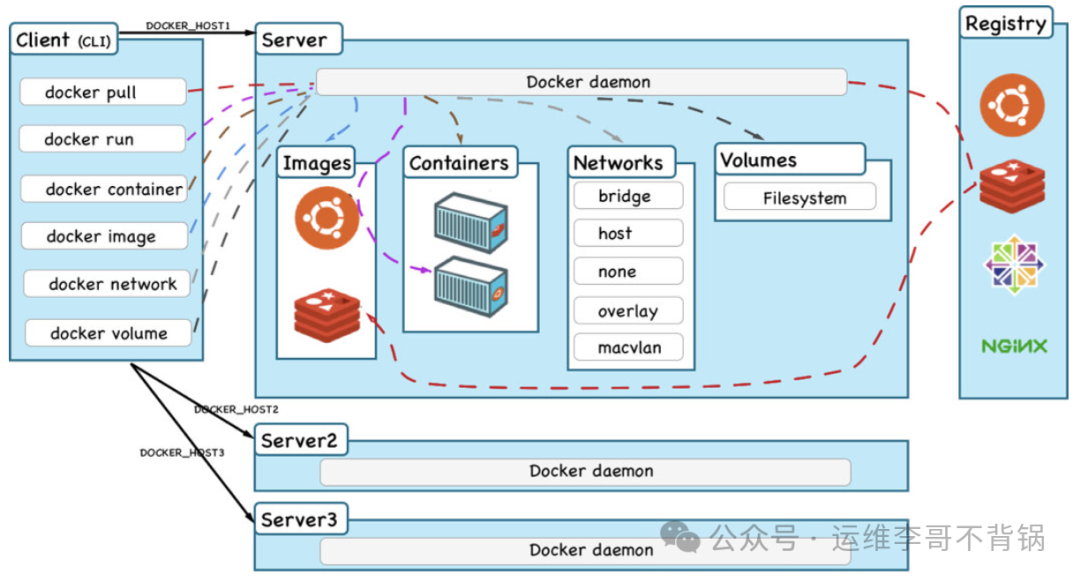
一、背景
在之前的内核调度子系统专栏里,我们已经把调度有关的如CFS调度/RT调度,调度时间片,调度时延,cfs唤醒抢占特性,这些基本概念和细节都讲了一遍。其实这些细节更多的是帮助我们理解调度系统是如何运作的,调度系统里的大部分参数其实我们都是不会去调整,或者说不敢去做大的调整的(除了cfs唤醒抢占特性从我个人角度在一些pub/sub模型比较多的系统上,我是觉得应该是调整关闭它的)。
这篇博客我们讲到的这个内核调度抢占模式,是我们可以去配置去做选择的,而且也是一个常见的选择配置。
我们在第二章里先讲一下桌面版linux默认的配置CONFIG_PREEMPT_VOLUNTARY,以及和CONFIG_PREEMPT的区别。然后我们在第三章里做一些实验来印证他们的差别。
在讲voluntary模式和full模式的区别之前,有必要提一下preempt_rt模式,这个模式是在打上rt-linux补丁以后默认选用的模式,这个模式要比full模式还要更加的重视实时性,如果要简单来概括一下为什么打上rt-linux补丁以后系统会更加实时,是因为rt-linux补丁让spinlock不再禁用抢占,另外,把中断都默认线程化,还默认开启了防优先级反转的rt-mutex开关,主要是这三个改动,让系统变得更加实时。详细细节会在后面的实时补丁相关的博文里展开。
二、普通linux内核默认的voluntary模式,和full模式的区别
在之前的 CFS及RT调度整体介绍_cfs rt 调度-CSDN博客 博客里已经讲到了时钟中断进来以后进行时间片检查判断等一系列逻辑,来决定是否需要进行上下文切换。
这里说的上下文切换,也就是抢占,即preempt。voluntary和full是普通内核抢占的两种主要的模式。
2.1 preempt模式(voluntary/full)的选择影响的只是内核态执行期间的行为
普通linux内核(非rt-linux)默认选用的是CONFIG_PREEMPT_VOLUNTARY的抢占模式:

CONFIG_PREEMPT_VOLUNTARY表示的是在一些自愿的可以允许抢占的点,可以被其他进程抢占。这里需要强调是,这些抢占选项都是在讨论内核态期间的抢占事情,用户态的代码在tick时钟中断进来以后,判断要进行抢占的话都是会立马进行抢占的,与这里的抢占选项是voluntary还是full无关。
2.2 关于禁用抢占
说到抢占,就得提到禁用抢占,一旦某个cpu禁用抢占,那么这个cpu上执行的线程就会继续执行,知道禁用抢占的行为被取消,cpu上才能发生线程切换。所以,一旦是禁用抢占状态,无论是哪种抢占模式,这个cpu都无法进行调度。
禁用抢占是一个只会在内核态发生的事情,用户态执行期间,是不会出现“禁用抢占”状态的。
为什么用户态代码执行期间会不会禁用了抢占,这个得从源头上来阐述,之所以要禁用抢占是用于在内核态代码执行关键逻辑期间不期望被打断执行,以免发生逻辑上因为嵌套和负载均衡迁移所导致的cpu变化等情况才禁用的抢占。
所以有两个基础的约定:
1)抢占的禁用得是非常短暂的,保护的是一个“原子的操作”;
2)禁用抢占所需要保护的行为是一个系统底层逻辑行为,与系统底层的数据结构相关,自然也得是在内核态执行,一旦退出了内核态回到用户态,也就脱离了这些底层的逻辑,也就自然不需要去禁用抢占了;
抢占的禁用是一个计数的累加,所有的禁抢占的计数在内核态回到用户态时都一定会清完成0。
2.2.1 哪些情况会出现禁用抢占
最最常见的就是spin_lock,另外,还有使用percpu变量时,tracepoint触发的逻辑里,线程销毁前的最后资源释放时等等。
2.3 voluntary模式在内核态期间只允许might_sleep的位置才可以发生线程切换
内核里除了might_sleep调用的位置,还有cond_resched调用的位置也可以发生线程切换,当然还有一些其他的类似的函数。
要注意,might_sleep这些调度点不能在禁用抢占期间调用。这也很好理解,我关了抢占,别人跑不了,我自己释放了给谁跑呢。
反过来说,如果voluntary模式下,在执行内核代码期间,如果tick进来以后判断出需要进行线程调度,也就是reschedule的标志位置上了,在时钟中断处理完退出时,这时候当前这个线程的内核态代码会继续执行,直到这个线程的内核代码执行完返回用户态,或者主动调用might_sleep/cond_resched,系统才会把它切换出去,换其他饥饿的线程来执行。
2.4 full模式在检查到需要进行调度后会里面进行线程切换,除非禁用了抢占
full模式的情况,在tick中断进来以后,检查到需要进行调度后,在该tick硬中断处理完成以后,如果这时候没有禁用抢占,则会立马进行线程切换,这一点会在 3.2 有例子验证。
对于有禁用抢占的情况,遇到tick中断进来,检查到需要进行调度后,会在抢占不再被禁用的那一刻进行线程切换,这一点会在 3.4 有例子验证。
三、voluntary模式和full模式的实验
这一章里会把在第二章里讲到的一些细节做一些实验验证。
通过抓perf record -g -C <cpu>来抓切换时刻的堆栈,
或通过cat /proc/<pid>/schedstat看线程的调度时延(关于如何通过系统方法或者一些定制的方法看调度时延可以参考之前的博客 调度时延的观测_csdn 调度时延的观测 杰克崔-CSDN博客)
这两个方式可以帮我们观测调度的情况,并了解内核里进行调度的时机。
如果是重编内核的方式,来使用voluntary模式还是full模式,是通过配置config里的下面两个互斥的config来配置
CONFIG_PREEMPT_VOLUNTARY=y
表示启用voluntary模式
CONFIG_PREEMPT=y
表示启用full模式
这里要注意,是CONFIG_PREEMPT而不是CONFIG_PREEMPTION,关于CONFIG_PREEMPTION在下面的例子里讲相关原理时会介绍
3.1 voluntary模式和full模式更便捷的切换方法——CONFIG_PREEMPT_DYNAMIC选项
如果打开了CONFIG_PREEMPT_DYNAMIC选项,voluntary模式和full模式可以不用编译内核进行切换,直接设置cmdline即可。
如下图,设置的是full模式:

关于preempt的dynamic的选项进行的动态切换逻辑,是在kernel/sched/core.c里的__setup("preempt=", setup_preempt_mode);根据传入的参数,在调用setup_preempt_mode时调用sched_dynamic_update进行模式选择的相关函数的准备。
如下图:


关于上图中的部分,有几个点需要介绍:
1)preempt_dynamic_enable和preempt_dynamic_disable两个宏是借助了内核里的static call机制,在下面 3.1.1 详细介绍,简单来说就是静态或者动态的修改函数指针实现高效的函数重新指向
2)cond_resched和might_resched仅仅在voluntary模式下才需要使用。为什么?因为preempt_none内核态完全不抢占当然不需要检查抢占,preempt_full则在需要抢占时立马执行了抢占,也不需要在cond_resched和might_resched里才去做抢占,这里面有禁用抢占场景的例子,见 3.4 一节
3)preempt_schedule仅仅在full模式下才需要使用。那么问题来了,preempt_voluntary怎么做的线程切换呢,preempt_voluntary模式线程切换时在直接调用的schedule函数,分为exit_to_user_mode_prepare(3.2 一节里有例子),或是might_sleep时调用的__cond_resched再到__schedule进行的线程切换(3.5 一节里有例子),或是下图中的schedule_idle再到__schedule进行的快进入idle时前的检查有任务要跑的线程切换,关于schedule_idle以及其他的与负载均衡有关的逻辑关注后面的博文。

关于按照编译选项进行preempt模式的初始化的逻辑:
默认初始化为undefined
![]()
这样在preempt_dynamic_init里就按照编译选项开关选择用那个mode调用sched_dynamic_update

sched_dynamic_update函数在上面已经有介绍
3.1.1 内核static call机制
单独用一节来讲这个机制,除了做介绍以外,更重要的是让大家知道内核里有这么一个机制,可以实现函数的重新指向,其目的是为了更高的性能:节省一个jmp命令,减少指令缓存的压力。
下面的截图是一个编译器的一个函数定义的选择,在内核里是能编过的,但是很明显,下面这些都是在编译器时确定的,而不能动态更新

如果要动态更新,得使用函数指针,并在函数更新时重新赋值函数指针,在真正做函数调用时,是通过一个跳板函数,再去跳真正要执行的函数,而static call这套机制就省去了这个jmp,而是直接跳到这个真正要执行的函数。更细的细节,这里并不展开。
说一下使用,在include/linux/static_call.h里:

在3.4.3.1 里有介绍preempt_schedule函数,里面有个__preempt_schedule宏如下定义:

这就是在调用该机制的函数时的一个例子
3.2 无论是voluntary模式还是full模式,若检查到需要进行调度,用户态代码都是会立马进行线程切换
针对这个case,我们基于voluntary模式,来进行测试:

下图的操作,先执行若干个deadloop程序,绑核到20上执行,再执行一个实时线程(下面有展示watch_rt.sh的脚本,脚本里面是chrt -r过这个启动的deadloop)并用watch去观测它的调度实验,下图为了展示更加方便,就直接用cat,隔10秒再cat来展示,调度时延没有明显增长。
关于watch_rt.sh的脚本如下:
#!/bin/bash# 检查传入的参数
if [ $# -eq 0 ]; thenecho "Usage: $0 <command> [args...]"exit 1
fi# 获取去掉 ./ 的命令名
command_name="${1#.*/}" # 去掉 ./ 或者任何前缀# 使用 pkill 杀死相应的进程
pkill "$command_name"# 执行程序并获取 PID
taskset -c 20 chrt -r 80 "$@" & # 以后台进程运行
pid=$! # 获取最后一个后台进程的 PID# 输出 PID
echo "Started process with PID: $pid"# 使用 watch 命令监控 /proc/<pid>/schedstat
watch -n 0.1 "cat /proc/$pid/schedstat"可以看到运行了很久,这个rt线程的调度延迟也是比较小的,而且不会随着时间明显增长

这种用户态时接收到tick硬中断进来,并进行调度时的堆栈情况,用perf sched record -g -C <cpu>可以抓到,如下图:

上图中可以看到,这种用户态代码运行期间进行线程切换时的堆栈,是在硬件tick中断进来处理完逻辑以后,exit_to_user_mode_prepare里进行schedule的。关于硬件tick中断进来以后具体做了哪些事,参考之前的 CFS及RT调度整体介绍_cfs rt 调度-CSDN博客 博客。
3.3 full模式下,内核代码执行期间,如果检查到需要进行调度,若没有禁用抢占,会立马进行线程切换
注意,这一节的标题里,有内核代码执行期间这个条件,对于用户态代码,在 3.2 一节中已经举例了。
这一节的操作省去了 3.2 一节里已经介绍的观测调度时延的操作步骤,这里只写抓出线程切换堆栈的步骤,来证明是否在内核态执行期间,检查到需要进行调度,会立马进行线程切换。
实验的步骤是先绑核运行几个死循环程序在核20上:
taskset -c 20 ./deadloop &
然后写一个insmod的ko,内核执行的代码如下:
下面就是执行一段持续10秒的死循环,循环里啥也不做
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/sched.h>
#include <linux/spinlock.h>
#include <linux/delay.h>
#include <linux/jiffies.h>MODULE_LICENSE("GPL");
MODULE_AUTHOR("zhaoxin");
MODULE_DESCRIPTION("A simple Linux kernel module using spinlock running 10 second.");
MODULE_VERSION("1.0");static DEFINE_SPINLOCK(my_spinlock);static int __init testspinlock_init(void) {unsigned long flags;unsigned long start_time, end_time, start1, end1;int index = 0;printk(KERN_INFO "testspinlock: Module loaded.\n");printk(KERN_INFO "testspinlock: Spinlock enter/quit running for 10 second...\n");// 获取当前时间start_time = jiffies;// 死循环,直到时间超过 10 秒while (time_before(jiffies, start_time + HZ * 10)) {// 空循环等待//spin_lock(&my_spinlock);start1 = jiffies;//printk("run index[%d]\n", index);index++;//while (time_before(jiffies, start1 + HZ * 5)) {//}}printk(KERN_INFO "testspinlock: Spinlock released.\n");return 0;
}static void __exit testspinlock_exit(void) {printk(KERN_INFO "testspinlock: Module unloaded.\n");
}module_init(testspinlock_init);
module_exit(testspinlock_exit);make出testspinlock_times.ko
然后,先执行下面的命令抓取20核上的调度行为及其调度行为时的堆栈
perf sched record -g -C 20另起一个窗口,通过绑核insmod来执行上面这段循环10秒的内核代码
taskset -c 20 insmod testspinlock_times.ko
这个ko里的这个持续10秒的逻辑就会和该20核上的另外几个刚起的deadloop进程抢20核上的cpu资源去执行。
几秒以后,ctrl+C停止perf sched record -g -C 20的命令执行,输入下面的命令解析出调度行为相关的堆栈
perf script > script.txt查看script.txt文件,就可以看到下面的截图

解释一下上图里的内容,可以看到insmod的这个20核上的进程,在full模式下,发现需要进行调度后,是立马进行了线程切换,可以看到线程切换时insmod线程的prev_state是R+的,并没有主动释放cpu时就被切换走了,切换的时刻是在x86上的timer的tick中断进来的
asm_sysvec_apic_timer_interrupt中断处理函数里到硬中断处理完时,检查打断前是用户态还是内核态,如果是内核态,就会执行到下面的irqentry_exit_cond_resched逻辑:

CONFIG_PREEMPTION一般都是打开的,而irqentry_exit_cond_resched在 3.1 一节中有过介绍,在CONFIG_PREEMPT_VOLUNTARY时是会被定义成空函数,而在CONFIG_PREEMPT_FULL时才会被定义成,如下图:

![]()
![]()
raw_irqentry_exit_cond_resched的实现如下:

最后调用到了上面perf sched record -g抓到的这个preempt_sched_irq函数里
3.4 full模式下,spinlock一旦unlock时就会检查reschedule标志并进行按需调度
上面已经证明了在内核态执行期间,检查到需要调度,会在tick中断处理完以后进行线程切换。
但是,如果这时候在内核态代码里使用了spinlock且还是在spinlock禁用抢占保护期间内呢,full模式是在后面什么时候进行的调度呢?——答案是在spin_unlock时也就是禁用抢占的count清零时,就会进行调度
内核代码如下,也增加了might_sleep,我们预期在full模式下,这个might_sleep没有作用:

直接上抓到的堆栈:

可以从perf script导出的文件里去搜__cond_resched是搜不到,关于__cond_resched在3.5一节中有例子介绍,搜不到__cond_resched,和预期的一致,就是full模式并不需要这个__cond_resched的逻辑,见 3.1 一节

为了再次确保,把might_sleep在spin_lock执行前也放一个:
内核代码:

依然搜不到__cond_resched

我们再研究一下这个spin_unlock到preempt_schedule的调用栈,理一下代码逻辑,再贴一下刚贴过的这个调用栈:
看到是_raw_spin_unlock->preempt_schedule_thunk->preempt_schedule
3.4.1 关于spin_lock和spin_unlock
先看一下spin_lock加锁的时候
spin_lock的代码在普通内核里直接定义成了

而raw_spin_lock定义成了_raw_spin_lock
![]()
而_raw_spin_lock调用到了__raw_spin_lock

__raw_spin_lock的实现:

再回到正题,看解锁的时候:
spin_unlock调用了raw_spin_unlock再定义成了_raw_spin_unlock再调用了__raw_spin_unlock

![]()

这么跟代码有时候会比较难受,因为会存在多个定义,另外,很多时候因为有inline函数以及编译器的优化,导致代码一级级很难轻松找到,所以我们顺便讲一下通过objdump -S解析出带源文件和汇编对应关系的文件,来看就会好定位很多
3.4.2 通过objdump -S导出到文件,再找调用链
objdump -S vmlinx > vmlinux.txt
注意这个vmlinx不是vmlinz,不能压缩,要用编出来的原始的大的文件来objdump
我们看vmlinux.txt里,搜索函数的方式:
/_raw_spin_unlock>:
注意要加上>:这两个符号,可以准确定位到函数的定义的位置。
怎么来看这个文件呢?
通过通过下图中的0x2d

找到_raw_spin_unlock的起始的0xffffffff81f05780的位置加上2d也就是0xffffffff81f057ad

0xffffffff81f057ad的上一条也就是下图红色框

3.4.3 通过正向的vmlinux解析出来的文件和反向的堆栈看到的preempt_schedule_thunk往前推,找到了最终的_raw_spin_unlock到preempt_schedule_thunk的调用链
spin_unlock
->raw_spin_unlock
即_raw_spin_unlock
->__raw_spin_unlock
->preempt_enable
->preempt_count_dec_and_test
->__preempt_schedule
include/linux/preempt.h下有
preempt_enable的定义:

但是从__preempt_schedule到preempt_schedule_thunk还有一些细节
3.4.3.1 关于preempt_schedule函数
我们在代码里可以搜到preempt_schedule的export_symbol如下:

从__preempt_schedule到preempt_schedule_thunk还有一些细节,
__preempt_schedule是在x86里被定义成了下面

关于 STATIC_CALL_TRAMP_STR 就是内核static call机制,见 3.1.1
所以__preempt_schedule宏是去找preempt_schedule实际对应的函数,如下:

而preempt_schedule_dynamic_enabled在preempt.h里定义如下:

而preempt_schedule在full模式下会被定义成preempt_schedule_thunk

关于preempt_schedule_thunk是preempt_schedule的封装,相关的注释如下:

代码上,其实就是做一些额外的工作后再调用preempt_schedule


3.5 voluntary模式下,未禁用抢占时,might_sleep抢占点可以进行线程切换
和之前的几节的例子差不多,先通过./watch_rt ./deadloop来看调度时延是否和理论的一致
下图中的操作是先执行中间的perf sched record -g -C 20的操作抓20核上调度相关事件,再绑核20进行insmod执行加了might_sleep逻辑的内核代码(这个内核代码持续10秒),然后马上执行左边的./watch_rt.sh ./deadloop_50(deadloop_50是一半时间死循环,避免rt的95%时间的超限导致的调度时延增加),可以看到最后insmod退出后,看这个rt的deadloop_50的调度时延也并没有明显变大。

上面执行的内核代码在每个循环内部的spin_lock和spin_unlock之后增加might_sleep逻辑:

这期间抓的perf下图中可以看到在insmod时调用的might_sleep最后调用的是__cond_resched再调用__schedule进行的调度