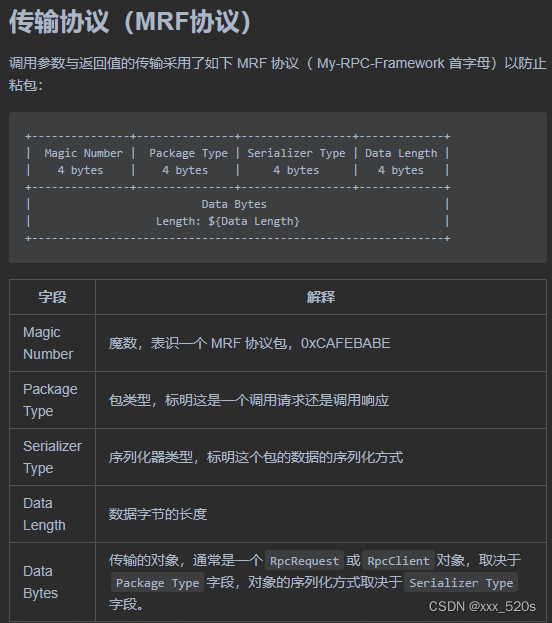
如何开展全链路压测
业务模型梳理
- 首先应该将核心业务和非核心业务进行拆分,确认流量高峰针对的是哪些业务场景和模块,针对性的进行扩容准备
- 梳理出对外的接口:使用MOCK(模拟)方式做挡板
- 千万不要污染正常数据:认真梳理数据处理的每一个环节,确保 mock 数据的处理结果不会写入到正常库里面
数据模型构建
- 数据的真实性和可用性:可以从生产环境完全移植一份当量的数据包,作为压测的基础数据,然后基于基础数据,通过分析历史数据增长趋势,预估当前可能的数据量
- 数据隔离:千万不要污染正常数据:认真梳理数据处理的每一个环节,可以考虑通过压测数据隔离处理,落入影子库,mock 对象等手段,来防止数据污染
压测工具选型
使用分布式压测的手段来进行用户请求模拟,目前有很多的开源工具可以提供分布式压测的方式,比如JMeter、nGrinder、Locust等。有条件的也可以采购阿里云的PTS。
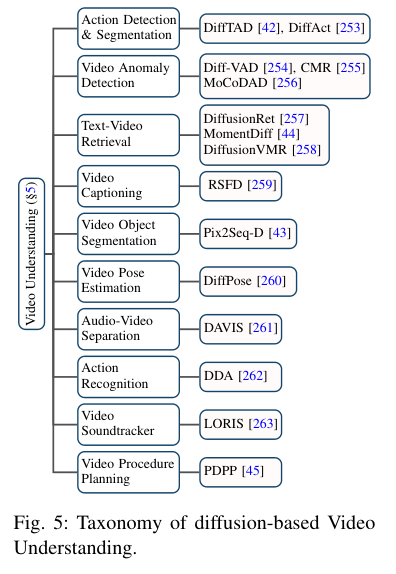
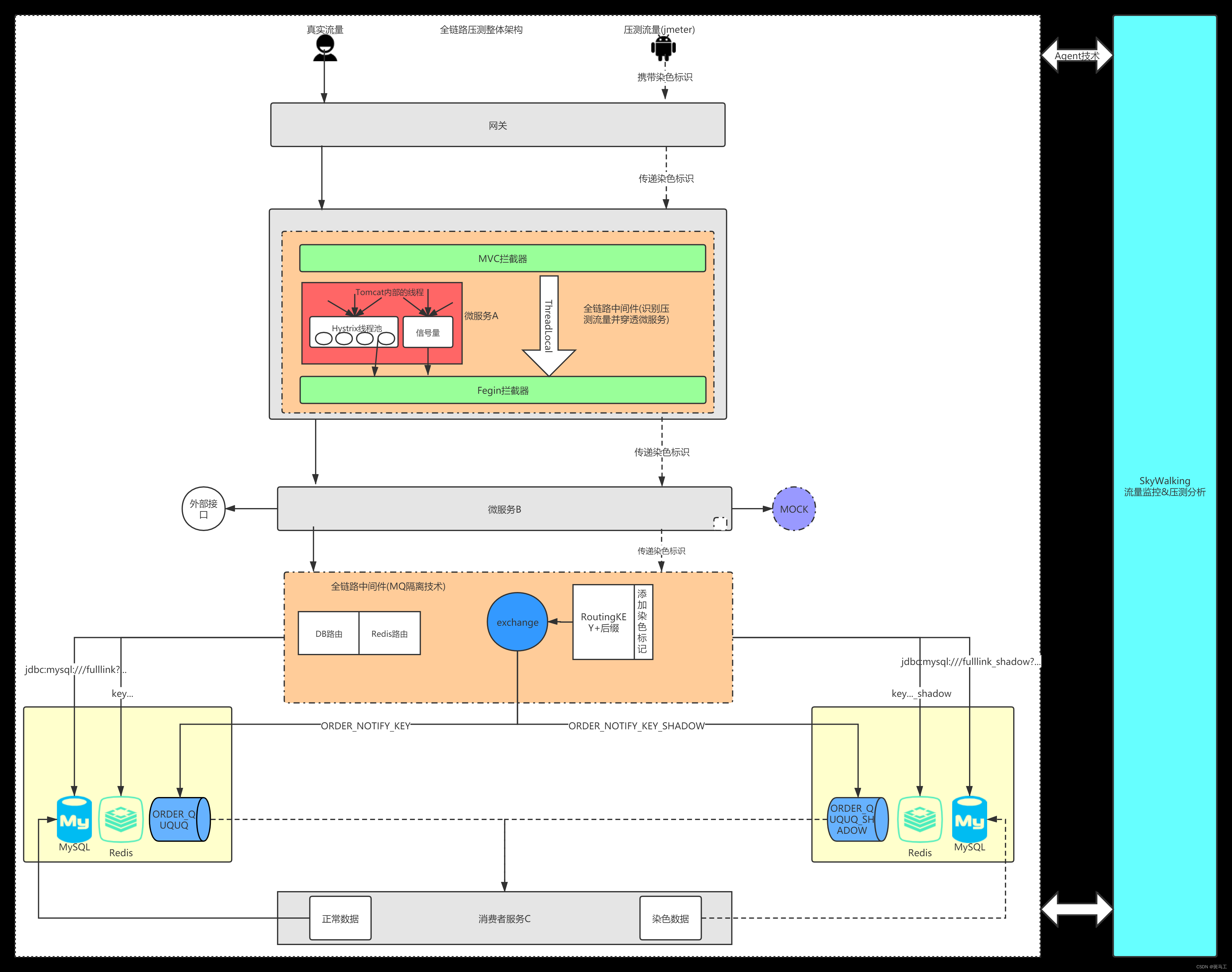
全链路整体架构
整体架构如下主要是对压测客户端的压测数据染色,全链路中间件识别出染色数据,并将正常数据和压测数据区分开,进行数据隔离,这里主要涉及到mysql数据库,RabbitMQ,Redis,还需要处理因为hystrix线程池不能通过ThreadLocal传递染色表示的问题。
需要应对的问题
业务问题
1. 涉及的系统太多,牵扯的开发人员太多
在压测过程中,做一个全链路的压测一般会涉及到大量的系统,在整个压测过程中,光各个产品的人员协调就是一个比较大的工程,牵扯到太多的产品经理和开发人员,如果公司对全链路压测早期没有足够的重视,那么这个压测工作是非常难开展的。
2. 模拟的测试数据和访问流量不真实
在压测过程中经常会遇到压测后得到的数据不准确的问题,这就使得压测出的数据参考性不强,为什么会产生这样的问题?主要就是因为压测的环境可能和生成环境存在误差、参数存在不一样的地方、测试数据存在不一样的地方这些因素综合起来导致测试结果的不可信。
3. 压测生产数据未隔离,影响生产环境
在全链路压测过程中,压测数据可能会影响到生产环境的真实数据,举个例子,电商系统在生产环境进行全链路压测的时候可能会有很多压测模拟用户去下单,如果不做处理,直接下单的话会导致系统一下子会产生很多废订单,从而影响到库存和生产订单数据,影响到日常的正常运营。
技术问题
探针的性能消耗
APM组件服务的影响应该做到足够小。
服务调用埋点本身会带来性能损耗,这就需要调用跟踪的低损耗,实际中还会通过配置采样率的方式,选择一部分请求去分析请求路径。在一些高度优化过的服务,即使一点点损耗也会很容易察觉到,而且有可能迫使在线服务的部署团队不得不将跟踪系统关停。
代码的侵入性
即也作为业务组件,应当尽可能少入侵或者无入侵其他业务系统,对于使用方透明,减少开发人员的负担。
对于应用的程序员来说,是不需要知道有跟踪系统这回事的。如果一个跟踪系统想生效,就必须需要依赖应用的开发者主动配合,那么这个跟踪系统也太脆弱了,往往由于跟踪系统在应用中植入代码的bug或疏忽导致应用出问题,这样才是无法满足对跟踪系统“无所不在的部署”这个需求。
可扩展性
个优秀的调用跟踪系统必须支持分布式部署,具备良好的可扩展性。能够支持的组件越多当然越好。或者提供便捷的插件开发API,对于一些没有监控到的组件,应用开发者也可以自行扩展。
数据的分析
数据的分析要快 ,分析的维度尽可能多。跟踪系统能提供足够快的信息反馈,就可以对生产环境下的异常状况做出快速反应。分析的全面,能够避免二次开发。
全链路压测核心技术
全链路流量染色
做到微服务和中间件的染色标志的穿透
通过压测平台对输出的压力请求打上标识,在订单系统中提取压测标识,确保完整的程序上下文都持有该标识,并且能够穿透微服务以及各种中间件,比如 MQ,hystrix,Fegin等。
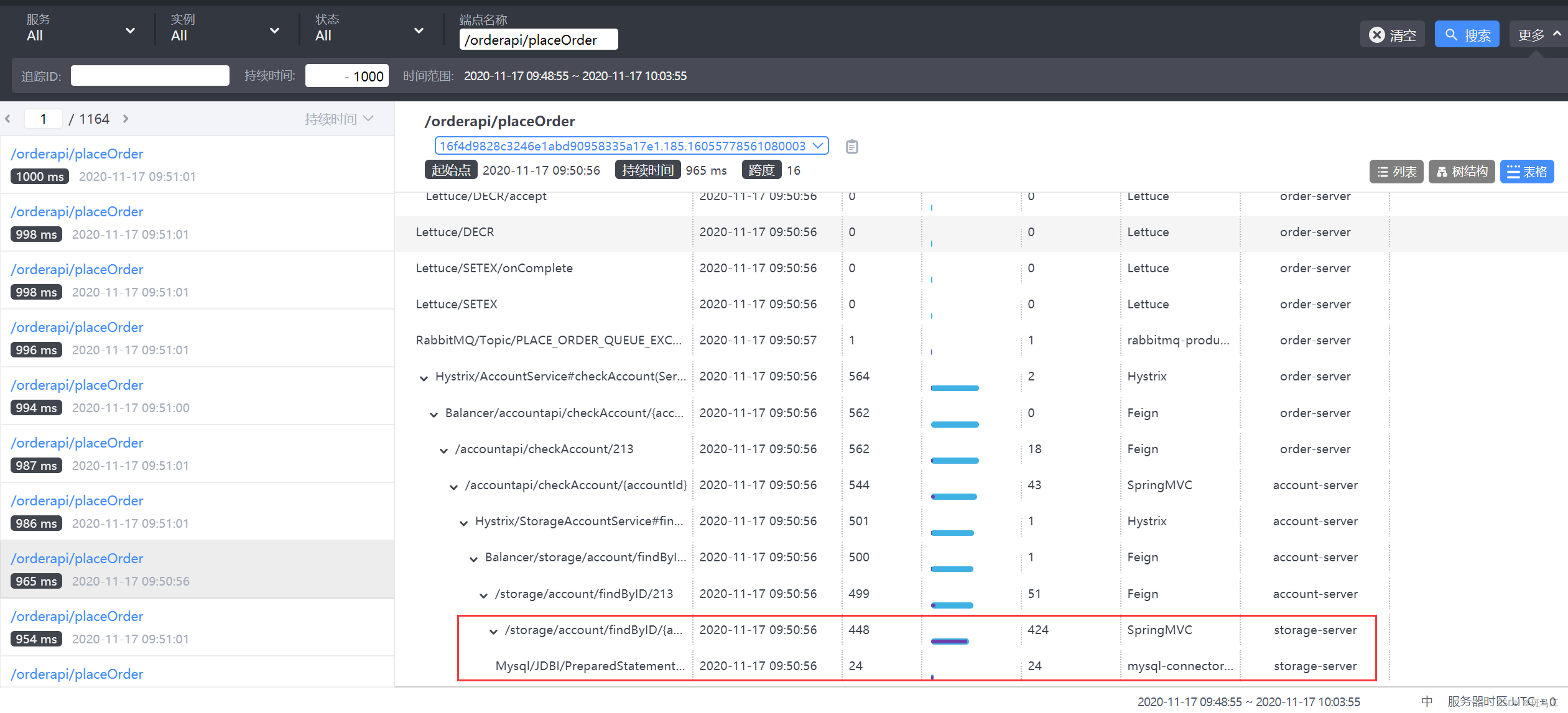
全链路服务监控
需要能够实时监控服务的运行状况以及分析服务的调用链,我们采用skywalking进行服务监控和压测分析
全链路日志隔离
做到日志隔离,防止污染生产日志
当订单系统向磁盘或外设输出日志时,若流量是被标记的压测流量,则将日志隔离输出,避免影响生产日志。
全链路风险熔断
流量控制,防止流量超载,导致集群不可用
当订单系统访问会员系统时,通过RPC协议延续压测标识到会员系统,两个系统之间服务通讯将会有白黑名单开关来控制流量流入许可。该方案设计可以一定程度上避免下游系统出现瓶颈或不支持压测所带来的风险,这里可以采用Sentinel来实现风险熔断。
全链路数据隔离
对各种存储服务以及中间件做到数据隔离,方式数据污染
数据库隔离
当会员系统访问数据库时,在持久化层同样会根据压测标识进行路由访问压测数据表。数据隔离的手段有多种,比如影子库、影子表,或者影子数据,三种方案的仿真度会有一定的差异,他们的对比如下。
| 隔离性 | 兼容性 | 安全级别 | 技术难度 | |
|---|---|---|---|---|
| 影子库 | 高 | 高 | 高 | 中 |
| 影子表 | 中 | 中 | 低 | 低 |
| 影子数据 | 低 | 低 | 低 | 低 |
消息队列隔离
当我们生产的消息扔到MQ之后,接着让消费者进行消费,这个没有问题,压测的数据不能够直接扔到MQ中的,因为它会被正常的消费者消费到的,要做好数据隔离,方案有队列隔离,消息隔离,他们对比如下。
| 隔离性 | 兼容性 | 安全级别 | 技术难度 | |
|---|---|---|---|---|
| 消息隔离 | 低 | 低 | 低 | 中 |
| 队列隔离 | 高 | 高 | 高 | 高 |
redis隔离
通过 key 值来区分,压测流量的 key 值加统一后缀,通过改造RedisTemplate来实现key的路由。