题目
试题编号: 201409-3
试题名称: 字符串匹配
时间限制: 1.0s
内存限制: 256.0MB
问题描述:
问题描述
给出一个字符串和多行文字,在这些文字中找到字符串出现的那些行。你的程序还需支持大小写敏感选项:当选项打开时,表示同一个字母的大写和小写看作不同的字符;当选项关闭时,表示同一个字母的大写和小写看作相同的字符。
输入格式
输入的第一行包含一个字符串S,由大小写英文字母组成。
第二行包含一个数字,表示大小写敏感的选项,当数字为0时表示大小写不敏感,当数字为1时表示大小写敏感。
第三行包含一个整数n,表示给出的文字的行数。
接下来n行,每行包含一个字符串,字符串由大小写英文字母组成,不含空格和其他字符。
输出格式
输出多行,每行包含一个字符串,按出现的顺序依次给出那些包含了字符串S的行。
样例输入
Hello
1
5
HelloWorld
HiHiHelloHiHi
GrepIsAGreatTool
HELLO
HELLOisNOTHello
样例输出
HelloWorld
HiHiHelloHiHi
HELLOisNOTHello
样例说明
在上面的样例中,第四个字符串虽然也是Hello,但是大小写不正确。如果将输入的第二行改为0,则第四个字符串应该输出。
评测用例规模与约定
1<=n<=100,每个字符串的长度不超过100。
题目分析(个人理解)
- 其实,这题目就告诉我们要考什么内容了,对于字符串的匹配有两种算法,第一种,BF算法,也就是朴素算法。还有一种,KMP算法。
- 由于测试长度较小,可以遍历比较,也就是BF算法足以。可以利用python的.find()方法实现查找,该函数会返回模式串第一个字符在母串的位置,如果不存在则返回-1。第一行输入的是模式串,第二行输入开关(1就是区分大小写,0不区分),第三行输入有n个母串,之后的n行输入n个母串,如果不区分大小写,可将母串与模式串都转化成大写或小写,然后判断是否匹配即可(使用.upper()方法可将字符串小写字母全部转为大写)。如果区分大小写,单用find()方法,判断是否存在即可。
- 最后输出存在的匹配的母串即可,上代码!!!
#朴素算法
s=input().strip()
m=int(input())
n=int(input())
for i in range(n):#枚举每一个字母,扫描每一个位置并且判断是否匹配x=input().strip()if m==1 :if x.find(s)!=-1:print(x)else:if x.upper().find(s.upper())!=-1:print(x)
- 模式匹配问题:就是在一篇长度为n的文本S中,查找某个长度为m的关键词P,称S为母串,P为模式串。P可能出现多次,都需要找到。
- BF算法是一种暴力解法,复杂度至少O(m+n),从S的第一个字符开始,逐个匹配P的每一个字符,如果发现不同就从S的下一个字符重新开始匹配。暴力方法哪里不好?遇到恶劣一点的模式串,如果模式串在匹配的时候一直到最后一个字符才匹配失败,那复杂度直接退化成O(nm)。所以说这种算法很不稳定。之后进化出了KMP算法。
- KMP算法是一种在任何情况下都可以达到O(m+n)复杂度的算法。我在介绍朴素算法的时候,,就是在匹配失败的时候指向P的指针j都要回溯到0,也就是又要从模式串第一个开始匹配,指向S的指针i都要回溯,这也就是弊端。
- 对于字符串的样子在匹配的时候可以分类,第一类,P在失配点之前的每个字符都不相同,在这种情况下可以直接把P滑动到S的i位置,此时i不变,j回溯到0,然后直接下一步匹配。第二类,P在失配点之前的字符有部分相同,关键是相同的部分在哪里,这又可以分为两种情况,相同的部分是前缀(在P的最前面)和后缀。假如在i号位失配,前缀与后缀相同时可以将P的前缀的后一位滑动到S的i号位做比较即可。第二种情况,相同的部分不是前缀或后缀,那只能按照第一类去判断,j回溯到i的位置在做匹配的判断。
- 好了,根据第七点我的解释,现在我们只需要找到最长公共前后缀和,也就是出现第二类的第一种情况的时候如何解决,第一类和第二类的第二种情况当匹配失败的时候只需要将j回溯到i即可。完全不需要回溯i,关键在于计算p的前缀和后缀。
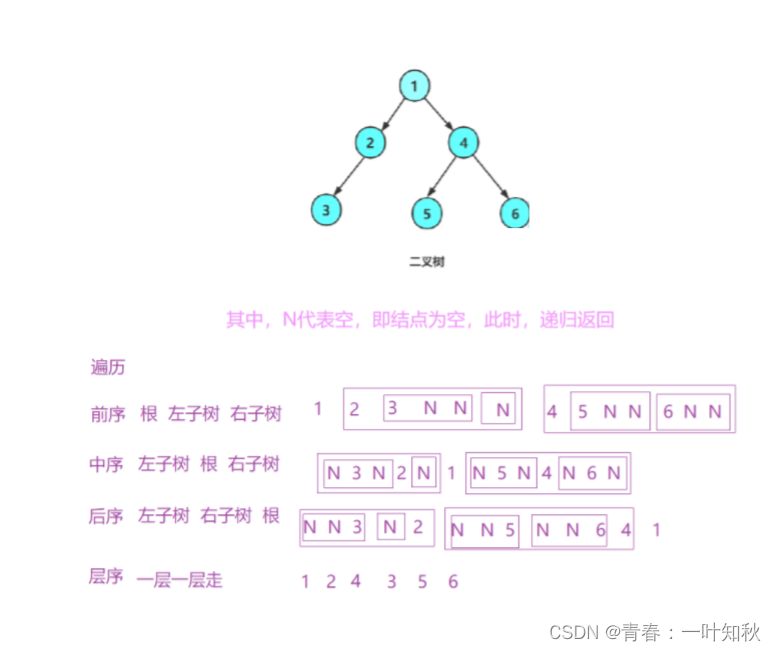
- Next[]数组的计算:例:P = “abcaab”,计算过程如下表,每一行的下划线串是最长公共前后缀。

计算Next[]:复杂度O(m)的方法,利用前缀和后缀的关系,从Next[i]递推到Next[i+1]。
假设已经算出Next[i],它对应P[0]~P[i-1]这部分子串的后缀和前缀。
阴影部分w是最长交集,交集w的长度等于Next[i]。
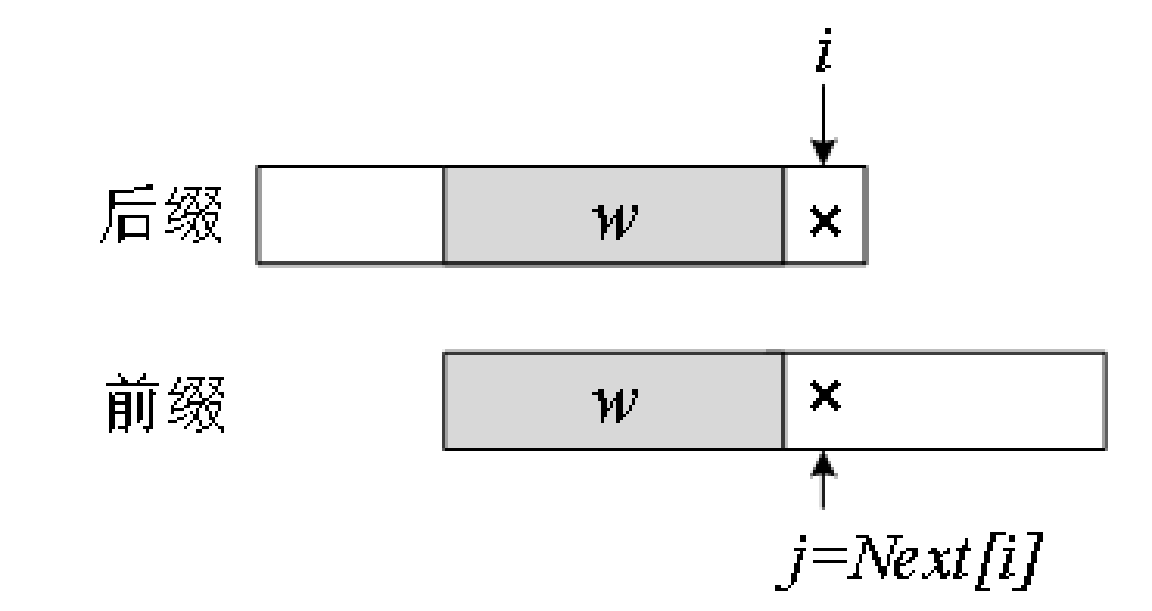
上半部分的阴影所示的后缀的最后一个字符是P[i-1];
下半部分阴影所示前缀的第一个字符是P[0],最后一个字符是P[j],j = Next[i]-1。

推广到Next[i+1],它对应P[0]~P[i]的后缀和前缀。
此时后缀的最后一个字符是P[i],与这个字符相对应,把前缀的j也往后移一个字符,j = Next[i]。判断两种情况:
(1)若P[i] = P[j],则新的交集等于“阴影w+ P[i]”,交集的长度Next[i+1] = Next[i]+1。
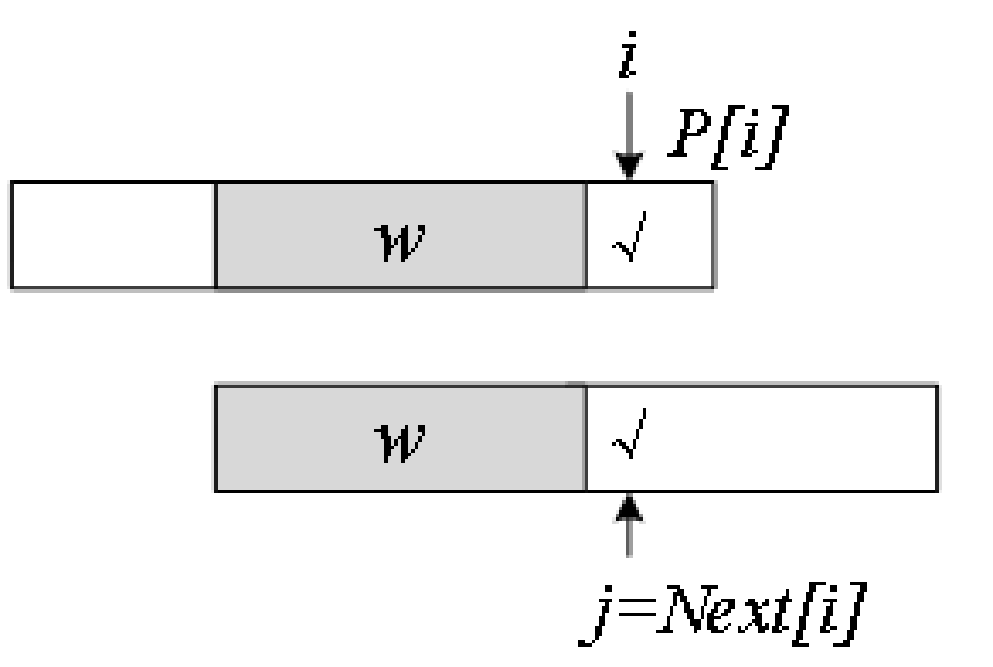
2)若P[i] ≠ P[j],说明后缀的“阴影w+P[i]”与前缀的“阴影w+P[j]”不匹配,只能缩小范围找新的交集。
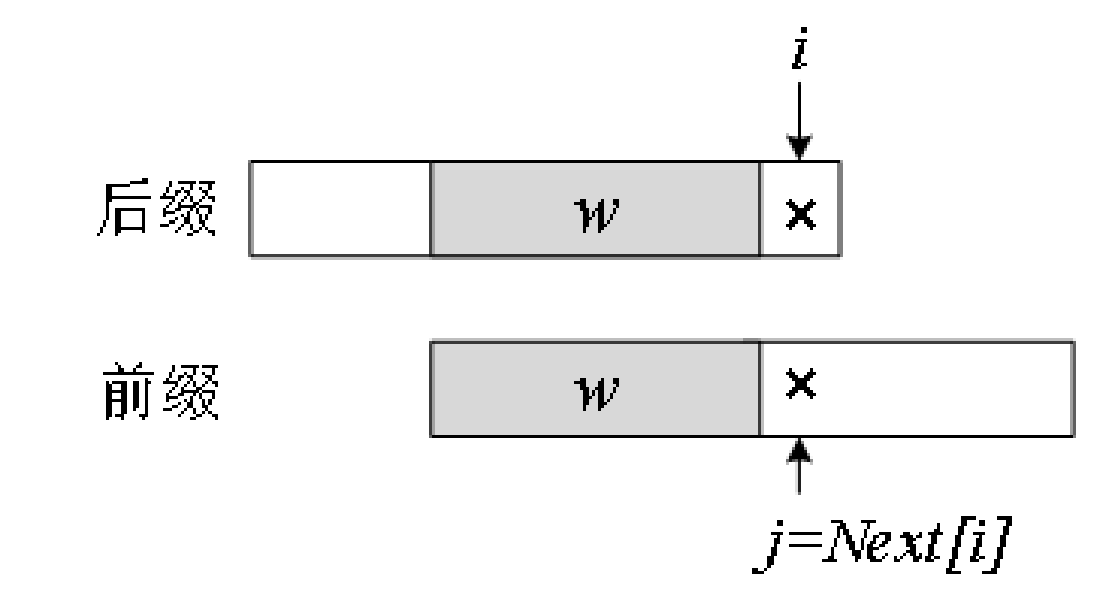
下图合并了前缀和后缀,画出完整的子串P[0]~P[i],最后的字符P[i]和P[j]不等。

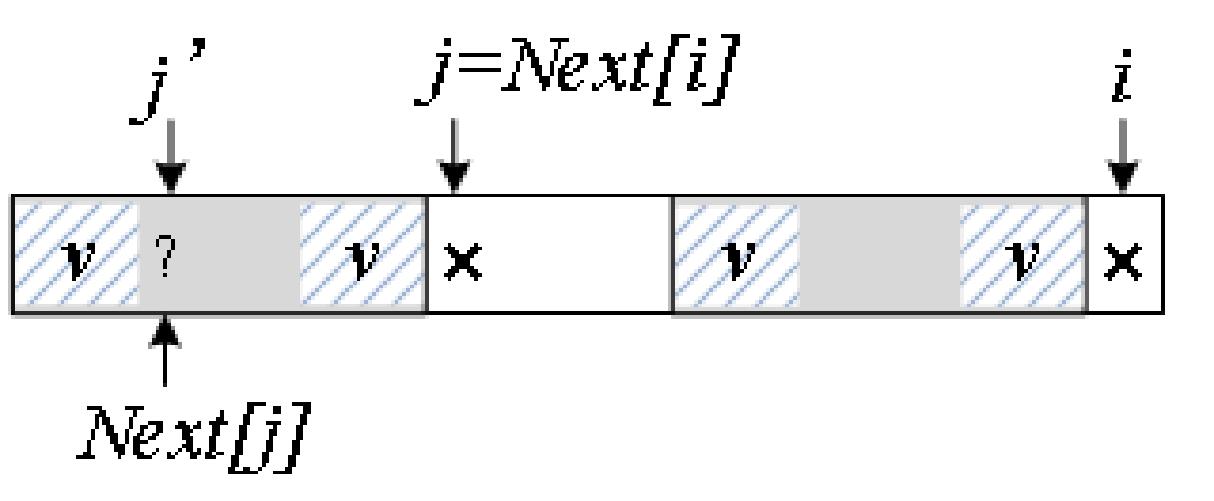
把前缀往后滑动,也就是通过减小j来缩小前缀的范围,直到找到一个匹配的P[i] = P[j]为止。
如何减小j?只能在w上继续找最大交集,这个新的最大交集是Next[j],所以更新j’ = Next[j]。
下图斜线阴影v是w上的最大交集,下一步判断:
若P[i] = P[j’],则Next[i+1]等于v的长度加1,即Next[j’]+1;
若P[i] ≠ P[j’],继续更新j’。
10. KMP算法代码如下!!!
N=1000005
Next = [0]*N
def getNext(p): #计算Next[1]~Next[plen]for i in range(1,len(p)):j = Next[i]; #j的后移:j指向前缀阴影w的后一个字符while j>0 and p[i] != p[j]: #阴影的后一个字符不相同j = Next[j] #更新jif p[i]==p[j]: Next[i+1] = j+1else: Next[i+1] = 0
def kmp(s,p):ans = 0j = 0for i in range(0,len(s)): #S的i指针,它不回溯,用for循环一直往前走。
#匹配S和P的每个字符 while j>0 and s[i]!=p[j]: #失配了j=Next[j] #j滑动到Next[j]位置if s[i]==p[j]: #若s[i]==p[j],说明当前P的字符和S的字符匹配j++,
#同时回到13行i++
#下一步匹配s[i+1]和p[j+1]。
#当前位置的字符匹配,继续j+=1ans = max(ans,j) if j == len(p): return ans #最长前缀就是p的长度,直接返回 return ans #返回p在s中出现的最长前缀
s=input()
t=input()
getNext(t)
print(kmp(s,t))
- 本题用kmp算法实现如下!!!
#KMP算法实现
def find(x):j=0for i in range(len(x)):while j!=0 and s[j]!=x[i]:j=p[j]if s[j]==x[i]:j=j+1if j==len(s):return 1return -1
s=input().strip()
m=int(input())
n=int(input())
if m==0:s=s.upper()
#计算kmp算法的next数组,这里我叫p
p=[0 for _ in range(len(s)+1)]
p[1]=0
j=0
for i in range(1,len(s)):while j != 0 and s[j] != s[i]:j = p[j]if s[j] == s[i]:j = j + 1p[i]=j
for i in range(n):x=input().strip()#枚举每一个母串,一次扫描if m==1:if find(x)!=-1:print(x)else:if find(x.upper())!=-1:print(x)总结
程序员节快乐!!!



![[SQL开发笔记]WHERE子句 : 用于提取满足指定条件的记录](https://img-blog.csdnimg.cn/112a932af7774594b42ad28bf2a85e78.png)