思想类似于pipeline,将多个处理步骤连接起来。
看个例子,如果用MinMaxScaler和训练模型,需要反复执行fit和tranform方法,很繁琐,然后还要网格搜索,交叉验证
1 预处理进行参数选择
对于放缩的数据,一定要最先开始放缩,否则会导致数据放缩不一致,比如SVM+网格交叉,网格需要放缩数据,数据放缩需要带上测试集,否则性能下降,准确率打折扣
2 构造管道
注意 管道每次会调用scaler的fit方法,注意,可以对同一个scaler调多次fit,但不可以用两个或多个scaler单独放缩数据!!!
只需要几行代码,很简便
def test_chain_basic(self):xtr, xte, ytr, yte = train_test_split(self.cancer.data, self.cancer.target, random_state=0)pipe = Pipeline([('scaler', MinMaxScaler()), ('svm', SVC())]).fit(xtr, ytr)print(f'predict score: {pipe.score(xte, yte)}')
注意,给pipeline传参是个列表,列表项是长度为2的元组,元组第一个是字串,自定义,类似于一个名字,元组第二个参数是模型对象
3 网格搜索中使用管道
用法
1类似于上一节的scaler+监督模型的用法
2有个注意点是网格搜索需要给训练的模型传参,需要改下给grid对象传参字典的键名
3注意网格搜索是pipe作为参数传给GridSearchCV,二补数把pipe作为参数传给pipe
例子
def test_chain_scale_train_grid(self):xtr, xte, ytr, yte = train_test_split(self.cancer.data, self.cancer.target, random_state=0)pipe = Pipeline([('scaler', MinMaxScaler()), ('svm', SVC())]).fit(xtr, ytr)print(f'predict score: {pipe.score(xte, yte)}')params_grid = {'svm__C': [0.001, 0.01, 0.1, 1, 10, 100],'svm__gamma': [0.001, 0.01, 0.1, 1, 10, 100]}grid = GridSearchCV(pipe, params_grid, cv=5).fit(xtr, ytr).fit(xtr, ytr)print(f'best cross-validation accuracy: {grid.best_score_}')print(f'test score: {grid.score(xte, yte)}')print(f'best params: {grid.best_params_}')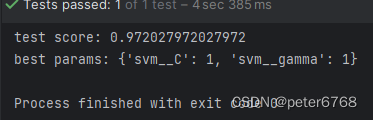
4 通用管道接口
pipeline还支持特征提取和特征选择,pipeline可以和估计器连接在一起,还可以和缩放和分类器连接在一起
对估计器的要求是需要有transform方法
调pipeline.fit的过程中,会依次调用每个对象的fit和transform方法,对于pipeline最后一个对象只调fit方法不调tranform方法
调pipeline.predict流程是先调每个估计器的transform方法最后调分类器的predict方法
4.1 用make_pipeline创建管道
用sklearn.pipeline.Pipeline初始化创建pipe对象比较繁琐,因为输入了每个步骤自定义的名称,有一种更简洁的方法,即调用make_pipeline方法创建pipe。这两种方法创建的pipe功能完全相同,但make_pipeline创建的对象的每个步骤命名是自动的
def test_make_pipeline(self):pipe_long = Pipeline([('scaler', MinMaxScaler()), ('svm', SVC(C=100))])pipe_short = make_pipeline(MinMaxScaler(), SVC(C=100))print(f'show pipe step name via make_pipeline: {pipe_short.steps}')
其实有时如果需要自定义每个名称,用Pipeline初始化方法也可以
4.2 访问步骤属性
pipe还可以访问串联对象中某个对象的属性:
def test_show_pipe_step_attrs(self):pipe = make_pipeline(StandardScaler(), PCA(n_components=2), StandardScaler()).fit(self.cancer.data, self.cancer.target)print(f'show pipe PCA main component shape: {pipe.named_steps["pca"].components_.shape}')
4.3 访问网格搜索管道中属性
任务 访问网格搜索的pipe的某个对象或属性
def test_show_pipe_step_attrs(self):pipe = make_pipeline(StandardScaler(), PCA(n_components=2), StandardScaler()).fit(self.cancer.data, self.cancer.target)print(f'show pipe PCA main component shape: {pipe.named_steps["pca"].components_.shape}')xtr, xte, ytr, yte = train_test_split(self.cancer.data, self.cancer.target, random_state=0)pipe = make_pipeline(StandardScaler(), LogisticRegression())params_pipe = {'logisticregression__C': [0.01, 0.1, 1, 10, 100]}grid = GridSearchCV(pipe, params_pipe, cv=5).fit(xtr, ytr)print(f'best estimators: {grid.best_estimator_}')print(f'logistic regression best estimator: {grid.best_estimator_.named_steps["logisticregression"]}')print(f'best model coef: {grid.best_estimator_.named_steps["logisticregression"].coef_}')
5 网格搜索预处理于模型参数(综合应用)
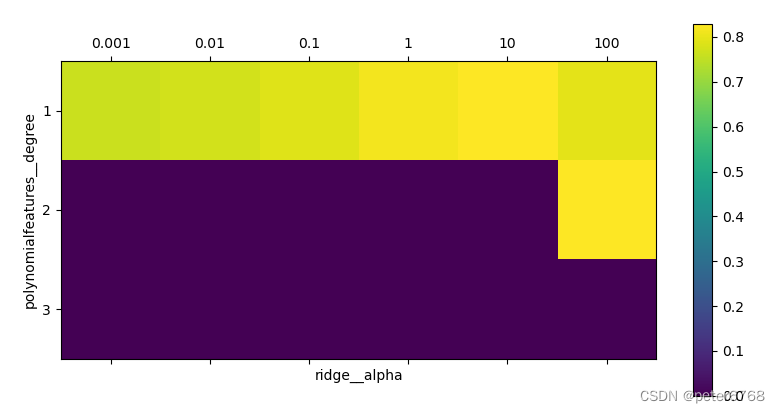
def test_chain_comprehensive(self):xtr, xte, ytr, yte = train_test_split(*self.boston, random_state=0)pipe = make_pipeline(StandardScaler(), PolynomialFeatures(), Ridge())params_grid = {"polynomialfeatures__degree": [1, 2, 3], "ridge__alpha": [0.001, 0.01, 0.1, 1, 10, 100]}grid = GridSearchCV(pipe, params_grid, cv=5, n_jobs=-1).fit(xtr, ytr)print(f'grid best params: {grid.best_params_}')print(f'grid best scores: {grid.score(xte, yte)}')# normal gridparams_grida = {'ridge__alpha': [0.001, 0.01, 0.1, 1, 10, 100]}pipea = make_pipeline(StandardScaler(), Ridge())grida = GridSearchCV(pipea, params_grida, cv=5).fit(xtr, ytr)print(f'normal ridge without polynomial features scores: {grida.score(xte, yte)}')plot.matshow(grid.cv_results_['mean_test_score'].reshape(3, -1), vmin=0, cmap='viridis')plot.xlabel('ridge__alpha')plot.ylabel('polynomialfeatures__degree')plot.xticks(range(len(params_grid['ridge__alpha'])), params_grid['ridge__alpha'])plot.yticks(range(len(params_grid['polynomialfeatures__degree'])), params_grid['polynomialfeatures__degree'])plot.colorbar()plot.show()
6 网格搜索使用哪个模型
参考非网格空间,给不同模型设置网格参数,然后一次grid可以测很多模型,最后给出最高分





![[AUTOSAR][诊断管理][ECU][$19] 读取ECU的DTC故障信息](https://img-blog.csdnimg.cn/3b0d29c96cbe4d27b7ede8870f04b1c8.png)