星光下的赶路人star的个人主页
大鹏一日同风起,扶摇直上九万里
文章目录
- 1、Spark
- 1.1 Spark入门
- 1.1.1 Spark部署模式
- 1.1.2 常用端口
- 1.2 SparkCore
- 1.2.1 RDD不可变和五大属性
- 1.2.2 RDD的弹性
- 1.2.3 cache和Checkpoint的区别
- 1.2.4 算子
- 1.3 SparkSQL
- 1.4 内核
- 1.4.1提交流程(YarnCluster)
- 1.4.2 SortShuffle
1、Spark
1.1 Spark入门
1.1.1 Spark部署模式
1、Standalone模式:spark自己管理资源
2、yarn模式:yarn来管资源
- Client模式:Driver(线程)在client里
- Cluster模式:Driver(线程)在AM里
3、mesos模式:国外用的
4、k8s模式:未来趋势
1.1.2 常用端口
4040 运行时端口
7070 内部通讯端口
18080 历史服务器
1.2 SparkCore
1.2.1 RDD不可变和五大属性
五大属性:分区、分区器、计算逻辑、最优位置、血缘关系。
1.2.2 RDD的弹性
储存:内存和磁盘·
容错:cache、persist
计算:重试
位置:task、数据不在一起
1.2.3 cache和Checkpoint的区别
cache:不会切断血缘
Checkpoint:会切断血缘
1.2.4 算子
1、单value
map
fliter
flatMap
mapPartition:一次处理一个分区的数据
groupBy
repartition:扩大分区,一定会shuffle
coalesce:减少分区:不一定会shuffle
2、双Value
union
zip
交集
差集
3、k-v
groupby:重分区,shuffle,不做聚合
ReduceBy:重分区,shuffle,做预聚合
sortbykey
大部分xxxbykey的算子会导致shuffle
4、行动算子
foreach
take
collect
Reduce
first
5、血缘关系
宽依赖:有shuffle,一对多:父rdd的一个分区发往子rdd多个分区
窄依赖:没有shuffle,一对一,父rdd的一个分区发往子rdd的一个分区
6、Application划分
Application:SparkContext的数量
job:行动算子的数量
stage:宽依赖的数量+1
task:一个stage中task的数量=最后一个rdd的分区数量
7、共享变量
广播变量
累加器
1.3 SparkSQL
1、数据抽象
rdd
DataFrame
DataSet
2、hive on spark vs spark on hive
hive on spark: 写 hivesql, 解析、编译、优化都是 hive的,只有执行是spark
spark on hive: 写sparksql,解析、编译、优化、执行都是spark的,只用到了hive的元数据
hive on spark的优点:图方便, hive on spark,写hivesql就行了,学习成本低,好维护
spark on hive的优点:更灵活, spark on hive,写sparksql,需要一定的spark代码功底
1.4 内核
1.4.1提交流程(YarnCluster)

1、先执行启动命令,然后会看到一个SparkSubmit进程,这个进程首先是解析参数、再创建YarnClusterApplication客户端,然后由客户端封装提交参数和命令,再向ResourceManager提交任务信息
2、由ResourceManager启动ApplicationMaster
3、AM根据参数,启动Driver线程并初始化SparkContext
4、向ResourceManager注册AM,申请资源
5、由ResourceManager向AM返回资源可用列表
6、启动launcherPool,利用RPC模块启动Executor
7、然后再向Driver注册Executor
8、Driver告知注册成功
9、创建Executor计算对象
10、再由Driver进行任务切分
11、再由Driver分配任务
1.4.2 SortShuffle
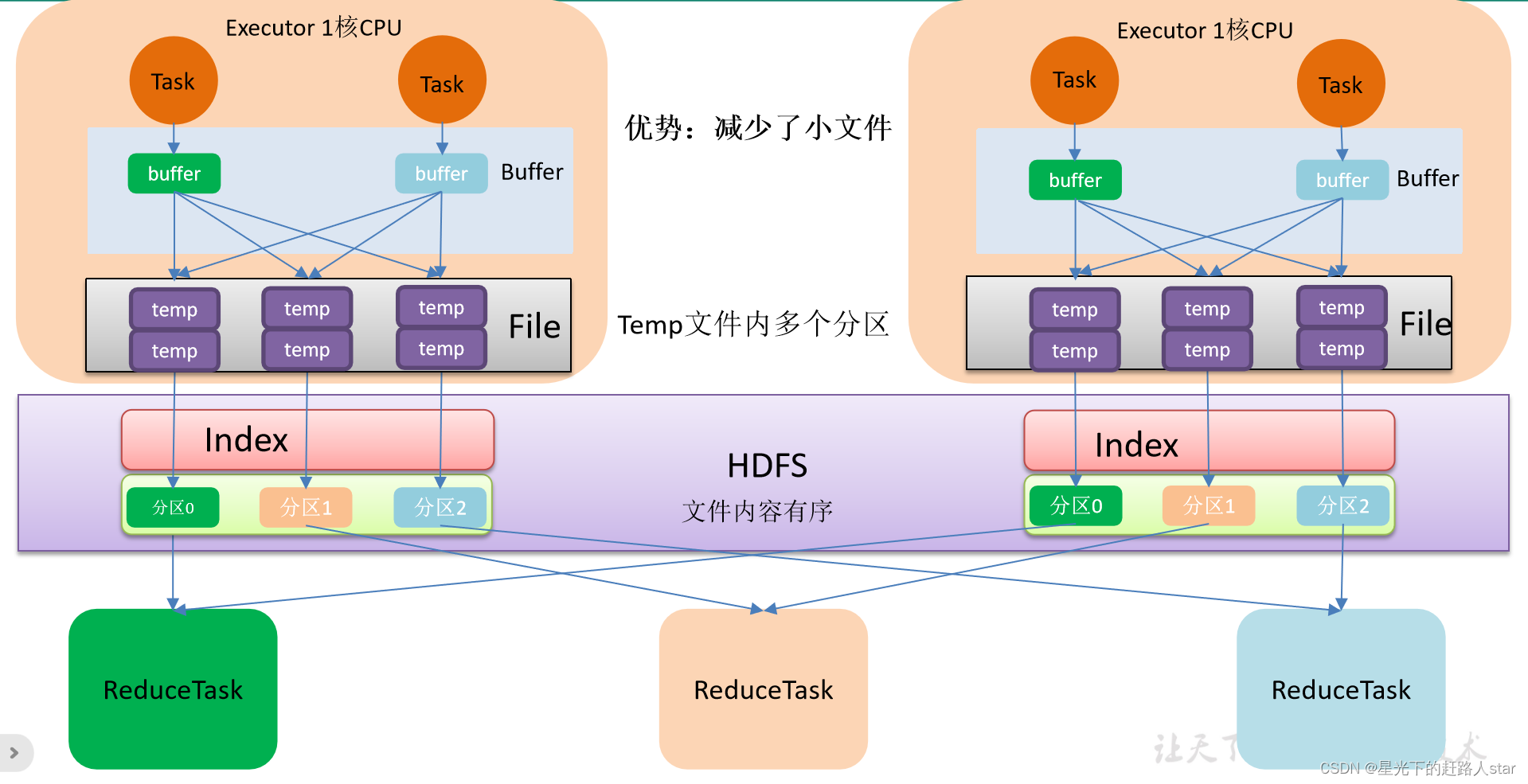
1、在该模式下,数据会先写入到一个数据结构,ReduceByKey写入Map,一边通过Map局部聚合,一边写入内存。Join算子写入ArrayList直接写入内存。然后需要判断是否达到阙值,如果达到就会将内存数据结构的数据写入到磁盘,清空内存数据结构。
2、在溢写磁盘时,先根据key进行排序,排序过后的数据,会分批写入到磁盘文件中,默认批次为10000条,数据会以此每批一万条写入到磁盘文件中。写入磁盘文件通过缓冲区溢写的方式,每次溢写都会产生一个磁盘文件,也就是每个task过程中会产生多个临时文件
3、最后在每个task中,将所有的临时文件合并,这就是merge过程,此过程将所有的临时文件读取出来,一次写入到最终文件。意味着一个task的所有数据都在这一个文件中。同时单独写一份索引文件,标识下游各个task的数据在文件中的索,start offset和end offset。
![]()
您的支持是我创作的无限动力
![]()
希望我能为您的未来尽绵薄之力
![]()
如有错误,谢谢指正;若有收获,谢谢赞美