text-conditional image generation with clip latents. ArXiv, abs/2204.06125, 2022.
[33] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer.
High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
[34] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for
biomedical image segmentation. In Nassir Navab, Joachim Hornegger, William M. Wells, and
Alejandro F. Frangi, editors, Medical Image Computing and Computer-Assisted Intervention –
MICCAI 2015, pages 234–241, Cham, 2015. Springer International Publishing. ISBN 978-3-
319-24574-4.
[35] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural
Information Processing Systems, 35:36479–36494, 2022.
[36] Justin Salamon, Christopher Jacoby, and Juan Pablo Bello. A dataset and taxonomy for urban
sound research. In Proceedings of the 22nd ACM international conference on Multimedia,
pages 1041–1044, 2014.
[37] Joan Serrà, Santiago Pascual, Jordi Pons, R Oguz Araz, and Davide Scaini. Universal speech
enhancement with score-based diffusion. arXiv preprint arXiv:2206.03065, 2022.
[38] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. ArXiv,
abs/2010.02502, 2020.
[39] Yuji Tokozume, Yoshitaka Ushiku, and Tatsuya Harada. Learning from between-class examples for deep sound recognition. CoRR, abs/1711.10282, 2017. URL http://arxiv.org/
abs/1711.10282.
[40] George Tzanetakis and Perry Cook. Musical genre classification of audio signals. IEEE Transactions on speech and audio processing, 10(5):293–302, 2002.
[41] Wikipedia. Tango. https://en.wikipedia.org/wiki/Tango, 2021. [Online; accessed
21-April-2023].
[42] Wikipedia. Tango music. https://en.wikipedia.org/wiki/Tango_music, 2021. [Online; accessed 21-April-2023].
[43] Dongchao Yang, Jianwei Yu, Helin Wang, Wen Wang, Chao Weng, Yuexian Zou, and Dong
Yu. Diffsound: Discrete diffusion model for text-to-sound generation. arXiv preprint
arXiv:2207.09983, 2022.