场景
阿里的通义千问qwen大模型,推理速度慢,单卡/双卡速度慢。
详细:
1、今日在使用qwen-14b的float16版本进行推理(BF16/FP16)
1.1 在qwen-14b-int4也会有同样的现象
2、使用3090 24G显卡两张
3、模型加载的device是auto,device=“auto”
解决方案
使用多卡推理,需要开启flash-attention,否则会慢
flash-attention安装
0、如果已经下载了qwen的源码,可以看到源码包里有flash-attention的文件夹。或者也可以去达摩院的git上下载:flash-attention的git地址
1、cd flash-attention
2、python setup.py install
2.1、在执行这句命令时,可能会报Could not build wheels for flash-attn, which is required to install pyproject.toml-based projects(如果不报,当我没说)
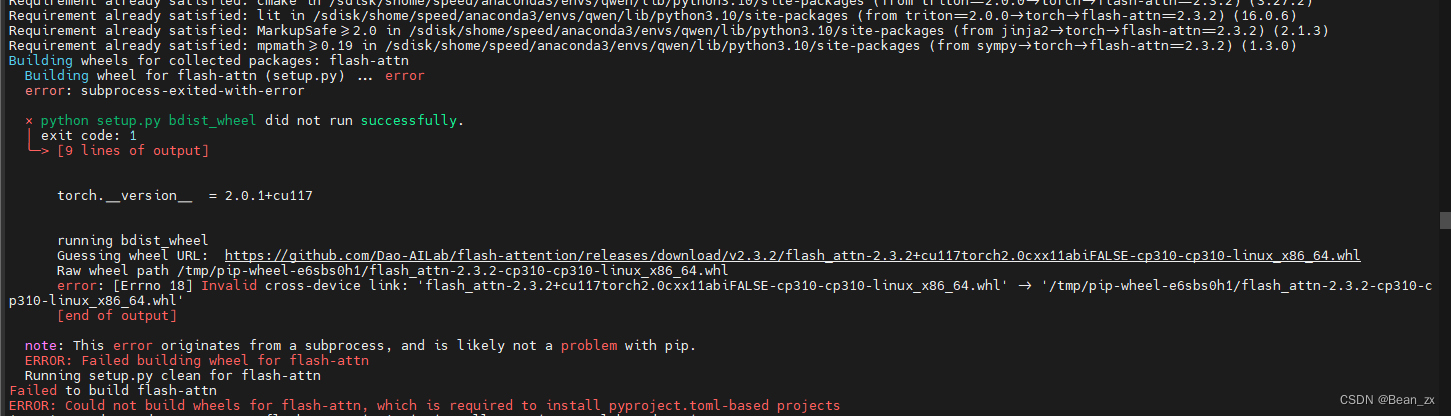
这里我的解决方法是执行
pip install flash-attn --no-build-isolation
还没结束,继续往下
3、至此就有了flash-attn包了,但是加载模型的时候,还是会报警告,这时的推理速度依旧是很慢的
Try importing flash-attention for faster inference...
Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary
Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm

4、继续安装rotary和layer_norm
# 安装rotary
cd flash-attention
cd csrc/rotary
python setup.py install# 安装layer_norm
cd flash-attention
cd csrc/layer_norm
python setup.py install
5、至此安装完成,加载模型,不会报flash-attention的警告,加载速度也有显著的提升。
6、安装前,我尝试2048字数结果的问答,
-
qwen-14b回答需要100秒,安装后需要70秒
-
qwen-14b-int4回答需要60秒,安装后需要20秒