机器学习 第七课 随机森林
- 概述
- 机器学习
- 机器学习的主要分类
- 监督学习
- 无监督学习
- 强化学习
- 集成学习
- 提高准确性
- 增强稳定性
- 提升泛化能力
- 集成学习的主要方法
- Bagging
- Boosting
- Stacking
- 随机森林的理论基础
- 决策树的基本原理
- 随机森林的生成过程
- 随机森林的优势与局限性
- 随机森林的实际应用
- 通过 sklearn 调用随机森林算法
- 分类问题
- 回归问题
- 特征重要性
- 如何计算特征
- 解释特征重要性
概述
机器学习 (Machine Learning), 作为人工智能的一个重要分支, 近年来已经成为近期热门和活跃的方向之一. 机器学习通过数据中学习, 并利用这些学习到的知识进行决策和预测.

随着数据量的激增和计算能力的提升, 单一模型往往难以满足复杂任务的需求, 集成学习 (Ensemble Learning) 应运而生. 集成学习通过组合多个模型, 来提高预测准确性和模型稳定性. 集成学习的基本思想是 “三个臭皮匠, 顶个诸葛亮”, 通过将多个弱学习器组合成一个强学习器, 从而达到提升模型性能的目的.
机器学习
机器学习的主要分类
机器学习根据学习任务的性质和学习过程的机制, 可以分为三大类: 监督学习 (Supervised Learning), 无监督学习 (Unsupervised Learning) 和强化学习 (Reinforcement Learning).
监督学习
监督学习 (Supervised Learning) 是常见的机器学习类型, 特点是学习过程中提供了输入和对应的输出标签. 算法的目标是学习一个映射关系, 使得对于新的输入, 能够准确预测其输出. 常见的监督学习任务包括分类和回归.
无监督学习
与监督学习 (Supervised Learning), 无监督学习 (Unsupervised Learning) 的数据中没有标签信息. 算法需要自行发现数据中的结构和规律. 常见的无监督学习任务包括聚类, 降为和密度估计.
强化学习
强化学习关注的是智能体如何在环境中采取行动, 以最大化某种累积奖励. 而是通过与环境的交互来学习最优策略.
集成学习
集成学习 (Ensemble Learning) 是一种机器学习的范式, 通过结合多个学习器来完成学习任务.

提高准确性
单个模型可能因为过拟合, 欠拟合或者数据噪声而导致预测不准确, 而集成多个模型可以显著提高预测的准确性.
增强稳定性
不同的模型对数据的不同特征有不同的响应, 集成学习能够减少模型对特定数据特征的依赖, 从而增强模型的稳定性.
提升泛化能力
集成学习通过综合多个模型的预测结果, 能够提升模型对未见数据的泛化能力.
集成学习的主要方法
集成学习 (Ensemble Learning) 的方法主要有三类:
- Bagging
- Boosting
- Stacking
Bagging
Bagging, 全称 Bootstrap Aggregating, 是一种通过减少模型方差来提升模型性能的集成学习方法. Bagging 的核心思想是通过对原始数据集进行多次有放回抽样, 构成多个不同的子数据集. 然后在这些子数据集上分别训练多个相同类型的模型. 最终, 通过对这些模型的预测结果进行平均 (回归 Regression) 或投票 (分类 Classification) 得到最终的预测结果.
优点:
- 减少过拟合 (Over Fitting): 由于每个模型在不同的数据子集上训练的, 因此 Bagging 对数据的特定噪声和异常的敏感性降低, 从减少了过拟合的风险
- 提升模型稳定性: 每个模型可能因为训练数据的微小变化而产生较大的预测变化, 而 Bagging 通过平均多个模型的预测的预测结果, 提升了模型的稳定性
缺点:
- 计算成本较高: 需要训练多个模型, 因此计算成本较高
- 模型间互相独立: Bagging 方法假设各个模型相互独立, 但在实际应用中这一假设往往不成立
Boosting
Boosting 是一种将多个弱学习组合成强学习的集成学习方法. 与 Bagging 不同, Boosting 关注于提升模型的偏差. Boosting 通过迭代地训练一系列模型, 每个模型都试图纠正前一个模型的错误. 新模型的训练数据的权重会根据前一个模型的预测性能进行调整, 错误预测的数据会获得更高的权重.
优点:
- 提升模型性能: Boosting 能够将一系列性能较差的模型组合成一个性能优秀的模型
- 灵活性高: Boosting 可以与不同类型的学习方法一起使用
缺点:
- 容易过拟合: Boosting 对噪声和异常非常敏感, 容易过拟合
- 计算成本较高: 需要迭代训练多个模型, 计算成本较高
Stacking
Stacking 是一种将多个不同的基模型组合起来的集成学习方法. Stacking 通过训练一个元模型来组合多个基模型的预测结果. 元模型的输入是基模型的输出, 输出是最终的预测结果.
优点:
- 提升模型性能: 通过组合不同的模型, Stacking 能够提升模型的性能
- 灵活性高: 可以使用不同类型的模型作为基模型和元模型
缺点:
- 模型复杂度搞: Stacking 模型的复杂度较高, 需要调整的参数较多
- 计算成本高: 需要训练多个模型和一个元模型, 计算成本较高
随机森林的理论基础
随机森林 (Random Forest) 是一种基于决策树的集成学习方法. 随机森林结合了 Bagging 算法和随机特征选择的策略来构建一组决策树, 并通过投票或平均的方式来进行预测. 随机森林属于一种 Bagging 算法.
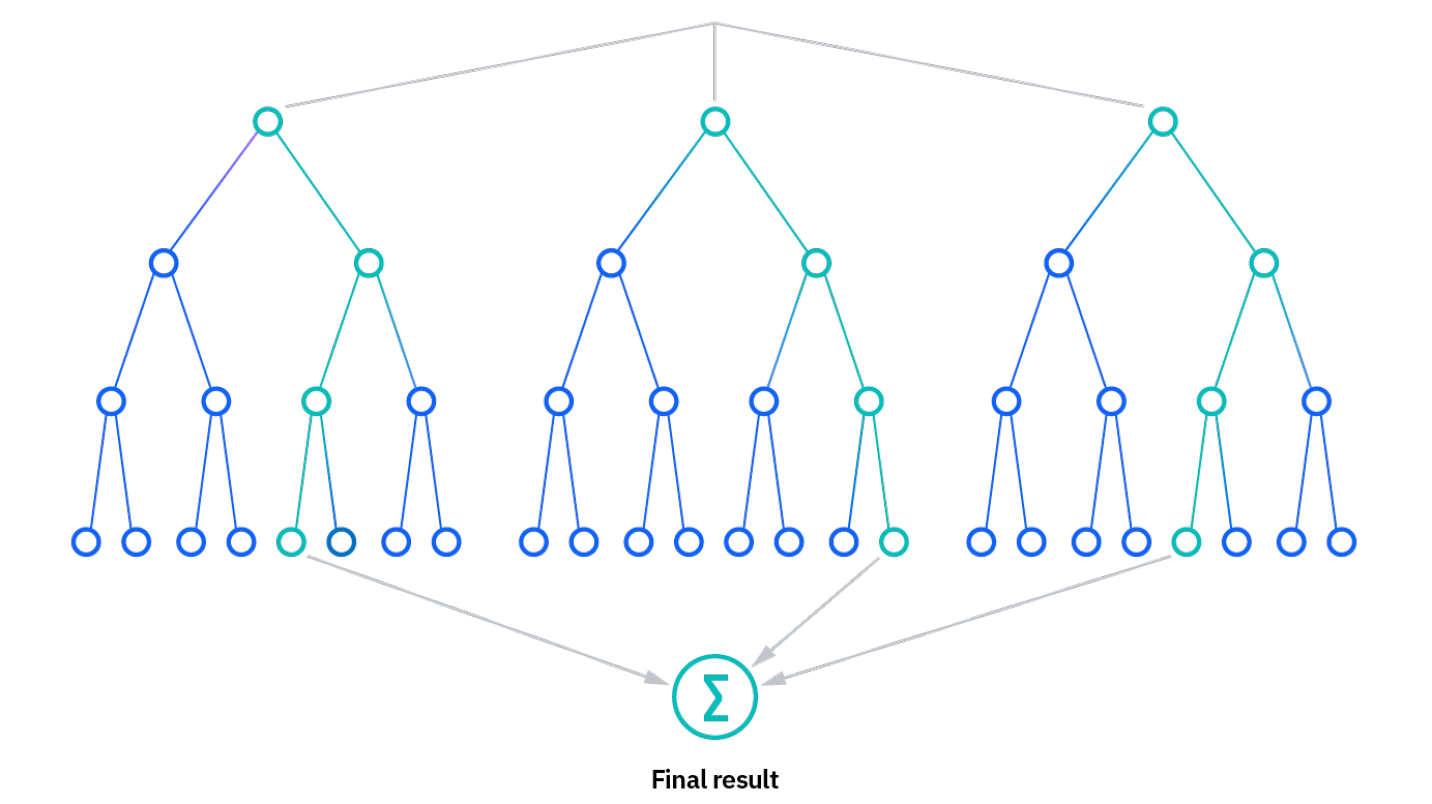
决策树的基本原理
决策树是一种树形结构的模型, 通过一系列的判断规则来进行预测. 一个决策树包括根节点, 内部节点, 叶节点和边. 每个内部节点代表一个特征或属性, 每个边代表一个决策规则, 每个叶节点代表最终的预测结果.
决策树的构建过程包括特征选择, 树的生成和剪枝. 特征选择目标是选出最优的划分特征, 常用的方法有信息增益, 增益率和基尼指数等. 树的生成是通过递归的方式来构建决策树.
随机森林的生成过程
在生成随机森林 (Random Forest) 的过程中, 首先对原始数据集进行有放回的随机抽样, 生成多个不同的训练数据集.
对于每个训练数据集, 随机森林独特地构建一个决策树. 在每个决策树构建的过程中, 随机森林引入随机特征选择的策略, 即在每次划分节点时, 不是从所有特征中选择最优特征, 而是从一个随机选择的特征子集中选择最优特征.
随机森林的预测过程包括对每个决策树进行预测, 然后通过投票 (分类问题) 或者平均 (回归问题) 的方式来综合这些预测结果, 得到最终的预测结果.
随机森林的优势与局限性
优势:
- 提高准确率: 随机森林能够大佬很高的准确率, 并且能够有效地运行在大数据上
- 防止过拟合: 通过多个决策树并行进行投片或平均, 减少过拟合的风险
- 能够处理高危数据: 随机森林能够处理大量的特征, 并且不需要进行特征选择
- 提供特征重要性评估: 随机森林能够评估各个特征在预测中的重要性
局限性:
- 模型解释性差:由于随机森林是由多个决策树组成的, 因此它的模型解释性不如单个决策树
- 训练时间较长: 随机森林需要构建多个决策树, 因此训练时间可能会比单个决策树长
随机森林的实际应用
随机森林在各个领域都有广泛的应用. 接下来我们通过两个实际案例来探讨随机森林在分类和回归方面的应用.
通过 sklearn 调用随机森林算法
格式:
sklearn.ensemble.RandomForestClassifier(n_estimators=100,*,criterion="gini",max_depth=None,min_samples_split=2,min_samples_leaf=1,min_weight_fraction_leaf=0.0,max_features="auto",max_leaf_nodes=None,min_impurity_decrease=0.0,bootstrap=True,oob_score=False,n_jobs=None,random_state=None,verbose=0,warm_start=False,class_weight=None,ccp_alpha=0.0,max_samples=None,
)
参数:
- n_estimators: 森林中树的数量, 默认为 100
- criterion: 分裂质量的函数, 默认为 “gini” 基尼
- max_depth: 树最大深度, 默认为 None
- min_smaples_split: 分裂内部节点所需的最小样本数, 默认为 2
- min_samples_leaf: 在叶节点出需要的最小样本数, 默认为 1
- max_features: 最佳分割时要考虑的特征数量, 默认 “auto”
- random_state: 随机数种子
# 导包
from sklearn.ensemble import RandomForestClassifier# 实例化模型
rf_clf = RandomForestClassifier()
分类问题
鸢尾花分类
代码:
"""
@Module Name: 随机森林 鸢尾花.py
@Author: CSDN@我是小白呀
@Date: October 24, 2023Description:
随机森林 鸢尾花
"""
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report# 加载数据
iris = load_iris()
X, y = iris.data, iris.target# 分割训数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 实例化模型
rf_clf = RandomForestClassifier(random_state=42)# 拟合模型
rf_clf.fit(X_train, y_train)# 预测
y_pred = rf_clf.predict(X_test)# 模型评估
report = classification_report(y_test, y_pred)
print(report)# 特征重要性
feature_importance = rf_clf.feature_importances_
print(feature_importance)
输出结果:
precision recall f1-score support0 1.00 1.00 1.00 101 1.00 1.00 1.00 92 1.00 1.00 1.00 11accuracy 1.00 30macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30[0.10809762 0.03038681 0.43999397 0.42152159]
回归问题
波士顿房价预测:
"""
@Module Name: 随机森林 波士顿房价.py
@Author: CSDN@我是小白呀
@Date: October 245, 2023Description:
随机森林 波士顿房价
"""
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# 加载数据
boston = load_boston()
X, y = boston.data, boston.target# 分割训数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 实例化模型
rf_clf = RandomForestRegressor(random_state=42)# 拟合模型
rf_clf.fit(X_train, y_train)# 预测
y_pred = rf_clf.predict(X_test)# 模型评估
MSE = mean_squared_error(y_test, y_pred)
print("MSE:", MSE)# 特征重要性
feature_importance = rf_clf.feature_importances_
print(feature_importance)
输出结果:
MSE: 7.901513892156864
[0.03806177 0.00175615 0.00795268 0.00100426 0.01554377 0.503844930.01383994 0.06054907 0.00381091 0.01566064 0.01631341 0.012153620.30950883]
特征重要性
feature_importances_代表模型特征重要性. 在我们拟合RandomForestClassifier或RadomForestRegressor模型之后使用. feature_importances_可以帮助我们了解每个特征对模型预测的贡献度, 即特征的重要性.
如何计算特征
随机森林 (Random Forest) 中的特征重要性是通过观察每颗树中的每个特征分裂点带来的纯度增益来计算的. 具体步骤:
- 对于森林中的每棵树, 计算每个特征的纯度增益总和
- 将这个总和除以森林中所有数的数量,
- 将这些平均值标准化, 使他们的总和为 1, 这样你就得到了每个特征的重要性得分
解释特征重要性
feature_importance_会返回一个数组, 包含每个特征的重要性得分. 数组长度等于输入数据的特征数量. 每个得分都是一个介于 0 和 1 之间的数组, 所有得分的总和为 1.
高分 vs 低分
- 高分: 如果一个特征的重要性得分很高, 这意味着这个特征对模型的预测非常有帮助
- 低分: 如果一个特征的重要性得分很低, 意味着这个特征对模型的预测贡献不大, 或者特征信息已经被其他特征所捕获
例子:
from sklearn.ensemble import RandomForestClassifier# 假设 X 是特征矩阵,y 是标签
clf = RandomForestClassifier()
clf.fit(X, y)# 获取特征重要性
importances = clf.feature_importances_# 打印特征重要性
for i, imp in enumerate(importances):print(f"Feature {i}: {imp}")