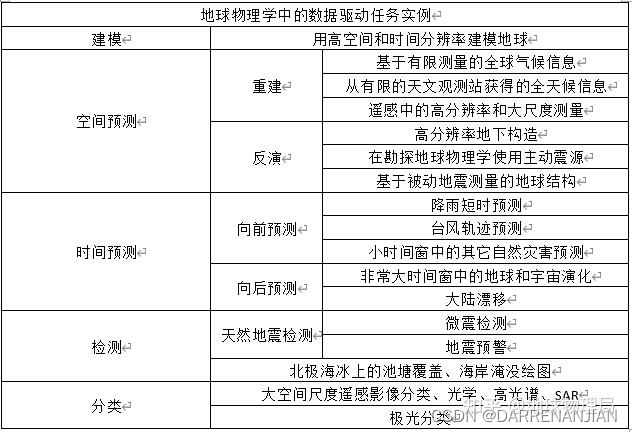
文章目录
- 泛型 Generics
- 泛型详解
- 结构体中使用泛型
- 枚举中使用泛型
- 方法中使用泛型
- 为具体的泛型类型实现方法
- const 泛型(Rust 1.51 版本引入的重要特性)
- const 泛型表达式
- 泛型的性能
泛型 Generics
Go 语言在 2022 年,就要正式引入泛型,被视为在 1.0 版本后,语言特性发展迈出的一大步,为什么泛型这么重要?到底什么是泛型?Rust 的泛型有几种? 本章将一一为你讲解。
我们在编程中,经常有这样的需求:用同一功能的函数处理不同类型的数据,例如两个数的加法,无论是整数还是浮点数,甚至是自定义类型,都能进行支持。在不支持泛型的编程语言中,通常需要为每一种类型编写一个函数:
fn add_i8(a:i8, b:i8) -> i8 {a + b
}
fn add_i32(a:i32, b:i32) -> i32 {a + b
}
fn add_f64(a:f64, b:f64) -> f64 {a + b
}fn main() {println!("add i8: {}", add_i8(2i8, 3i8));println!("add i32: {}", add_i32(20, 30));println!("add f64: {}", add_f64(1.23, 1.23));
}
上述代码可以正常运行,但是很啰嗦,如果你要支持更多的类型,那么会更繁琐。程序员或多或少都有强迫症,一个好程序员的公认特征就是 —— 懒,这么勤快的写一大堆代码,显然不是咱们的优良传统,是不?
在开始讲解 Rust 的泛型之前,先来看看什么是多态。
在编程的时候,我们经常利用多态。通俗的讲,多态就是好比坦克的炮管,既可以发射普通弹药,也可以发射制导炮弹(导弹),也可以发射贫铀穿甲弹,甚至发射子母弹,没有必要为每一种炮弹都在坦克上分别安装一个专用炮管,即使生产商愿意,炮手也不愿意,累死人啊。所以在编程开发中,我们也需要这样“通用的炮管”,这个“通用的炮管”就是多态。
实际上,泛型就是一种多态。泛型主要目的是为程序员提供编程的便利,减少代码的臃肿,同时可以极大地丰富语言本身的表达能力,为程序员提供了一个合适的炮管。想想,一个函数,可以代替几十个,甚至数百个函数,是一件多么让人兴奋的事情:
fn add<T>(a:T, b:T) -> T {a + b
}fn main() {println!("add i8: {}", add(2i8, 3i8));println!("add i32: {}", add(20, 30));println!("add f64: {}", add(1.23, 1.23));
}
将之前的代码改成上面这样,就是 Rust 泛型的初印象,这段代码虽然很简洁,但是并不能编译通过,我们会在后面进行详细讲解,现在只要对泛型有个大概的印象即可。
泛型详解
上面代码的 T 就是泛型参数,实际上在 Rust 中,泛型参数的名称你可以任意起,但是出于惯例,我们都用 T ( T 是 type 的首字母)来作为首选,这个名称越短越好,除非需要表达含义,否则一个字母是最完美的。
使用泛型参数,有一个先决条件,必需在使用前对其进行声明:
fn largest<T>(list: &[T]) -> T {
该泛型函数的作用是从列表中找出最大的值,其中列表中的元素类型为 T。首先 largest 对泛型参数 T 进行了声明,然后才在函数参数中进行使用该泛型参数 list: &[T] (还记得 &[T] 类型吧?这是数组切片)。
总之,我们可以这样理解这个函数定义:函数 largest 有泛型类型 T,它有个参数 list,其类型是元素为 T 的数组切片,最后,该函数返回值的类型也是 T。
下面是一个错误的泛型函数的实现:
fn largest<T>(list: &[T]) -> T {let mut largest = list[0];for &item in list.iter() {if item > largest {largest = item;}}largest
}fn main() {let number_list = vec![34, 50, 25, 100, 65];let result = largest(&number_list);println!("The largest number is {}", result);let char_list = vec!['y', 'm', 'a', 'q'];let result = largest(&char_list);println!("The largest char is {}", result);
}
运行后报错:
error[E0369]: binary operation `>` cannot be applied to type `T` // `>`操作符不能用于类型`T`--> src/main.rs:5:17|
5 | if item > largest {| ---- ^ ------- T| || T|
help: consider restricting type parameter `T` // 考虑对T进行类型上的限制 :|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> T {| ++++++++++++++++++++++
因为 T 可以是任何类型,但不是所有的类型都能进行比较,因此上面的错误中,编译器建议我们给 T 添加一个类型限制:使用 std::cmp::PartialOrd 特征(Trait)对 T 进行限制,特征在下一节会详细介绍,现在你只要理解,该特征的目的就是让类型实现可比较的功能。
还记得我们一开始的 add 泛型函数吗?如果你运行它,会得到以下的报错:
error[E0369]: cannot add `T` to `T` // 无法将 `T` 类型跟 `T` 类型进行相加--> src/main.rs:2:7|
2 | a + b| - ^ - T| || T|
help: consider restricting type parameter `T`|
1 | fn add<T: std::ops::Add<Output = T>>(a:T, b:T) -> T {| +++++++++++++++++++++++++++
同样的,不是所有 T 类型都能进行相加操作,因此我们需要用 std::ops::Add 对 T 进行限制:
fn add<T: std::ops::Add<Output = T>>(a:T, b:T) -> T {a + b
}
进行如上修改后,就可以正常运行。
结构体中使用泛型
结构体中的字段类型也可以用泛型来定义,下面代码定义了一个坐标点 Point,它可以存放任何类型的坐标值:
struct Point<T> {x: T,y: T,
}fn main() {let integer = Point { x: 5, y: 10 };let float = Point { x: 1.0, y: 4.0 };
}
这里有两点需要特别的注意:
- 提前声明,跟泛型函数定义类似,首先我们在使用泛型参数之前必需要进行声明
Point,接着就可以在结构体的字段类型中使用T来替代具体的类型 - x 和 y 是相同的类型
第二点非常重要,如果使用不同的类型,那么它会导致下面代码的报错:
struct Point<T> {x: T,y: T,
}fn main() {let p = Point{x: 1, y :1.1};
}
错误如下:
error[E0308]: mismatched types //类型不匹配--> src/main.rs:7:28|
7 | let p = Point{x: 1, y :1.1};| ^^^ 期望y是整数,但是却是浮点数
当把 1 赋值给 x 时,变量 p 的 T 类型就被确定为整数类型,因此 y 也必须是整数类型,但是我们却给它赋予了浮点数,因此导致报错。
如果想让 x 和 y 既能类型相同,又能类型不同,就需要使用不同的泛型参数:
struct Point<T,U> {x: T,y: U,
}
fn main() {let p = Point{x: 1, y :1.1};
}
切记,所有的泛型参数都要提前声明:Point ! 但是如果你的结构体变成这鬼样:struct Woo,那么你需要考虑拆分这个结构体,减少泛型参数的个数和代码复杂度。
枚举中使用泛型
提到枚举类型,Option 永远是第一个应该被想起来的,在之前的章节中,它也多次出现:
enum Option<T> {Some(T),None,
}
Option 是一个拥有泛型 T 的枚举类型,它第一个成员是 Some(T),存放了一个类型为 T 的值。得益于泛型的引入,我们可以在任何一个需要返回值的函数中,去使用 Option 枚举类型来做为返回值,用于返回一个任意类型的值 Some(T),或者没有值 None。
对于枚举而言,卧龙凤雏永远是绕不过去的存在:如果是 Option 是卧龙,那么 Result 就一定是凤雏,得两者可得天下:
enum Result<T, E> {Ok(T),Err(E),
}
这个枚举和 Option 一样,主要用于函数返回值,与 Option 用于值的存在与否不同,Result 关注的主要是值的正确性。
如果函数正常运行,则最后返回一个 Ok(T),T 是函数具体的返回值类型,如果函数异常运行,则返回一个 Err(E),E 是错误类型。例如打开一个文件:如果成功打开文件,则返回 Ok(std::fs::File),因此 T 对应的是 std::fs::File 类型;而当打开文件时出现问题时,返回 Err(std::io::Error),E 对应的就是 std::io::Error 类型。
方法中使用泛型
上一章中,我们讲到什么是方法以及如何在结构体和枚举上定义方法。方法上也可以使用泛型:
struct Point<T> {x: T,y: T,
}impl<T> Point<T> {fn x(&self) -> &T {&self.x}
}fn main() {let p = Point { x: 5, y: 10 };println!("p.x = {}", p.x());
}
使用泛型参数前,依然需要提前声明:impl,只有提前声明了,我们才能在Point中使用它,这样 Rust 就知道 Point 的尖括号中的类型是泛型而不是具体类型。需要注意的是,这里的 Point 不再是泛型声明,而是一个完整的结构体类型,因为我们定义的结构体就是 Point 而不再是 Point。
除了结构体中的泛型参数,我们还能在该结构体的方法中定义额外的泛型参数,就跟泛型函数一样:
struct Point<T, U> {x: T,y: U,
}impl<T, U> Point<T, U> {fn mixup<V, W>(self, other: Point<V, W>) -> Point<T, W> {Point {x: self.x,y: other.y,}}
}fn main() {let p1 = Point { x: 5, y: 10.4 };let p2 = Point { x: "Hello", y: 'c'};let p3 = p1.mixup(p2);println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}
这个例子中,T,U 是定义在结构体 Point 上的泛型参数,V,W 是单独定义在方法 mixup 上的泛型参数,它们并不冲突,说白了,你可以理解为,一个是结构体泛型,一个是函数泛型。
为具体的泛型类型实现方法
对于 Point 类型,你不仅能定义基于 T 的方法,还能针对特定的具体类型,进行方法定义:
impl Point<f32> {fn distance_from_origin(&self) -> f32 {(self.x.powi(2) + self.y.powi(2)).sqrt()}
}
这段代码意味着 Point 类型会有一个方法 distance_from_origin,而其他 T 不是 f32 类型的 Point 实例则没有定义此方法。这个方法计算点实例与坐标(0.0, 0.0) 之间的距离,并使用了只能用于浮点型的数学运算符。
这样我们就能针对特定的泛型类型实现某个特定的方法,对于其它泛型类型则没有定义该方法。
const 泛型(Rust 1.51 版本引入的重要特性)
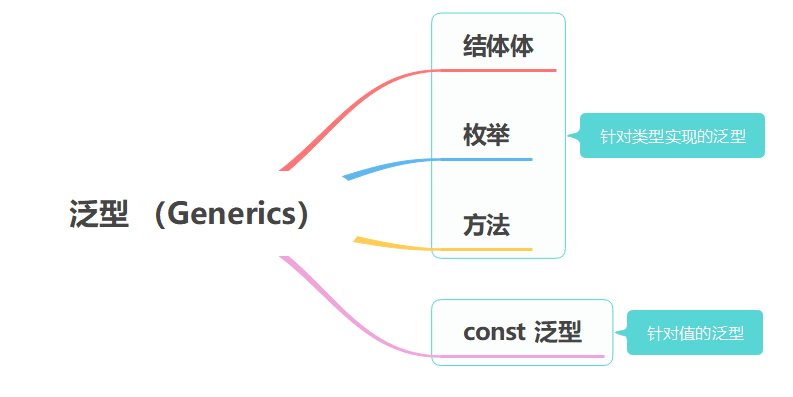
在之前的泛型中,可以抽象为一句话:针对类型实现的泛型,所有的泛型都是为了抽象不同的类型,那有没有针对值的泛型?可能很多同学感觉很难理解,值怎么使用泛型?不急,我们先从数组讲起。
在数组那节,有提到过很重要的一点:[i32; 2] 和 [i32; 3] 是不同的数组类型,比如下面的代码:
fn display_array(arr: [i32; 3]) {println!("{:?}", arr);
}
fn main() {let arr: [i32; 3] = [1, 2, 3];display_array(arr);let arr: [i32;2] = [1,2];display_array(arr);
}
运行后报错:
error[E0308]: mismatched types // 类型不匹配--> src/main.rs:10:19|
10 | display_array(arr);| ^^^ 期望一个长度为3的数组,却发现一个长度为2的
结合代码和报错,可以很清楚的看出,[i32; 3] 和 [i32; 2] 确实是两个完全不同的类型,因此无法用同一个函数调用。
首先,让我们修改代码,让 display_array 能打印任意长度的 i32 数组:
fn display_array(arr: &[i32]) {println!("{:?}", arr);
}
fn main() {let arr: [i32; 3] = [1, 2, 3];display_array(&arr);let arr: [i32;2] = [1,2];display_array(&arr);
}
很简单,只要使用数组切片,然后传入 arr 的不可变引用即可。
接着,将 i32 改成所有类型的数组:
fn display_array<T: std::fmt::Debug>(arr: &[T]) {println!("{:?}", arr);
}
fn main() {let arr: [i32; 3] = [1, 2, 3];display_array(&arr);let arr: [i32;2] = [1,2];display_array(&arr);
}
也不难,唯一要注意的是需要对 T 加一个限制 std::fmt::Debug,该限制表明 T 可以用在 println!("{:?}", arr) 中,因为 {:?} 形式的格式化输出需要 arr 实现该特征。
通过引用,我们可以很轻松的解决处理任何类型数组的问题,但是如果在某些场景下引用不适宜用或者干脆不能用呢?你们知道为什么以前 Rust 的一些数组库,在使用的时候都限定长度不超过 32 吗?因为它们会为每个长度都单独实现一个函数,简直。。。毫无人性。难道没有什么办法可以解决这个问题吗?
好在,现在咱们有了 const 泛型,也就是针对值的泛型,正好可以用于处理数组长度的问题:
fn display_array<T: std::fmt::Debug, const N: usize>(arr: [T; N]) {println!("{:?}", arr);
}
fn main() {let arr: [i32; 3] = [1, 2, 3];display_array(arr);let arr: [i32; 2] = [1, 2];display_array(arr);
}
如上所示,我们定义了一个类型为 [T; N] 的数组,其中 T 是一个基于类型的泛型参数,这个和之前讲的泛型没有区别,而重点在于 N 这个泛型参数,它是一个基于值的泛型参数!因为它用来替代的是数组的长度。
N 就是 const 泛型,定义的语法是 const N: usize,表示 const 泛型 N ,它基于的值类型是 usize。
在泛型参数之前,Rust 完全不适合复杂矩阵的运算,自从有了 const 泛型,一切即将改变。
const 泛型表达式
假设我们某段代码需要在内存很小的平台上工作,因此需要限制函数参数占用的内存大小,此时就可以使用 const 泛型表达式来实现:
// 目前只能在nightly版本下使用
#![allow(incomplete_features)]
#![feature(generic_const_exprs)]fn something<T>(val: T)
whereAssert<{ core::mem::size_of::<T>() < 768 }>: IsTrue,// ^-----------------------------^ 这里是一个 const 表达式,换成其它的 const 表达式也可以
{//
}fn main() {something([0u8; 0]); // oksomething([0u8; 512]); // oksomething([0u8; 1024]); // 编译错误,数组长度是1024字节,超过了768字节的参数长度限制
}// ---pub enum Assert<const CHECK: bool> {//
}pub trait IsTrue {//
}impl IsTrue for Assert<true> {//
}
泛型的性能
在 Rust 中泛型是零成本的抽象,意味着你在使用泛型时,完全不用担心性能上的问题。
但是任何选择都是权衡得失的,既然我们获得了性能上的巨大优势,那么又失去了什么呢?Rust 是在编译期为泛型对应的多个类型,生成各自的代码,因此损失了编译速度和增大了最终生成文件的大小。
具体来说:
Rust 通过在编译时进行泛型代码的 单态化(monomorphization)来保证效率。单态化是一个通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程。
编译器所做的工作正好与我们创建泛型函数的步骤相反,编译器寻找所有泛型代码被调用的位置并针对具体类型生成代码。
让我们看看一个使用标准库中 Option 枚举的例子:
let integer = Some(5);
let float = Some(5.0);
当 Rust 编译这些代码的时候,它会进行单态化。编译器会读取传递给 Option 的值并发现有两种 Option:一种对应 i32 另一种对应 f64。为此,它会将泛型定义 Option 展开为 Option_i32 和 Option_f64,接着将泛型定义替换为这两个具体的定义。
编译器生成的单态化版本的代码看起来像这样:
enum Option_i32 {Some(i32),None,
}enum Option_f64 {Some(f64),None,
}fn main() {let integer = Option_i32::Some(5);let float = Option_f64::Some(5.0);
}
我们可以使用泛型来编写不重复的代码,而 Rust 将会为每一个实例编译其特定类型的代码。这意味着在使用泛型时没有运行时开销;当代码运行,它的执行效率就跟好像手写每个具体定义的重复代码一样。这个单态化过程正是 Rust 泛型在运行时极其高效的原因。