CentralCache
- 1.框架介绍
- 2.核心功能
- 3.核心函数实现+介绍
- 3.1Span+SpanList介绍
- 3.2CentralCache.h
- 3.3CentralCache.cpp
- 3.4TreadCache申请内存函数介绍
- 3.5慢反馈算法
1.框架介绍
回顾一下ThreadCache的设计:
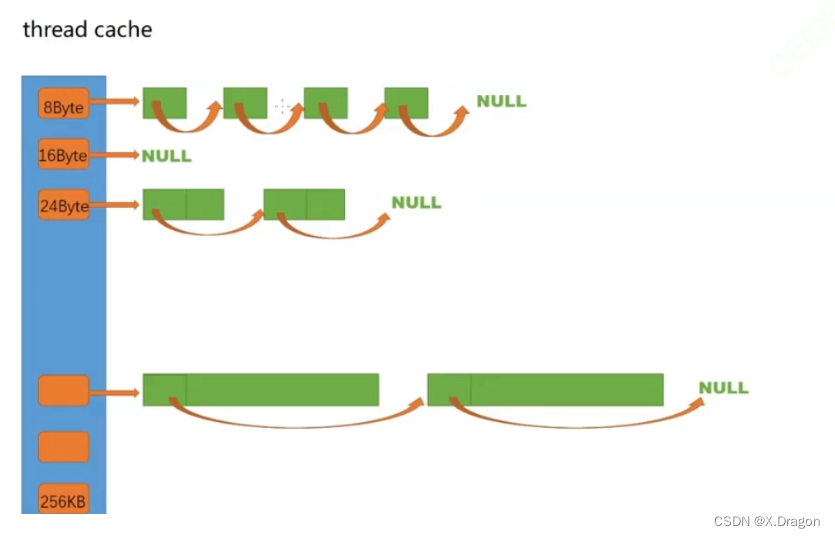
如图所示,ThreadCache设计是一个哈希桶结构,每一个桶挂的是一块切分好的小块内存块,每个线程独享一个ThreadCache。
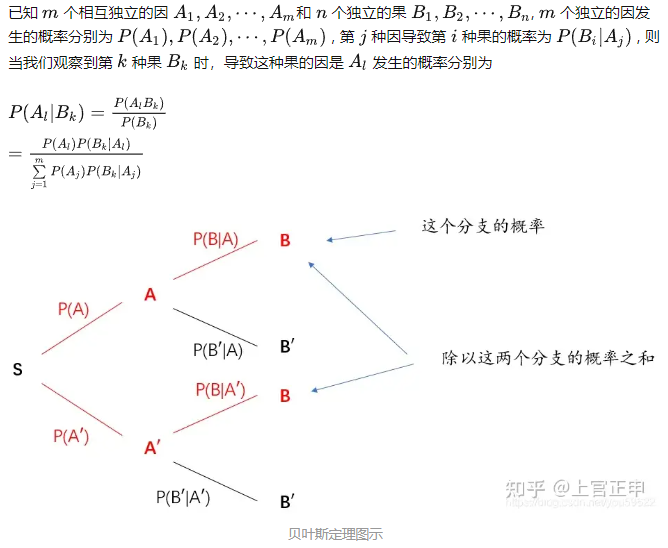
CentralCache:
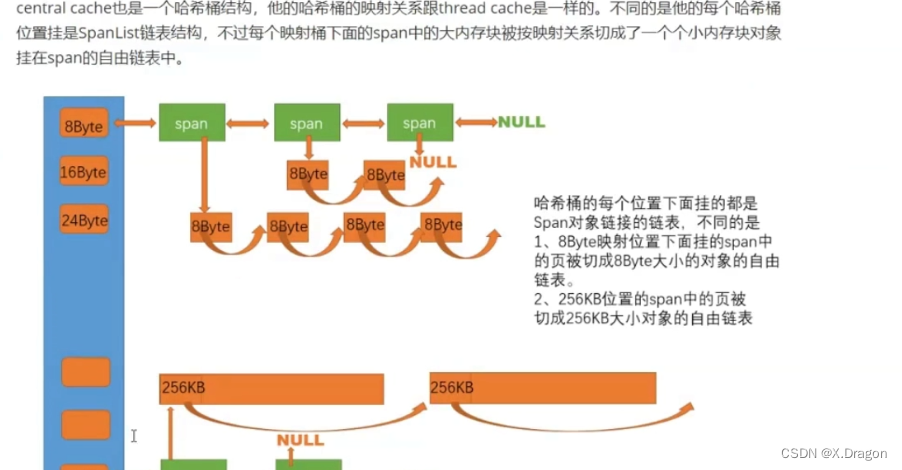
CentralCache也是一个哈希桶结构,跟ThreadCache的结构类似,只不过ThreadCache挂的是切分好的小对象内存块,而CentralCache挂的是一个spanlist 是一个连续的大块内存链表,链接着很多个span(大块内存)
而且根据下标映射的位置,切分好不同大小的对象,如第一个桶挂着8kb的小对象span,最后一个桶挂着大一些的 256kb的span,对象越小,span对象越多,反之。
2.核心功能
CentralCache作为中心调度,需要实现核心的内存分配调度工作,包括:
- 当ThreadCache内存不足时要向CentralCache申请,当CentralCache内存不足时再递进地向PageCache申请
- 当ThreadCache内存不用时,需要回收回来,再回收给PageCache,重新拼接成大块内存,解决内存碎片化问题
- 锁:因为涉及多个线程会访问同一个桶,所以要加锁实现 这里用到地是一个桶锁
- . 使用单例模式好处:
全局访问点:单例模式确保只有一个实例,并提供了一个全局的访问点,这样你可以在项目的任何地方访问 ‘CentralCache’ 的唯一实例。这对于管理和共享某些全局资源非常有用。
. 节省内存和初始化时间:饿汉模式确保 ‘CentralCache’ 在应用程序启动时创建,因此不需要等到实际需要它时再创建。这可以节省内存,并且初始化时间会更快,因为对象已经准备好。
线程安全:饿汉模式的单例在初始化时就创建了一个实例,因此它不需要考虑多线程竞争的问题。多线程环境下,多个线程访问单例时,它们都会引用相同的实例,而不会创建多个实例,因此不会导致竞争条件。
更容易管理:单例模式将全局状态和操作封装到一个类中,使代码更有组织性,易于维护和扩展。你可以通过单一的访问点执行与 ‘CentralCache’ 相关的操作。
. 有效资源管理:‘CentralCache’ 在内存池中起到了关键作用,以有效地分配和回收内存。它的唯一实例确保资源的一致性和高效的内存管理。
总之,使用单例模式可以更轻松地管理和访问 ‘CentralCache’ 的唯一实例,确保全局一致性和线程安全,节省内存和初始化时间,并使代码更具可维护性。这对于高并发内存池的实现非常有帮助。
3.核心函数实现+介绍
3.1Span+SpanList介绍
- 首先是结构体Span的介绍:
//Span:管理多个连续页的大块内存跨度结构
struct Span
{PAGE_ID _page_id = 0;//大块内存的起始页的页号size_t _n = 0;//页的数量Span* _next = nullptr; //设计成双向链表结构Span* _prev = nullptr;size_t _objSize = 0;//切好的小对象的大小size_t _usecount = 0;//切好的小块内存,被分配给threadcache的计数void* _freeList = nullptr;bool _isUse = false;//是否在使用 涉及到多个线程同时访问一个span 会有线程安全问题
};
- Spanlist代码
class SpanList
{
public:SpanList(){_head = new Span;_head->_next = _head;_head->_prev = _head;}//头插入函数void Insert(Span* pos, Span* newSpan){assert(pos);assert(newSpan);Span* prev = pos->_prev;prev->_next = newSpan;newSpan->_prev = prev;newSpan->_next = pos;pos->_prev = newSpan;}//删除void Erase(Span* pos){assert(pos);assert(pos != _head);Span* prev = pos->_prev;Span* next = pos->_next;prev->_next = next;next->_prev = prev;delete pos;}Span* Begin(){return _head->_next;}Span* End(){return _head;}bool Empty(){return _head->_next == _head;}void PushFront(Span* pos){Insert(Begin(),pos);}//头删Span* PopFront(){Span* front = _head->_next;Erase(front);return front;}public:std::mutex _mtx;//桶锁
private:Span* _head;};
以上都是一些基础的数据结构知识,不过多介绍。
3.2CentralCache.h
#pragma once
#include"Common.h"
//单例模式 --->饿汉模式
class CentralCache
{
public:static CentralCache* GetInstance() //获取单例{return &_Istance;}//获取一个非空的spanSpan* GetOneSpan(SpanList& list, size_t size);//定义 .CPP实现//从缓冲中心获取一定数量的对象返回给treadCachesize_t FetchRangeObj(void*& star, void*& end, size_t batchNum,size_t size);//Fetch-->获取//将一定数量的对象释放到span跨度void ReleaseListToSpans(void* start, size_t size); //Release-->释放
private:SpanList _spanlists[NFREELISTS];//确保类 只创建一个实例CentralCache() //构造函数私有化 {}CentralCache(const CentralCache&) = delete;//禁掉拷贝构造 static CentralCache _Istance;//首次调用即创建唯一单例
};
Span* GetOneSpance(SpanList& list, size_t size);
3.3CentralCache.cpp
#pragma once
#include"CentralCache.h"
#include"PageCache.h"
CentralCache CentralCache::_Istance;
size_t CentralCache::FetchRangeObj(void*& star, void*& end, size_t batchNum, size_t size)
{size_t index = SizeClass::Index(size);//计算出桶的下标_spanlists[index]._mtx.lock();//加锁Span* span = GetOneSpance(_spanlists[index], size);assert(span);assert(span->_freeList);//断言成功 则证明至少有一个块//从span中获取batchNum个对象 //如果实际的个数不够 那就有多少拿多少 这里就需要有一个实际变量actuall作为返回star = span->_freeList;end = star;size_t i = 0;size_t actualNum = 1;while (i < batchNum - 1 && NextObj(end) != nullptr){//更新end的位置end = NextObj(end);actualNum++;i++;}span->_freeList = NextObj(end);NextObj(end) = nullptr;span->_usecount += actualNum;//条件断点void* cur = star;int koko = 0;while (cur){cur = NextObj(cur);koko++;}if (koko != actualNum){int x = 0;}_spanlists[index]._mtx.unlock();return actualNum;
}Span* GetOneSpance(SpanList& list, size_t size)
{//查看一下当前spanlists是否span未分配的Span* it = list.Begin();while (it != list.End()){if (it->_freeList!=nullptr){return it;}else{it = it->_next;}}//先把centralCache的桶解掉 ,这样如果其他的线程释放对象回来,不会阻塞list._mtx.unlock();//走到这里说明没有空闲的span了,再往下找PageCache要PageCache::GetInstance()->_pageMtx.lock(); //加锁 这是一个大锁Span* span = PageCache::Newspan(SizeClass::NumMovePage(size));span->_isUse = true;span->_objSize = size;PageCache::GetInstance()->_pageMtx.unlock();//到这一步程序就已经申请到一个span了//对span进行切分 此过程不需要加锁 因为其他的线程访问不到这个span//通过页号 计算出起始页的地址 add=_pageID<<PAGE_SHIFT//计算span的大块内存的起始地址 和大块内存的大小(字节数)char* start = (char*)(span->_page_id << PAGE_SHIFT);size_t bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;//把大块内存切成自由链表 链接起来//这里使用尾插 因为尾插会保持内存空间的连续性 提高CPU的缓存利用率span->_freeList = start;start += size;void* tail = span->_freeList;int i = 1;while (start < end){++i;NextObj(tail) = start;tail = NextObj(tail);start += size;}if (tail == nullptr){int x = 0;}NextObj(tail) = nullptr;void* cur = span->_freeList;int koko=0;//条件断点 //类似死循环 可以让程序中断 程序会在运行的地方停下来while (cur){cur = NextObj(cur);koko++;}if (koko != (bytes / 16)){int x = 0;}//这里切好span以后 需要把span挂到桶里面 同时加锁list._mtx.lock();list.PushFront(span);list._mtx.unlock();return span;
}//回收内存
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{size_t index = SizeClass::Index(size);_spanlists[index]._mtx.lock();while (start){void* next = NextObj(start);Span* span = PageCache::GetInstance()->MapObjectToSpan(start);NextObj(start) = span->_freeList;span->_freeList = start;span->_usecount--;if (span->_usecount == 0)//说明span切分出去的内存小块都回收回来了,//这时这个span就可以再回收给page cache,page cache可以再尝试去做前后页的合并{_spanlists[index].Erase(span);span->_freeList = nullptr;span->_prev = nullptr;span->_next = nullptr;//释放span给page cache时,使用page cache的锁就可以了//所以需要先把桶锁解掉再加page cache的大锁_spanlists[index]._mtx.unlock();PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();_spanlists[index]._mtx.lock();}start = next;}_spanlists[index]._mtx.unlock();
}3.4TreadCache申请内存函数介绍
#define _CRT_SECURE_NO_WARNINGS
#pragma once
#include"ThreadCache.h"
#include<algorithm>
#include"CentralCache.h"
void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size);size_t index = SizeClass::Index(size);//计算哈希桶的下标if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);//找到对映射的自由链表桶 插入size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);//当链表的长度大于一次批量申请的内存就开始归还一段给CentralCacheif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){ListTooLong(_freeLists[index], size);//回收内存给CentralCache}
}
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{void* start = nullptr;void* end = nullptr;list.PopRang(start, end, list.MaxSize());CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{//慢开始反馈调节算法(batch:批量)//1.最开始不会一次向central cache要太多,因为要多了可能用不完,浪费//2.如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限//3.size越大,一次向central cache要的batchNum就越小//4.size越小,一次向central cache要的batchNum就越大size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freeLists[index].MaxSize() == batchNum){_freeLists[index].MaxSize() += 1;}void* start = nullptr;void* end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actualNum >= 1);if (actualNum == 1){assert(start == end);return start;}else{_freeLists[index].PushRange(NextObj(start), end, actualNum - 1);return start;}
}3.5慢反馈算法
申请的结构涉及 这里主要用的是慢反馈算法
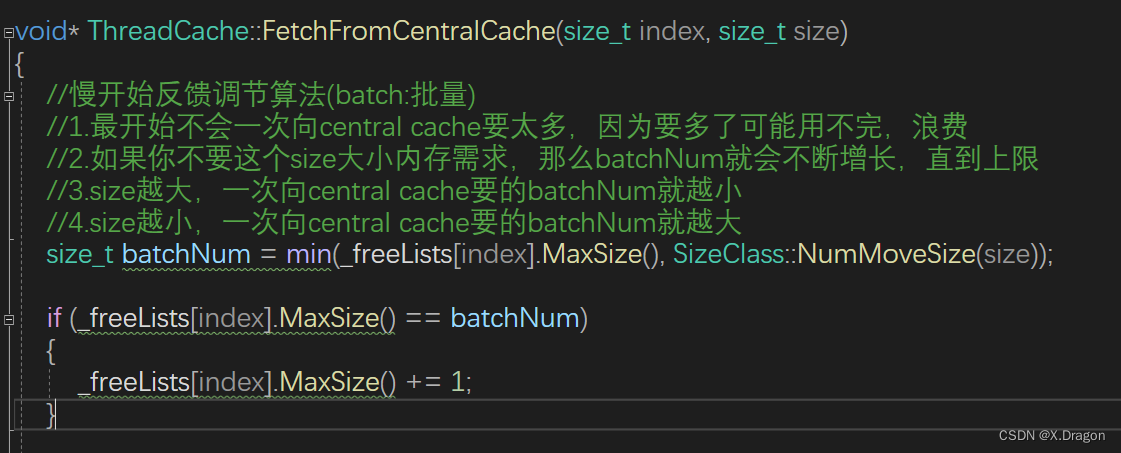


这里用双重机制来控制申请模块,第一次申请最大的申请数maxSize=1;然后计算慢启动函数的值,去最小的一个,如果说取的值是maxSize,那么maxSize就+=1;慢慢增长,这里可以根据实际需求调整增长的速度。
如果最后增长的范围超过慢启动设置的阈值,就取慢启动设置的值,在这两者策略下申请内存的机制得到更大的优化,大程度避免一次申请过大导致内存碎片问题。