排查思路
如果执行 SQL 响应比较慢,我觉得可能有以下 4 个原因:
- 第 1 个原因:没有索引或者导致索引失效。
- 第 2 个原因:单表数据量数据过多,导致查询瓶颈
- 第 3 个原因:网络原因或者机器负载过高。
- 第 4 个原因:热点数据导致单点负载不均衡。
第 1 种情况
索引失效或者没有没有索引的情况。首先,可以打开 MySQL 的慢查询日志,收集一段时间的慢查询日志内容,然后找出耗时最长的 SQL 语句,对这些 SQL 语句进行分析
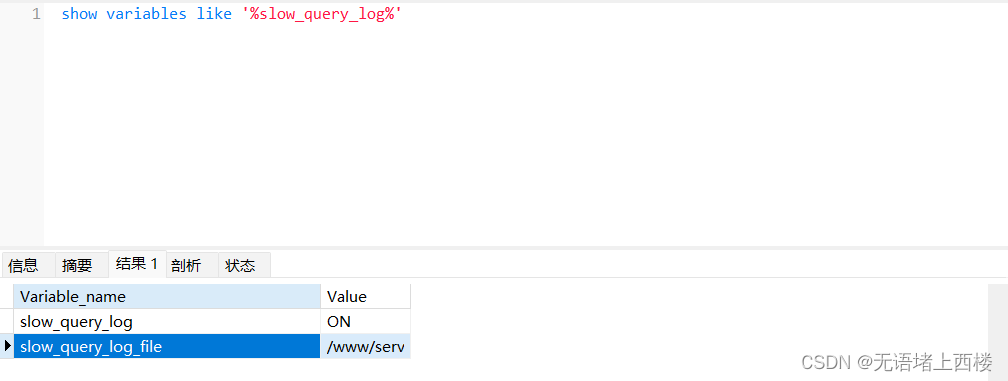
比如可以利用执行计划 explain 去查看 SQL 是否有命中索引。如果发现慢查询的 SQL 没有命中索引,可以尝试去优化这些 SQL 语句,保证 SQL 走索引执行。如果 SQL 结构没有办法优化的话,可以考虑在表上再添加对应的索引。我们在优化 SQL或者是添加索引的时候,都需要符合最左匹配原则。
第 2 种情况
单表数据量数据过多,导致查询瓶颈的情况。即使 SQL 语句走了索引,表现性能也不会特别好。这个时候我们需要考虑对表进行切分。表切分规则一般分为两种,一种是水平切分,一种是垂直切分。
- 水平切分的意思是把一张数据行数达到千万级别的大表,按照业务主键切分为多张小表,这些小表可能达到 100 张甚至 1000 张。
- 垂直切分的意思是,将一张单表中的多个列,按照业务逻辑把关联性比较大的列放到同一张表去。
除了这种分表之外,我们还可以分库。
比如我们已经拆分完 1000 表,然后,把后缀为 0-100 的表放到同一个数据库实例中,然后,100-200 的表放到另一个数据库实例中,依此类推把 1000 表存放到 10 个数据库实例中。这样的话,我们就可以根据业务主键把请求路由到不同数据库实例,从而让每一个数据库实例承担的流量比较小,达到提高数据库性能的目的。
第 3 种情况
网络原因或者机器负载过高的情况,我们可以进行读写分离。 比如 MySQL 支持一主多从的分布式部署,我们可以将主库只用来处理写数据的操作,而多个从库只用来 处理读操作。在流量比较大的场景中,可以增加从库来提高数据库的负载能力,从而提升数据库的总体性 能。
第 4 种情况
热点数据导致单点负载不均衡的情况。 这种情况下,除了对数据库本身的调整以外,还可以增加缓存。将查询比较频繁的热点数据预存到缓存当 中,比如 Redis、MongoDB、ES 等,以此来缓解数据的压力,从而提高数据库的响应速度。



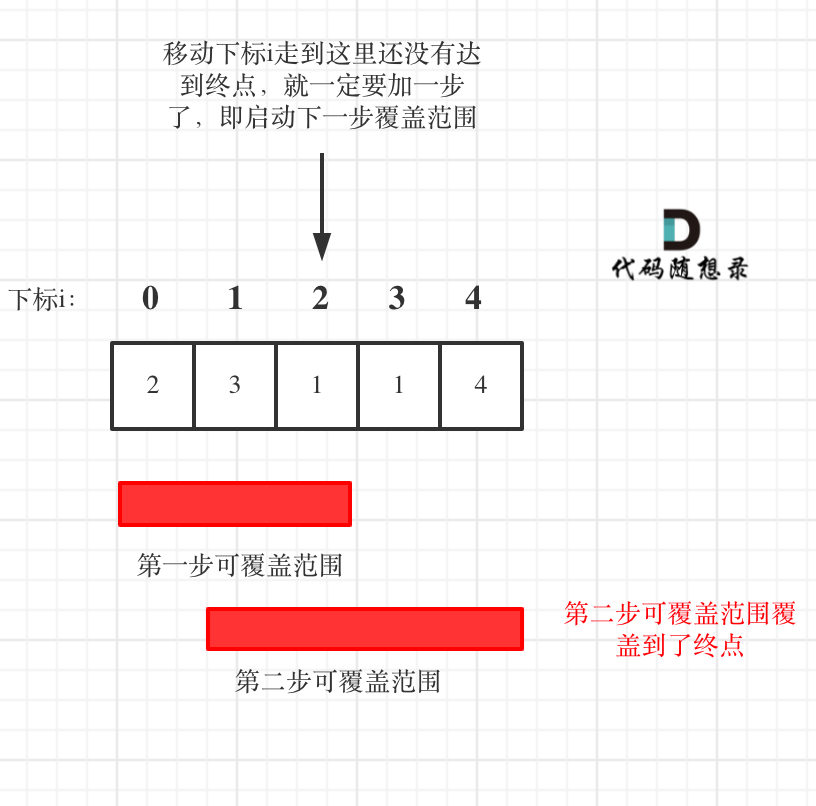

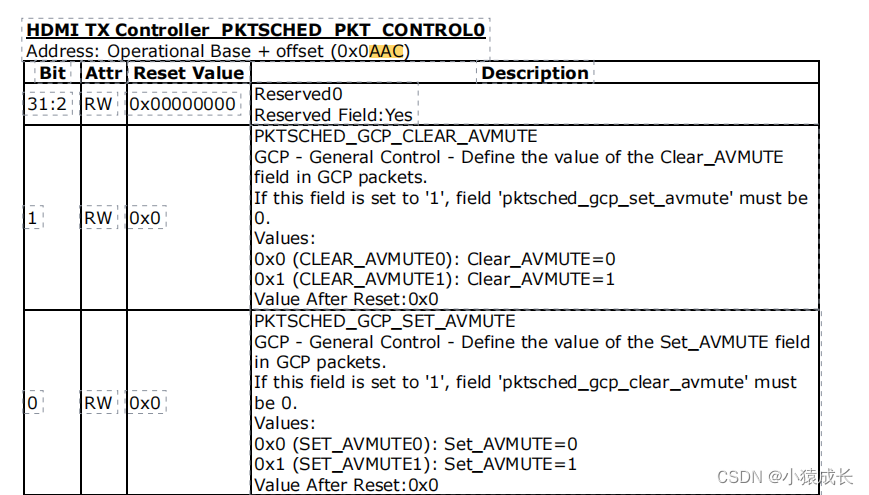
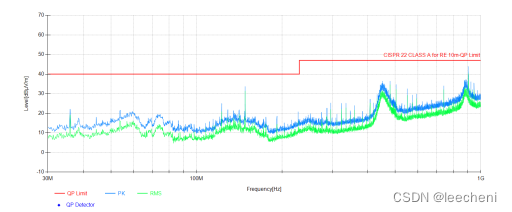
![分发糖果[困难]](https://img-blog.csdnimg.cn/4f3a1023a59b4d558fda9ca2f0bdb3c7.png)



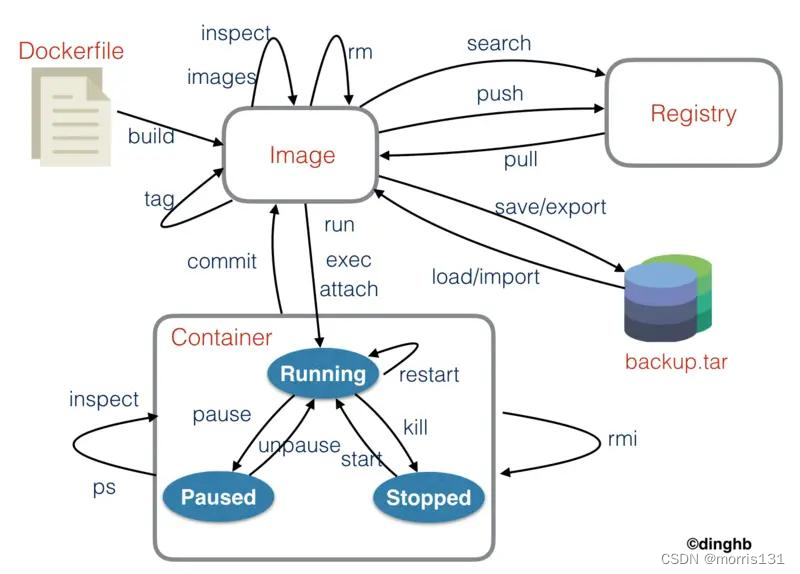
![NSS [NCTF 2018]滴!晨跑打卡](https://img-blog.csdnimg.cn/img_convert/286d674fc70a1a01087b499e5fb3e27e.png)