论文作者:Zhen Xing,Qijun Feng,Haoran Chen,Qi Dai,Han Hu,Hang Xu,Zuxuan Wu,Yu-Gang Jiang
作者单位:Fudan University;Microsoft Research Asia;Huawei Noah's Ark Lab
论文链接:http://arxiv.org/abs/2310.10647v1
项目链接:https://github.com/ChenHsing/Awesome-Video-Diffusion-Models
内容简介:
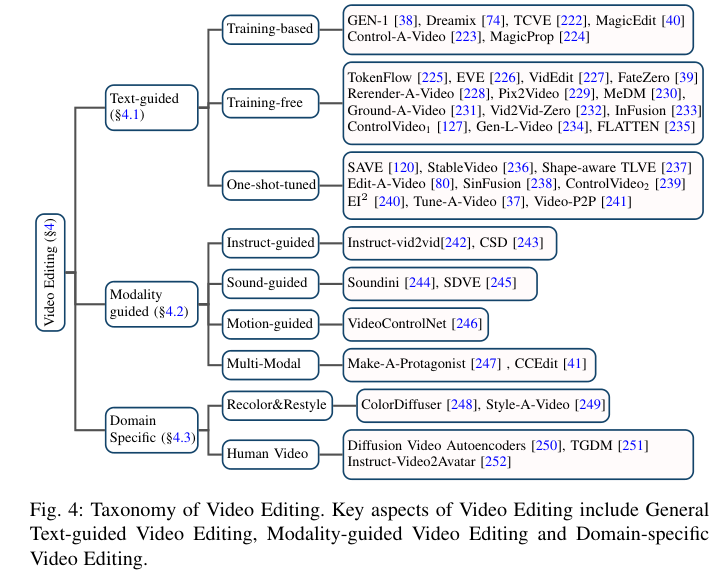
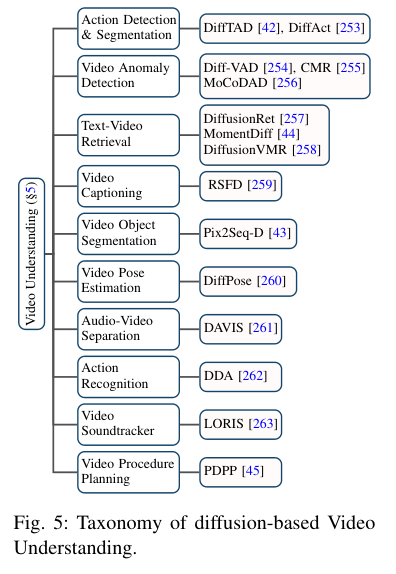
近期生成式AI(AIGC)在计算机视觉领域取得了显著的成功,扩散模型在其中扮演了关键角色。由于其出色的生成能力,扩散模型逐渐取代了基于GANs和自回归Transformers的方法,在图像生成和编辑方面表现出色,同时也在视频相关研究领域展现出卓越性能。然而,现有的调查主要集中在图像生成的背景下,对其在视频领域的应用缺乏最新的评估。为填补这一空白,本文提供了生成式AI时代视频扩散模型的全面评估。具体来说,作者首先简要介绍了扩散模型的基础和演变。随后,概述了视频领域内对扩散模型的研究,将工作分为三个关键领域:视频生成、视频编辑以及其他视频理解任务。对这三个关键领域的文献进行了彻底的回顾,包括在该领域的进一步分类和实际贡献。最后,讨论了该领域研究面临的挑战,并勾勒了未来可能的发展趋势。本综述研究了视频扩散模型的全面列表,可在https://github.com/ChenHsing/Awesome-Video-Diffusion-Models上找到。